 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Better Search with Domain-Aware Text Embeddings for C2C Marketplaces
Dec 24, 2025Consumer-to-consumer (C2C) marketplaces pose distinct retrieval challenges: short, ambiguous queries; noisy, user-generated listings; and strict production constraints. This paper reports our experiment to build a domain-aware Japanese text-embedding approach to improve the quality of search at Mercari, Japan's largest C2C marketplace. We experimented with fine-tuning on purchase-driven query-title pairs, using role-specific prefixes to model query-item asymmetry. To meet production constraints, we apply Matryoshka Representation Learning to obtain compact, truncation-robust embeddings. Offline evaluation on historical search logs shows consistent gains over a strong generic encoder, with particularly large improvements when replacing PCA compression with Matryoshka truncation. A manual assessment further highlights better handling of proper nouns, marketplace-specific semantics, and term-importance alignment. Additionally, an initial online A/B test demonstrates statistically significant improvements in revenue per user and search-flow efficiency, with transaction frequency maintained. Results show that domain-aware embeddings improve relevance and efficiency at scale and form a practical foundation for richer LLM-era search experiences.
Sparse Transformer for Ultra-sparse Sampled Video Compressive Sensing
Sep 10, 2025Digital cameras consume ~0.1 microjoule per pixel to capture and encode video, resulting in a power usage of ~20W for a 4K sensor operating at 30 fps. Imagining gigapixel cameras operating at 100-1000 fps, the current processing model is unsustainable. To address this, physical layer compressive measurement has been proposed to reduce power consumption per pixel by 10-100X. Video Snapshot Compressive Imaging (SCI) introduces high frequency modulation in the optical sensor layer to increase effective frame rate. A commonly used sampling strategy of video SCI is Random Sampling (RS) where each mask element value is randomly set to be 0 or 1. Similarly, image inpainting (I2P) has demonstrated that images can be recovered from a fraction of the image pixels. Inspired by I2P, we propose Ultra-Sparse Sampling (USS) regime, where at each spatial location, only one sub-frame is set to 1 and all others are set to 0. We then build a Digital Micro-mirror Device (DMD) encoding system to verify the effectiveness of our USS strategy. Ideally, we can decompose the USS measurement into sub-measurements for which we can utilize I2P algorithms to recover high-speed frames. However, due to the mismatch between the DMD and CCD, the USS measurement cannot be perfectly decomposed. To this end, we propose BSTFormer, a sparse TransFormer that utilizes local Block attention, global Sparse attention, and global Temporal attention to exploit the sparsity of the USS measurement. Extensive results on both simulated and real-world data show that our method significantly outperforms all previous state-of-the-art algorithms. Additionally, an essential advantage of the USS strategy is its higher dynamic range than that of the RS strategy. Finally, from the application perspective, the USS strategy is a good choice to implement a complete video SCI system on chip due to its fixed exposure time.
Unfolding Framework with Complex-Valued Deformable Attention for High-Quality Computer-Generated Hologram Generation
Aug 29, 2025Computer-generated holography (CGH) has gained wide attention with deep learning-based algorithms. However, due to its nonlinear and ill-posed nature, challenges remain in achieving accurate and stable reconstruction. Specifically, ($i$) the widely used end-to-end networks treat the reconstruction model as a black box, ignoring underlying physical relationships, which reduces interpretability and flexibility. ($ii$) CNN-based CGH algorithms have limited receptive fields, hindering their ability to capture long-range dependencies and global context. ($iii$) Angular spectrum method (ASM)-based models are constrained to finite near-fields.In this paper, we propose a Deep Unfolding Network (DUN) that decomposes gradient descent into two modules: an adaptive bandwidth-preserving model (ABPM) and a phase-domain complex-valued denoiser (PCD), providing more flexibility. ABPM allows for wider working distances compared to ASM-based methods. At the same time, PCD leverages its complex-valued deformable self-attention module to capture global features and enhance performance, achieving a PSNR over 35 dB. Experiments on simulated and real data show state-of-the-art results.
High-Speed FHD Full-Color Video Computer-Generated Holography
Aug 27, 2025Computer-generated holography (CGH) is a promising technology for next-generation displays. However, generating high-speed, high-quality holographic video requires both high frame rate display and efficient computation, but is constrained by two key limitations: ($i$) Learning-based models often produce over-smoothed phases with narrow angular spectra, causing severe color crosstalk in high frame rate full-color displays such as depth-division multiplexing and thus resulting in a trade-off between frame rate and color fidelity. ($ii$) Existing frame-by-frame optimization methods typically optimize frames independently, neglecting spatial-temporal correlations between consecutive frames and leading to computationally inefficient solutions. To overcome these challenges, in this paper, we propose a novel high-speed full-color video CGH generation scheme. First, we introduce Spectrum-Guided Depth Division Multiplexing (SGDDM), which optimizes phase distributions via frequency modulation, enabling high-fidelity full-color display at high frame rates. Second, we present HoloMamba, a lightweight asymmetric Mamba-Unet architecture that explicitly models spatial-temporal correlations across video sequences to enhance reconstruction quality and computational efficiency. Extensive simulated and real-world experiments demonstrate that SGDDM achieves high-fidelity full-color display without compromise in frame rate, while HoloMamba generates FHD (1080p) full-color holographic video at over 260 FPS, more than 2.6$\times$ faster than the prior state-of-the-art Divide-Conquer-and-Merge Strategy.
Quality-factor inspired deep neural network solver for solving inverse scattering problems
Apr 29, 2025Deep neural networks have been applied to address electromagnetic inverse scattering problems (ISPs) and shown superior imaging performances, which can be affected by the training dataset, the network architecture and the applied loss function. Here, the quality of data samples is cared and valued by the defined quality factor. Based on the quality factor, the composition of the training dataset is optimized. The network architecture is integrated with the residual connections and channel attention mechanism to improve feature extraction. A loss function that incorporates data-fitting error, physical-information constraints and the desired feature of the solution is designed and analyzed to suppress the background artifacts and improve the reconstruction accuracy. Various numerical analysis are performed to demonstrate the superiority of the proposed quality-factor inspired deep neural network (QuaDNN) solver and the imaging performance is finally verified by experimental imaging test.
Prior-guided Hierarchical Harmonization Network for Efficient Image Dehazing
Mar 03, 2025Image dehazing is a crucial task that involves the enhancement of degraded images to recover their sharpness and textures. While vision Transformers have exhibited impressive results in diverse dehazing tasks, their quadratic complexity and lack of dehazing priors pose significant drawbacks for real-world applications. In this paper, guided by triple priors, Bright Channel Prior (BCP), Dark Channel Prior (DCP), and Histogram Equalization (HE), we propose a \textit{P}rior-\textit{g}uided Hierarchical \textit{H}armonization Network (PGH$^2$Net) for image dehazing. PGH$^2$Net is built upon the UNet-like architecture with an efficient encoder and decoder, consisting of two module types: (1) Prior aggregation module that injects B/DCP and selects diverse contexts with gating attention. (2) Feature harmonization modules that subtract low-frequency components from spatial and channel aspects and learn more informative feature distributions to equalize the feature maps.
Image Score: Learning and Evaluating Human Preferences for Mercari Search
Aug 21, 2024Mercari is the largest C2C e-commerce marketplace in Japan, having more than 20 million active monthly users. Search being the fundamental way to discover desired items, we have always had a substantial amount of data with implicit feedback. Although we actively take advantage of that to provide the best service for our users, the correlation of implicit feedback for such tasks as image quality assessment is not trivial. Many traditional lines of research in Machine Learning (ML) are similarly motivated by the insatiable appetite of Deep Learning (DL) models for well-labelled training data. Weak supervision is about leveraging higher-level and/or noisier supervision over unlabeled data. Large Language Models (LLMs) are being actively studied and used for data labelling tasks. We present how we leverage a Chain-of-Thought (CoT) to enable LLM to produce image aesthetics labels that correlate well with human behavior in e-commerce settings. Leveraging LLMs is more cost-effective compared to explicit human judgment, while significantly improving the explainability of deep image quality evaluation which is highly important for customer journey optimization at Mercari. We propose a cost-efficient LLM-driven approach for assessing and predicting image quality in e-commerce settings, which is very convenient for proof-of-concept testing. We show that our LLM-produced labels correlate with user behavior on Mercari. Finally, we show our results from an online experimentation, where we achieved a significant growth in sales on the web platform.
Towards Real-time Video Compressive Sensing on Mobile Devices
Aug 14, 2024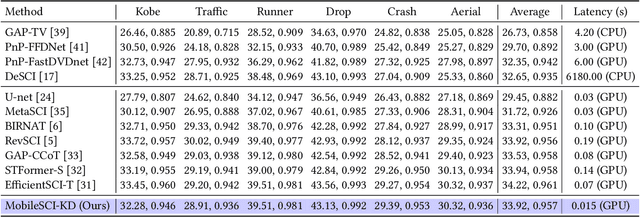


Video Snapshot Compressive Imaging (SCI) uses a low-speed 2D camera to capture high-speed scenes as snapshot compressed measurements, followed by a reconstruction algorithm to retrieve the high-speed video frames. The fast evolving mobile devices and existing high-performance video SCI reconstruction algorithms motivate us to develop mobile reconstruction methods for real-world applications. Yet, it is still challenging to deploy previous reconstruction algorithms on mobile devices due to the complex inference process, let alone real-time mobile reconstruction. To the best of our knowledge, there is no video SCI reconstruction model designed to run on the mobile devices. Towards this end, in this paper, we present an effective approach for video SCI reconstruction, dubbed MobileSCI, which can run at real-time speed on the mobile devices for the first time. Specifically, we first build a U-shaped 2D convolution-based architecture, which is much more efficient and mobile-friendly than previous state-of-the-art reconstruction methods. Besides, an efficient feature mixing block, based on the channel splitting and shuffling mechanisms, is introduced as a novel bottleneck block of our proposed MobileSCI to alleviate the computational burden. Finally, a customized knowledge distillation strategy is utilized to further improve the reconstruction quality. Extensive results on both simulated and real data show that our proposed MobileSCI can achieve superior reconstruction quality with high efficiency on the mobile devices. Particularly, we can reconstruct a 256 X 256 X 8 snapshot compressed measurement with real-time performance (about 35 FPS) on an iPhone 15. Code is available at https://github.com/mcao92/MobileSCI.
A Simple Low-bit Quantization Framework for Video Snapshot Compressive Imaging
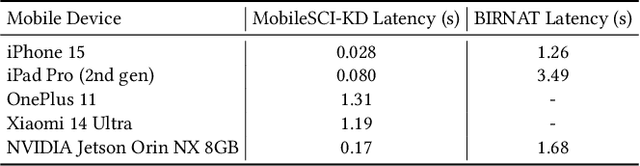
Jul 31, 2024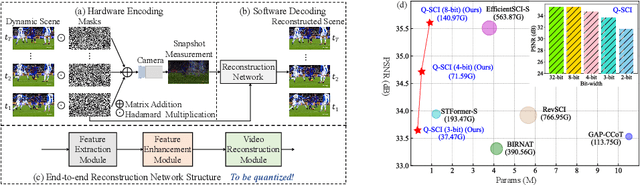
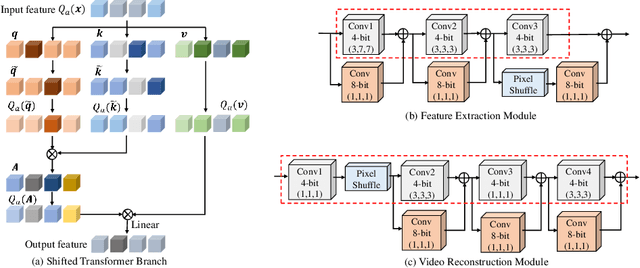
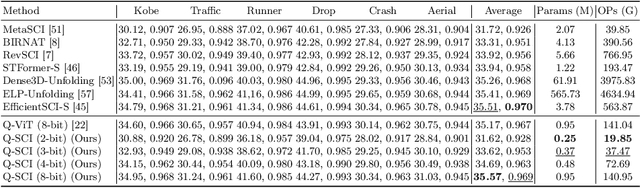
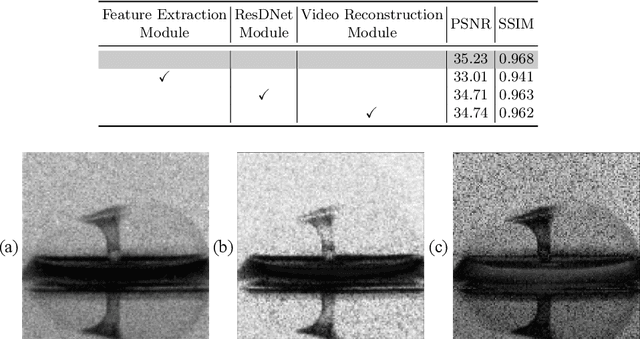
Video Snapshot Compressive Imaging (SCI) aims to use a low-speed 2D camera to capture high-speed scene as snapshot compressed measurements, followed by a reconstruction algorithm to reconstruct the high-speed video frames. State-of-the-art (SOTA) deep learning-based algorithms have achieved impressive performance, yet with heavy computational workload. Network quantization is a promising way to reduce computational cost. However, a direct low-bit quantization will bring large performance drop. To address this challenge, in this paper, we propose a simple low-bit quantization framework (dubbed Q-SCI) for the end-to-end deep learning-based video SCI reconstruction methods which usually consist of a feature extraction, feature enhancement, and video reconstruction module. Specifically, we first design a high-quality feature extraction module and a precise video reconstruction module to extract and propagate high-quality features in the low-bit quantized model. In addition, to alleviate the information distortion of the Transformer branch in the quantized feature enhancement module, we introduce a shift operation on the query and key distributions to further bridge the performance gap. Comprehensive experimental results manifest that our Q-SCI framework can achieve superior performance, e.g., 4-bit quantized EfficientSCI-S derived by our Q-SCI framework can theoretically accelerate the real-valued EfficientSCI-S by 7.8X with only 2.3% performance gap on the simulation testing datasets. Code is available at https://github.com/mcao92/QuantizedSCI.
Coarse-Fine Spectral-Aware Deformable Convolution For Hyperspectral Image Reconstruction
Jun 18, 2024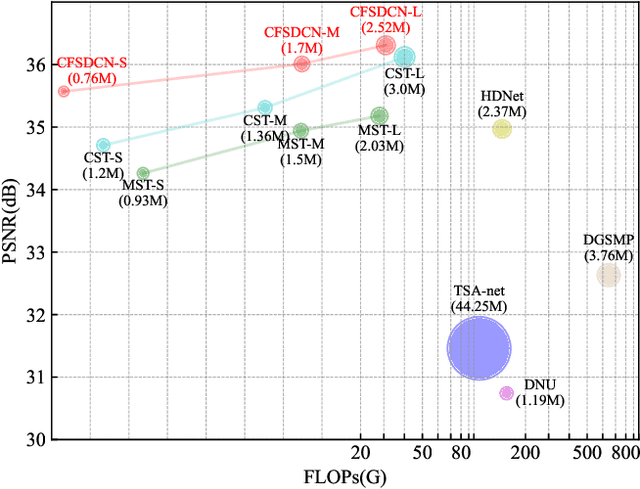
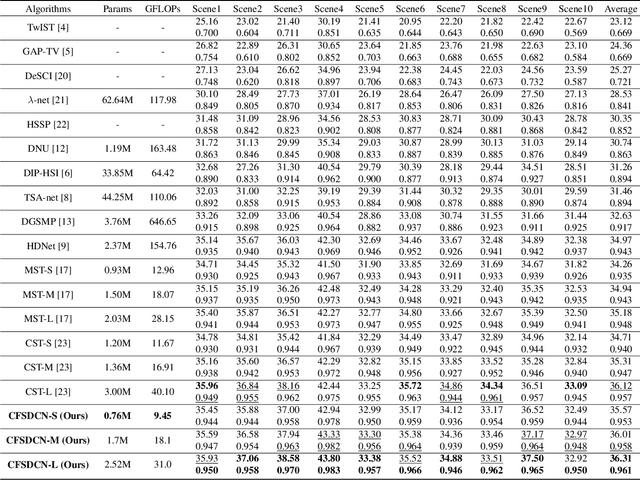
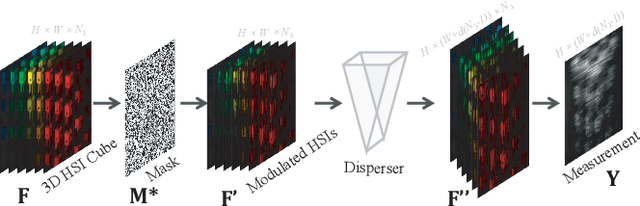

We study the inverse problem of Coded Aperture Snapshot Spectral Imaging (CASSI), which captures a spatial-spectral data cube using snapshot 2D measurements and uses algorithms to reconstruct 3D hyperspectral images (HSI). However, current methods based on Convolutional Neural Networks (CNNs) struggle to capture long-range dependencies and non-local similarities. The recently popular Transformer-based methods are poorly deployed on downstream tasks due to the high computational cost caused by self-attention. In this paper, we propose Coarse-Fine Spectral-Aware Deformable Convolution Network (CFSDCN), applying deformable convolutional networks (DCN) to this task for the first time. Considering the sparsity of HSI, we design a deformable convolution module that exploits its deformability to capture long-range dependencies and non-local similarities. In addition, we propose a new spectral information interaction module that considers both coarse-grained and fine-grained spectral similarities. Extensive experiments demonstrate that our CFSDCN significantly outperforms previous state-of-the-art (SOTA) methods on both simulated and real HSI datasets.