 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking Anything in Heart All at Once
Oct 04, 2023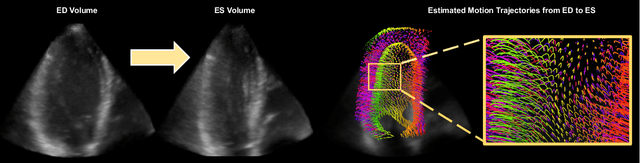
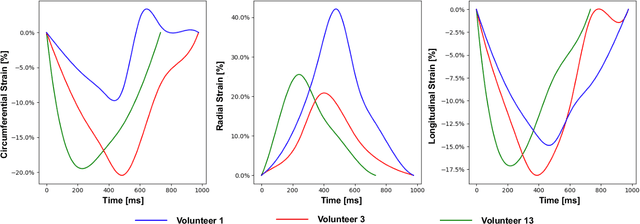
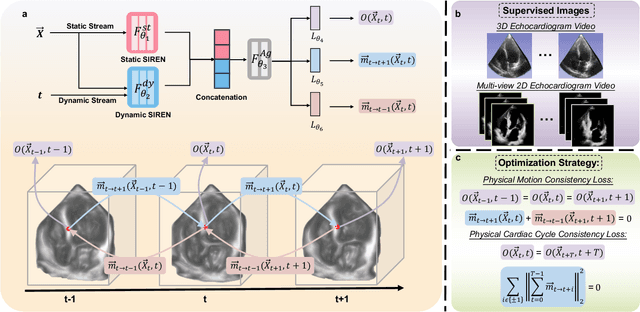
Myocardial motion tracking stands as an essential clinical tool in the prevention and detection of Cardiovascular Diseases (CVDs), the foremost cause of death globally. However, current techniques suffer incomplete and inaccurate motion estimation of the myocardium both in spatial and temporal dimensions, hindering the early identification of myocardial dysfunction. In addressing these challenges, this paper introduces the Neural Cardiac Motion Field (NeuralCMF). NeuralCMF leverages the implicit neural representation (INR) to model the 3D structure and the comprehensive 6D forward/backward motion of the heart. This approach offers memory-efficient storage and continuous capability to query the precise shape and motion of the myocardium throughout the cardiac cycle at any specific point. Notably, NeuralCMF operates without the need for paired datasets, and its optimization is self-supervised through the physics knowledge priors both in space and time dimensions, ensuring compatibility with both 2D and 3D echocardiogram video inputs. Experimental validations across three representative datasets support the robustness and innovative nature of the NeuralCMF, marking significant advantages over existing state-of-the-arts in cardiac imaging and motion tracking.
Large-scale Global Low-rank Optimization for Computational Compressed Imaging
Jan 08, 2023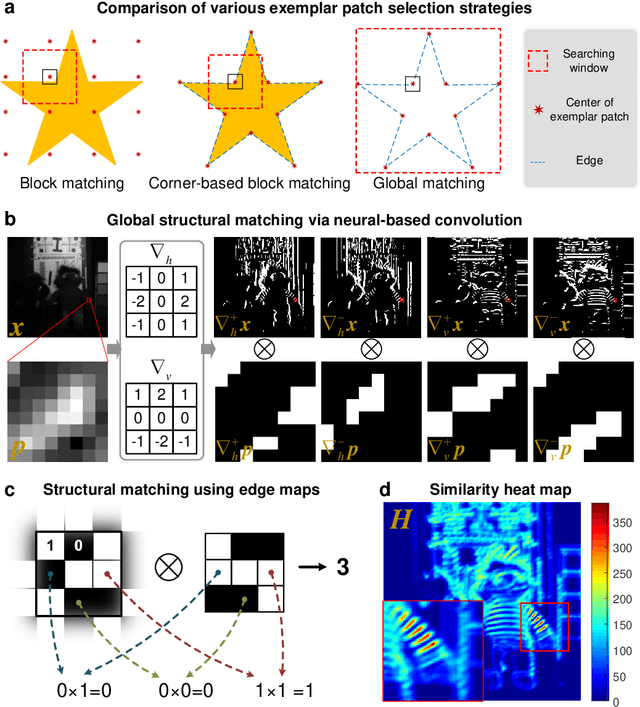
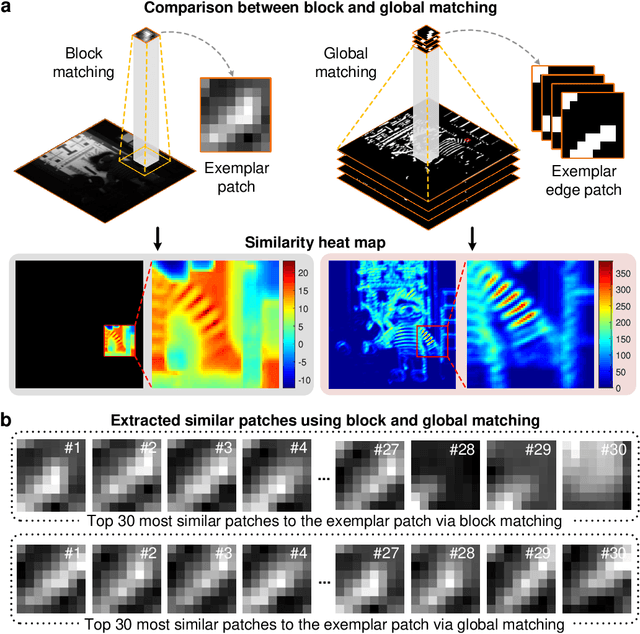
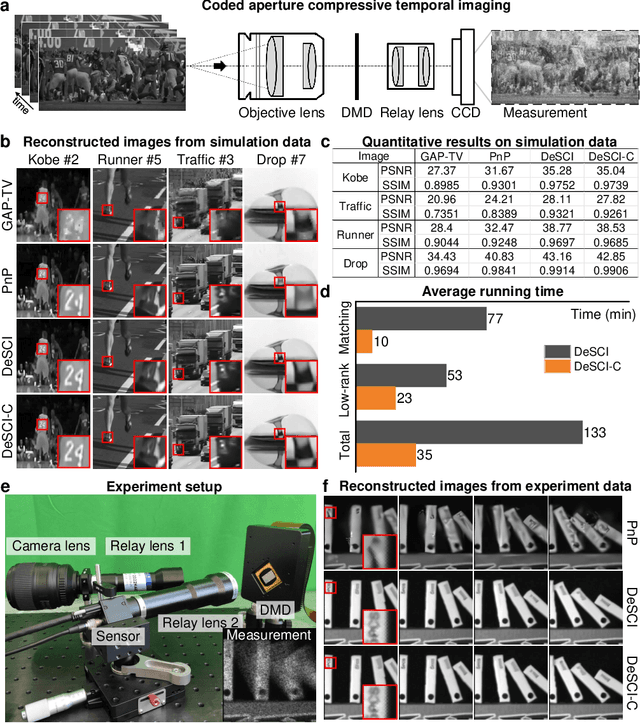
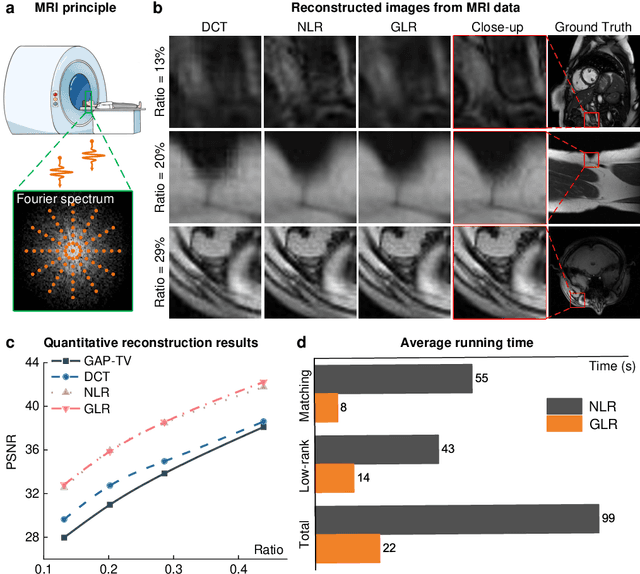
Computational reconstruction plays a vital role in computer vision and computational photography. Most of the conventional optimization and deep learning techniques explore local information for reconstruction. Recently, nonlocal low-rank (NLR) reconstruction has achieved remarkable success in improving accuracy and generalization. However, the computational cost has inhibited NLR from seeking global structural similarity, which consequentially keeps it trapped in the tradeoff between accuracy and efficiency and prevents it from high-dimensional large-scale tasks. To address this challenge, we report here the global low-rank (GLR) optimization technique, realizing highly-efficient large-scale reconstruction with global self-similarity. Inspired by the self-attention mechanism in deep learning, GLR extracts exemplar image patches by feature detection instead of conventional uniform selection. This directly produces key patches using structural features to avoid burdensome computational redundancy. Further, it performs patch matching across the entire image via neural-based convolution, which produces the global similarity heat map in parallel, rather than conventional sequential block-wise matching. As such, GLR improves patch grouping efficiency by more than one order of magnitude. We experimentally demonstrate GLR's effectiveness on temporal, frequency, and spectral dimensions, including different computational imaging modalities of compressive temporal imaging, magnetic resonance imaging, and multispectral filter array demosaicing. This work presents the superiority of inherent fusion of deep learning strategies and iterative optimization, and breaks the persistent dilemma of the tradeoff between accuracy and efficiency for various large-scale reconstruction tasks.
Scatter Ptychography
Mar 23, 2022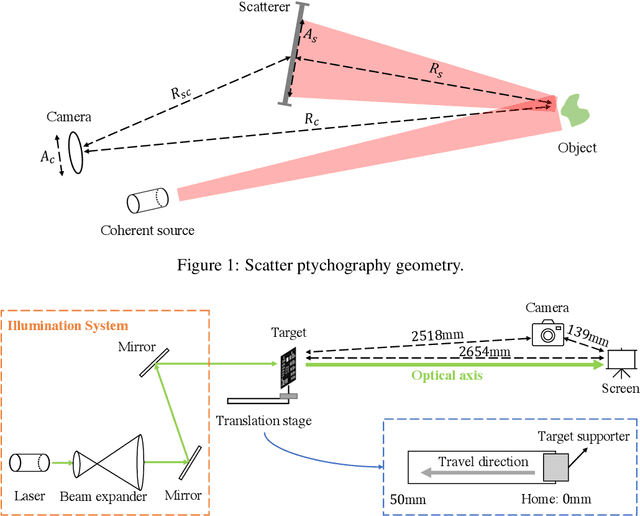
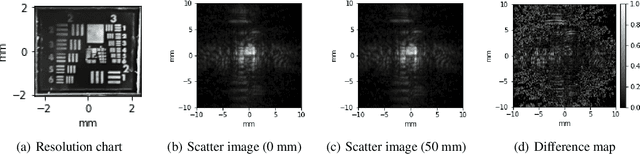
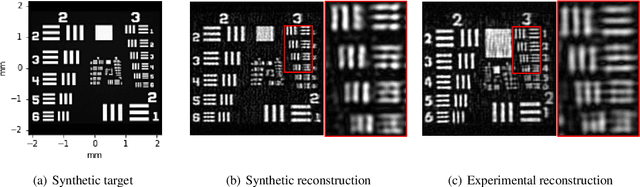

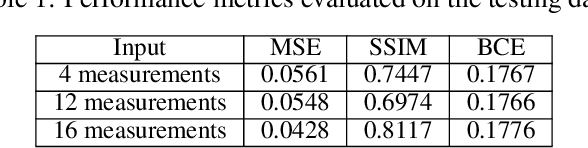
Coherent illumination reflected by a remote target may be secondarily scattered by intermediate objects or materials. Here we show that phase retrieval on remotely observed images of such scattered fields enables imaging of the illuminated object at resolution proportional to $\lambda R_s/A_s$, where $R_s$ is the range between the scatterer and the target and $A_s$ is the diameter of the observed scatter. This resolution may exceed the resolution of directly viewing the target by the factor $R_cA_s/R_sA_c$, where $R_c$ is the range between the observer and the target and $A_c$ is the observing aperture. Here we use this technique to demonstrate $\approx 32\times$ resolution improvement relative to direct imaging.
Snapshot Ptychography on Array cameras
Nov 05, 2021


We use convolutional neural networks to recover images optically down-sampled by $6.7\times$ using coherent aperture synthesis over a 16 camera array. Where conventional ptychography relies on scanning and oversampling, here we apply decompressive neural estimation to recover full resolution image from a single snapshot, although as shown in simulation multiple snapshots can be used to improve SNR. In place training on experimental measurements eliminates the need to directly calibrate the measurement system. We also present simulations of diverse array camera sampling strategies to explore how snapshot compressive systems might be optimized.
Computational Imaging and Artificial Intelligence: The Next Revolution of Mobile Vision
Sep 18, 2021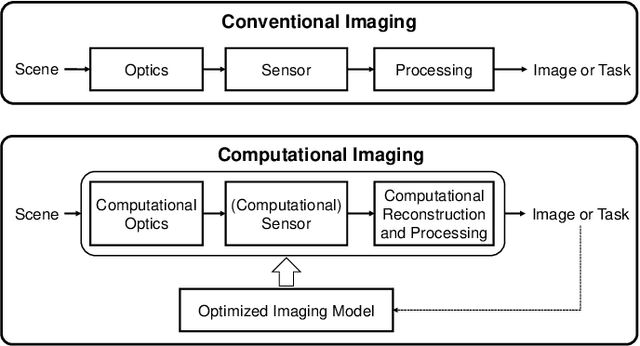
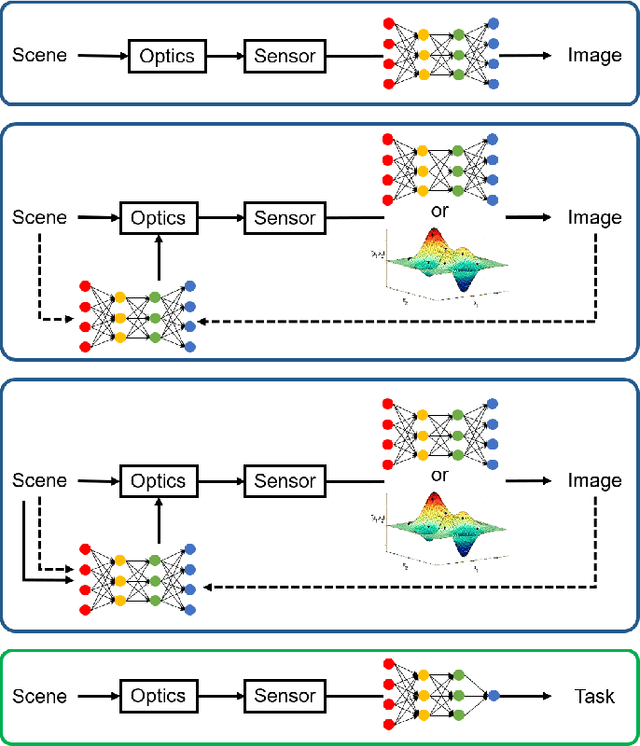
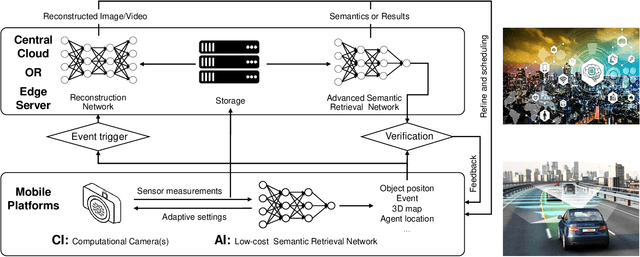
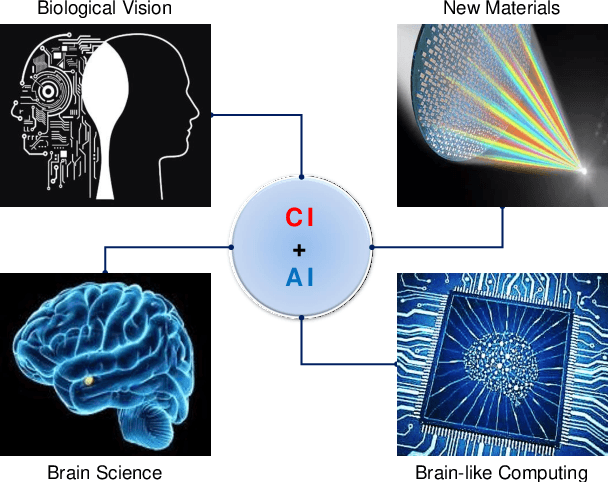
Signal capture stands in the forefront to perceive and understand the environment and thus imaging plays the pivotal role in mobile vision. Recent explosive progresses in Artificial Intelligence (AI) have shown great potential to develop advanced mobile platforms with new imaging devices. Traditional imaging systems based on the "capturing images first and processing afterwards" mechanism cannot meet this unprecedented demand. Differently, Computational Imaging (CI) systems are designed to capture high-dimensional data in an encoded manner to provide more information for mobile vision systems.Thanks to AI, CI can now be used in real systems by integrating deep learning algorithms into the mobile vision platform to achieve the closed loop of intelligent acquisition, processing and decision making, thus leading to the next revolution of mobile vision.Starting from the history of mobile vision using digital cameras, this work first introduces the advances of CI in diverse applications and then conducts a comprehensive review of current research topics combining CI and AI. Motivated by the fact that most existing studies only loosely connect CI and AI (usually using AI to improve the performance of CI and only limited works have deeply connected them), in this work, we propose a framework to deeply integrate CI and AI by using the example of self-driving vehicles with high-speed communication, edge computing and traffic planning. Finally, we outlook the future of CI plus AI by investigating new materials, brain science and new computing techniques to shed light on new directions of mobile vision systems.
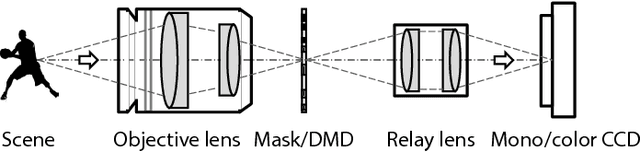
Snapshot Compressive Imaging: Principle, Implementation, Theory, Algorithms and Applications
Mar 07, 2021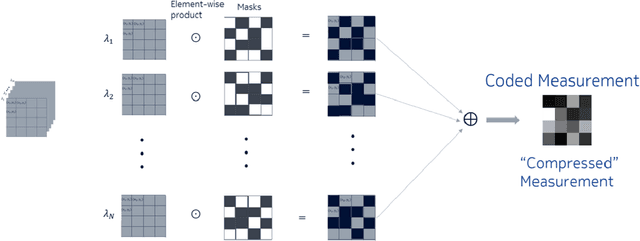
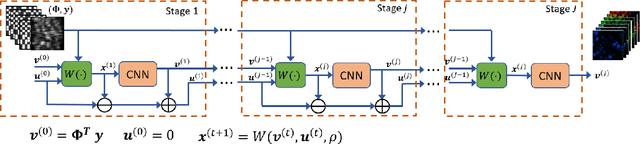


Capturing high-dimensional (HD) data is a long-term challenge in signal processing and related fields. Snapshot compressive imaging (SCI) uses a two-dimensional (2D) detector to capture HD ($\ge3$D) data in a {\em snapshot} measurement. Via novel optical designs, the 2D detector samples the HD data in a {\em compressive} manner; following this, algorithms are employed to reconstruct the desired HD data-cube. SCI has been used in hyperspectral imaging, video, holography, tomography, focal depth imaging, polarization imaging, microscopy, \etc.~Though the hardware has been investigated for more than a decade, the theoretical guarantees have only recently been derived. Inspired by deep learning, various deep neural networks have also been developed to reconstruct the HD data-cube in spectral SCI and video SCI. This article reviews recent advances in SCI hardware, theory and algorithms, including both optimization-based and deep-learning-based algorithms. Diverse applications and the outlook of SCI are also discussed.
* Extension of X. Yuan, D. J. Brady and A. K. Katsaggelos, "Snapshot Compressive Imaging: Theory, Algorithms, and Applications," in IEEE Signal Processing Magazine, vol. 38, no. 2, pp. 65-88, March 2021, doi: 10.1109/MSP.2020.3023869
Thin Lenses and Thin Cameras
Jan 12, 2021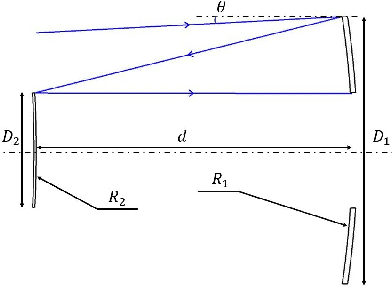
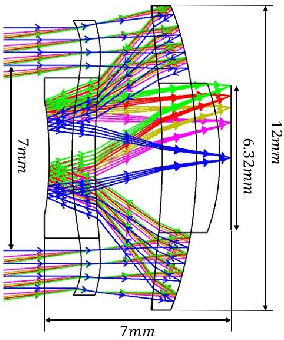
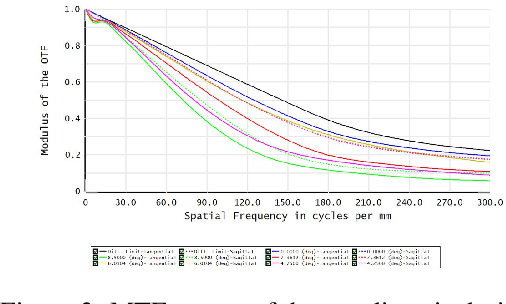
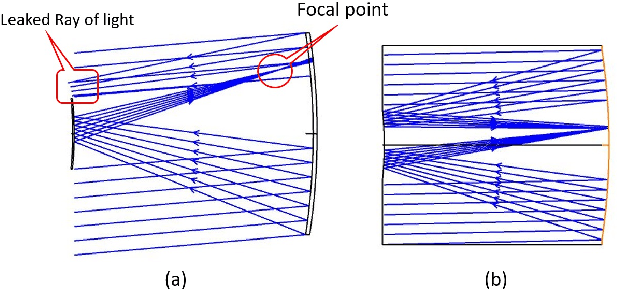
Cassegrain designs can be used to build thin lenses. We analyze the relationships between system thickness and aperture sizes of the two mirrors as well as FoV size. Our analysis shows that decrease in lens thickness imposes tight constraint on the aperture and FoV size. To mitigate this limitation, we propose to fill the gaps between the primary and the secondary with high index material. The Gassegrain optics cuts the track length into half and high index material reduces ray angle and height, consequently the incident ray angle can be increased, i.e., the FoV angle is extended. Defining telephoto ratio as the ratio of lens thickness to focal length, we achieve telephoto ratios as small as 0.43 for a visible Cassegrain thin lens and 1.20 for an infrared Cassegrain thin lens. To achieve an arbitrary FoV coverage, we present an strategy by integrating multiple thin lenses on one plane with each unit covering a different FoV region. To avoid physically tilting each unit, we propose beam steering with metasurface. By image stitching, we obtain wide FoV images.
Rank Minimization for Snapshot Compressive Imaging
Jul 20, 2018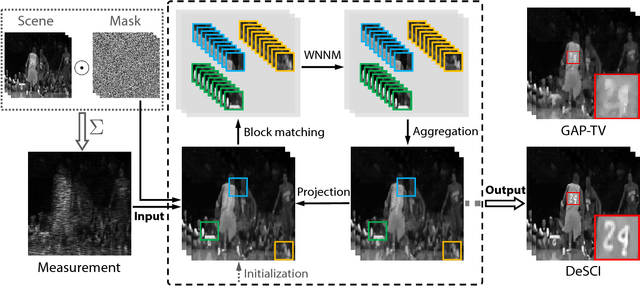


Snapshot compressive imaging (SCI) refers to compressive imaging systems where multiple frames are mapped into a single measurement, with video compressive imaging and hyperspectral compressive imaging as two representative applications. Though exciting results of high-speed videos and hyperspectral images have been demonstrated, the poor reconstruction quality precludes SCI from wide applications.This paper aims to boost the reconstruction quality of SCI via exploiting the high-dimensional structure in the desired signal. We build a joint model to integrate the nonlocal self-similarity of video/hyperspectral frames and the rank minimization approach with the SCI sensing process. Following this, an alternating minimization algorithm is developed to solve this non-convex problem. We further investigate the special structure of the sampling process in SCI to tackle the computational workload and memory issues in SCI reconstruction. Both simulation and real data (captured by four different SCI cameras) results demonstrate that our proposed algorithm leads to significant improvements compared with current state-of-the-art algorithms. We hope our results will encourage the researchers and engineers to pursue further in compressive imaging for real applications.
Spectrally Grouped Total Variation Reconstruction for Scatter Imaging Using ADMM
Jan 29, 2016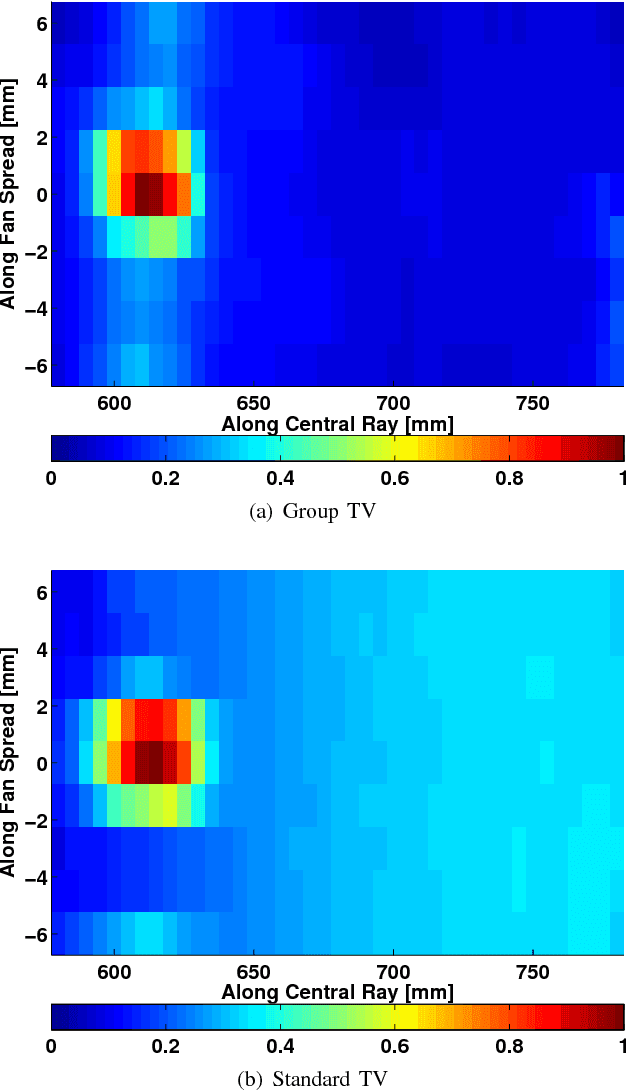

We consider X-ray coherent scatter imaging, where the goal is to reconstruct momentum transfer profiles (spectral distributions) at each spatial location from multiplexed measurements of scatter. Each material is characterized by a unique momentum transfer profile (MTP) which can be used to discriminate between different materials. We propose an iterative image reconstruction algorithm based on a Poisson noise model that can account for photon-limited measurements as well as various second order statistics of the data. To improve image quality, previous approaches use edge-preserving regularizers to promote piecewise constancy of the image in the spatial domain while treating each spectral bin separately. Instead, we propose spectrally grouped regularization that promotes piecewise constant images along the spatial directions but also ensures that the MTPs of neighboring spatial bins are similar, if they contain the same material. We demonstrate that this group regularization results in improvement of both spectral and spatial image quality. We pursue an optimization transfer approach where convex decompositions are used to lift the problem such that all hyper-voxels can be updated in parallel and in closed-form. The group penalty introduces a challenge since it is not directly amendable to these decompositions. We use the alternating directions method of multipliers (ADMM) to replace the original problem with an equivalent sequence of sub-problems that are amendable to convex decompositions, leading to a highly parallel algorithm. We demonstrate the performance on real data.
Joint System and Algorithm Design for Computationally Efficient Fan Beam Coded Aperture X-ray Coherent Scatter Imaging
Jan 29, 2016
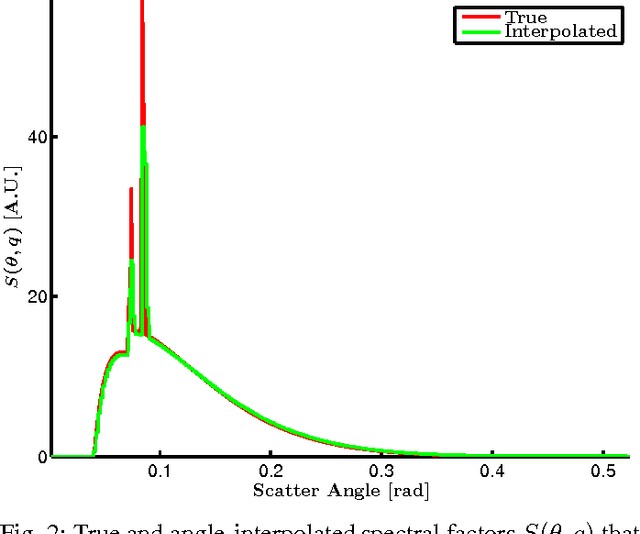
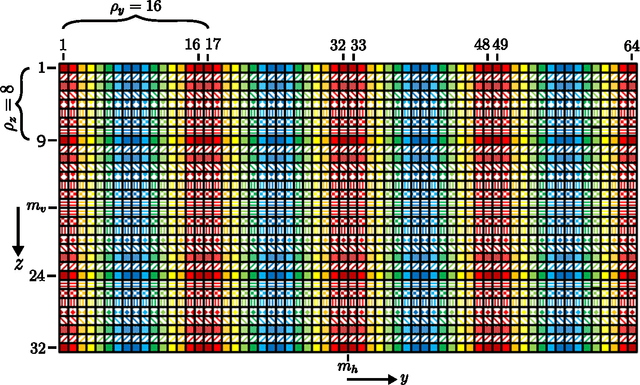
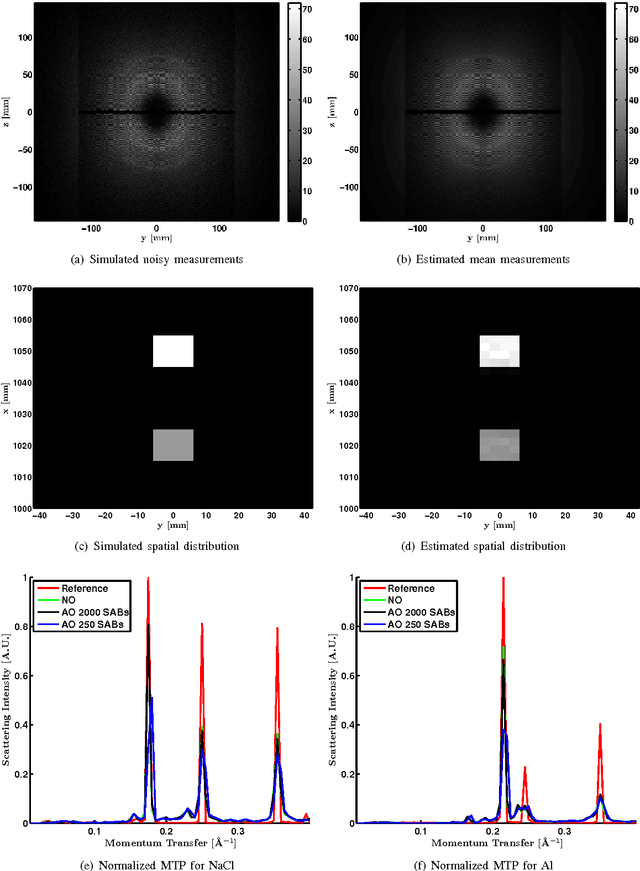
In x-ray coherent scatter tomography, tomographic measurements of the forward scatter distribution are used to infer scatter densities within a volume. A radiopaque 2D pattern placed between the object and the detector array enables the disambiguation between different scatter events. The use of a fan beam source illumination to speed up data acquisition relative to a pencil beam presents computational challenges. To facilitate the use of iterative algorithms based on a penalized Poisson log-likelihood function, efficient computational implementation of the forward and backward models are needed. Our proposed implementation exploits physical symmetries and structural properties of the system and suggests a joint system-algorithm design, where the system design choices are influenced by computational considerations, and in turn lead to reduced reconstruction time. Computational-time speedups of approximately 146 and 32 are achieved in the computation of the forward and backward models, respectively. Results validating the forward model and reconstruction algorithm are presented on simulated analytic and Monte Carlo data.