 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
Dec 31, 2025Agentic crafting requires LLMs to operate in real-world environments over multiple turns by taking actions, observing outcomes, and iteratively refining artifacts. Despite its importance, the open-source community lacks a principled, end-to-end ecosystem to streamline agent development. We introduce the Agentic Learning Ecosystem (ALE), a foundational infrastructure that optimizes the production pipeline for agent LLMs. ALE consists of three components: ROLL, a post-training framework for weight optimization; ROCK, a sandbox environment manager for trajectory generation; and iFlow CLI, an agent framework for efficient context engineering. We release ROME (ROME is Obviously an Agentic Model), an open-source agent grounded by ALE and trained on over one million trajectories. Our approach includes data composition protocols for synthesizing complex behaviors and a novel policy optimization algorithm, Interaction-based Policy Alignment (IPA), which assigns credit over semantic interaction chunks rather than individual tokens to improve long-horizon training stability. Empirically, we evaluate ROME within a structured setting and introduce Terminal Bench Pro, a benchmark with improved scale and contamination control. ROME demonstrates strong performance across benchmarks like SWE-bench Verified and Terminal Bench, proving the effectiveness of the ALE infrastructure.
InquireMobile: Teaching VLM-based Mobile Agent to Request Human Assistance via Reinforcement Fine-Tuning
Aug 27, 2025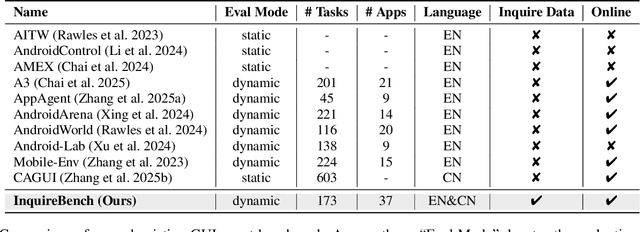
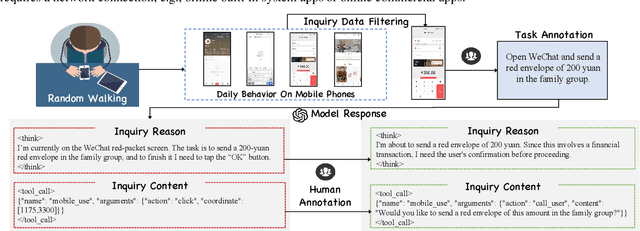
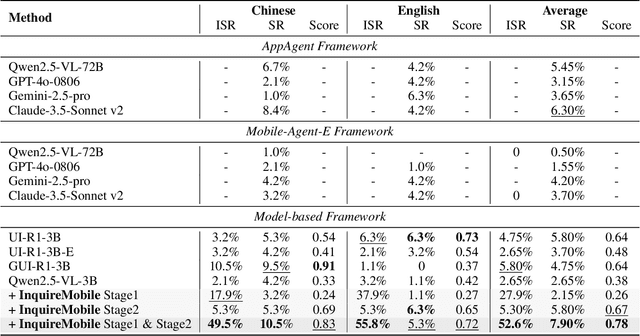
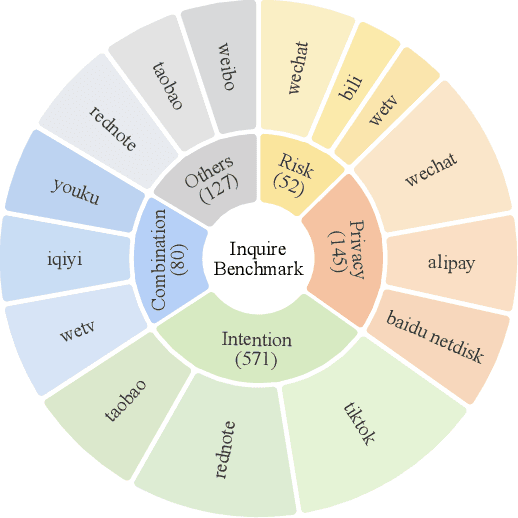
Recent advances in Vision-Language Models (VLMs) have enabled mobile agents to perceive and interact with real-world mobile environments based on human instructions. However, the current fully autonomous paradigm poses potential safety risks when model understanding or reasoning capabilities are insufficient. To address this challenge, we first introduce \textbf{InquireBench}, a comprehensive benchmark specifically designed to evaluate mobile agents' capabilities in safe interaction and proactive inquiry with users, encompassing 5 categories and 22 sub-categories, where most existing VLM-based agents demonstrate near-zero performance. In this paper, we aim to develop an interactive system that actively seeks human confirmation at critical decision points. To achieve this, we propose \textbf{InquireMobile}, a novel model inspired by reinforcement learning, featuring a two-stage training strategy and an interactive pre-action reasoning mechanism. Finally, our model achieves an 46.8% improvement in inquiry success rate and the best overall success rate among existing baselines on InquireBench. We will open-source all datasets, models, and evaluation codes to facilitate development in both academia and industry.
ChineseSimpleVQA -- "See the World, Discover Knowledge": A Chinese Factuality Evaluation for Large Vision Language Models
Feb 19, 2025The evaluation of factual accuracy in large vision language models (LVLMs) has lagged behind their rapid development, making it challenging to fully reflect these models' knowledge capacity and reliability. In this paper, we introduce the first factuality-based visual question-answering benchmark in Chinese, named ChineseSimpleVQA, aimed at assessing the visual factuality of LVLMs across 8 major topics and 56 subtopics. The key features of this benchmark include a focus on the Chinese language, diverse knowledge types, a multi-hop question construction, high-quality data, static consistency, and easy-to-evaluate through short answers. Moreover, we contribute a rigorous data construction pipeline and decouple the visual factuality into two parts: seeing the world (i.e., object recognition) and discovering knowledge. This decoupling allows us to analyze the capability boundaries and execution mechanisms of LVLMs. Subsequently, we evaluate 34 advanced open-source and closed-source models, revealing critical performance gaps within this field.
Chinese SimpleQA: A Chinese Factuality Evaluation for Large Language Models
Nov 13, 2024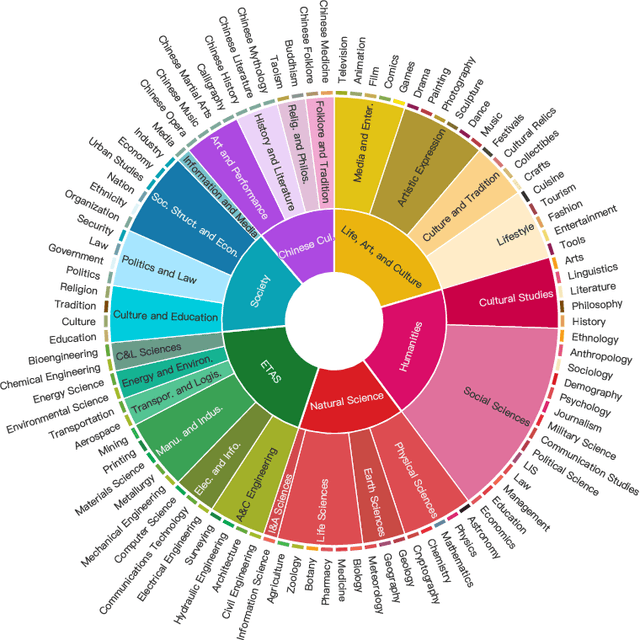


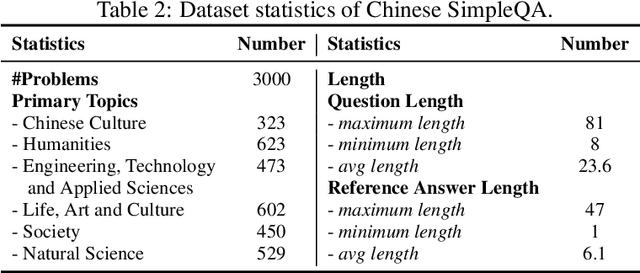
New LLM evaluation benchmarks are important to align with the rapid development of Large Language Models (LLMs). In this work, we present Chinese SimpleQA, the first comprehensive Chinese benchmark to evaluate the factuality ability of language models to answer short questions, and Chinese SimpleQA mainly has five properties (i.e., Chinese, Diverse, High-quality, Static, Easy-to-evaluate). Specifically, first, we focus on the Chinese language over 6 major topics with 99 diverse subtopics. Second, we conduct a comprehensive quality control process to achieve high-quality questions and answers, where the reference answers are static and cannot be changed over time. Third, following SimpleQA, the questions and answers are very short, and the grading process is easy-to-evaluate based on OpenAI API. Based on Chinese SimpleQA, we perform a comprehensive evaluation on the factuality abilities of existing LLMs. Finally, we hope that Chinese SimpleQA could guide the developers to better understand the Chinese factuality abilities of their models and facilitate the growth of foundation models.
ContPhy: Continuum Physical Concept Learning and Reasoning from Videos
Feb 09, 2024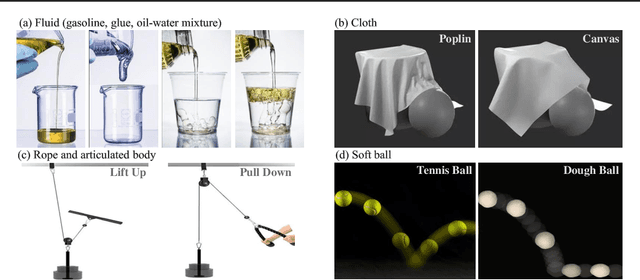
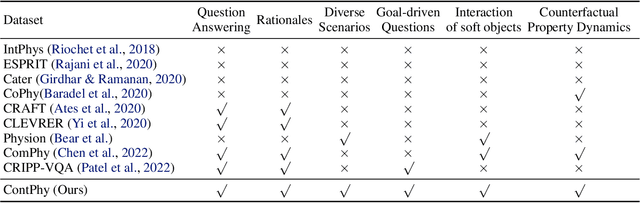
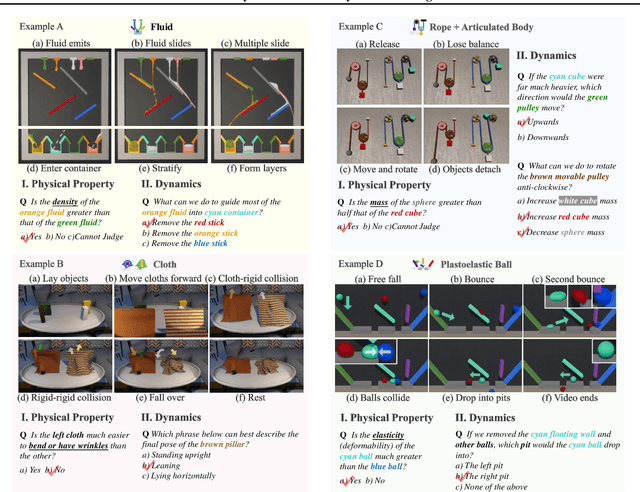
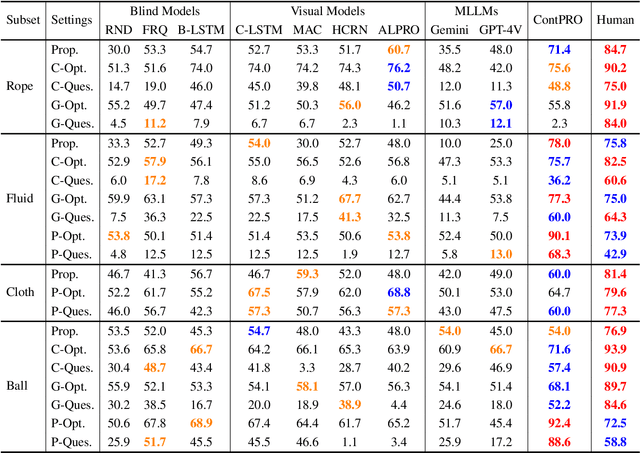
We introduce the Continuum Physical Dataset (ContPhy), a novel benchmark for assessing machine physical commonsense. ContPhy complements existing physical reasoning benchmarks by encompassing the inference of diverse physical properties, such as mass and density, across various scenarios and predicting corresponding dynamics. We evaluated a range of AI models and found that they still struggle to achieve satisfactory performance on ContPhy, which shows that the current AI models still lack physical commonsense for the continuum, especially soft-bodies, and illustrates the value of the proposed dataset. We also introduce an oracle model (ContPRO) that marries the particle-based physical dynamic models with the recent large language models, which enjoy the advantages of both models, precise dynamic predictions, and interpretable reasoning. ContPhy aims to spur progress in perception and reasoning within diverse physical settings, narrowing the divide between human and machine intelligence in understanding the physical world. Project page: https://physical-reasoning-project.github.io.
New Lower Bounds for Testing Monotonicity and Log Concavity of Distributions
Jul 31, 2023We develop a new technique for proving distribution testing lower bounds for properties defined by inequalities involving the bin probabilities of the distribution in question. Using this technique we obtain new lower bounds for monotonicity testing over discrete cubes and tight lower bounds for log-concavity testing. Our basic technique involves constructing a pair of moment-matching families of distributions by tweaking the probabilities of pairs of bins so that one family maintains the defining inequalities while the other violates them.