 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeFine: A Decomposed and Fine-Grained Annotated Dataset for Long-form Article Generation
Mar 10, 2025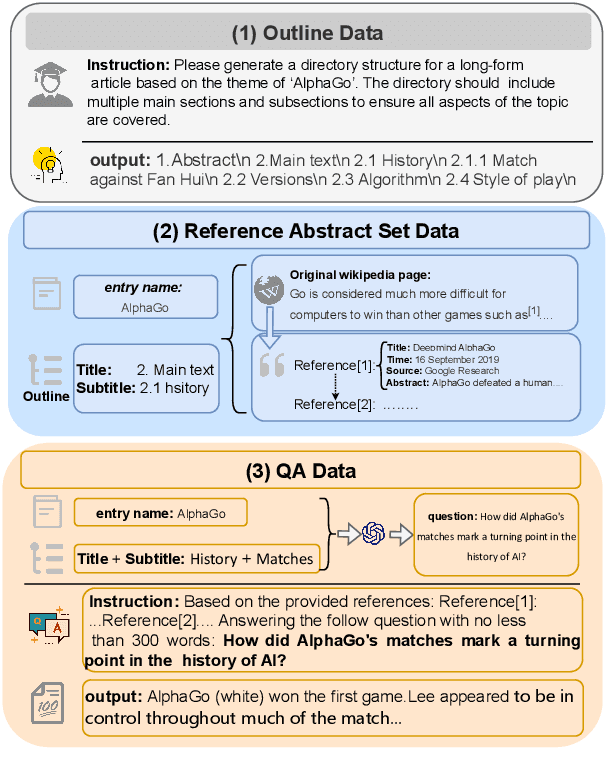
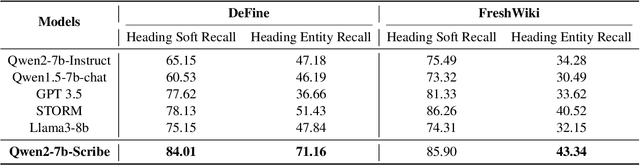
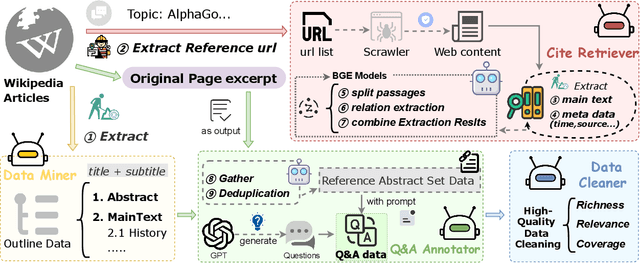
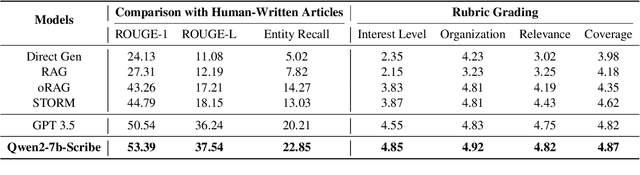
Long-form article generation (LFAG) presents challenges such as maintaining logical consistency, comprehensive topic coverage, and narrative coherence across extended articles. Existing datasets often lack both the hierarchical structure and fine-grained annotation needed to effectively decompose tasks, resulting in shallow, disorganized article generation. To address these limitations, we introduce DeFine, a Decomposed and Fine-grained annotated dataset for long-form article generation. DeFine is characterized by its hierarchical decomposition strategy and the integration of domain-specific knowledge with multi-level annotations, ensuring granular control and enhanced depth in article generation. To construct the dataset, a multi-agent collaborative pipeline is proposed, which systematically segments the generation process into four parts: Data Miner, Cite Retreiver, Q&A Annotator and Data Cleaner. To validate the effectiveness of DeFine, we designed and tested three LFAG baselines: the web retrieval, the local retrieval, and the grounded reference. We fine-tuned the Qwen2-7b-Instruct model using the DeFine training dataset. The experimental results showed significant improvements in text quality, specifically in topic coverage, depth of information, and content fidelity. Our dataset publicly available to facilitate future research.
KC-GenRe: A Knowledge-constrained Generative Re-ranking Method Based on Large Language Models for Knowledge Graph Completion
Mar 26, 2024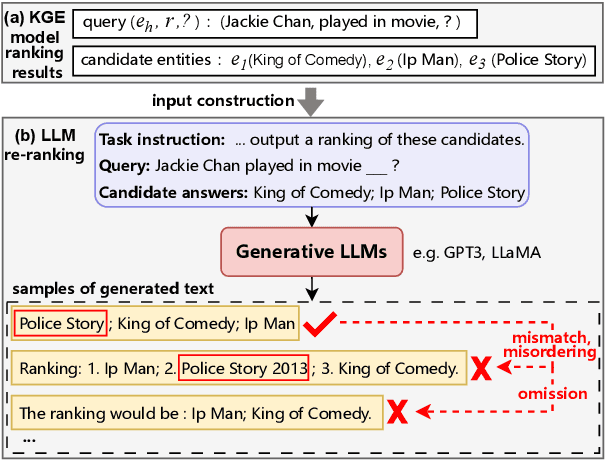
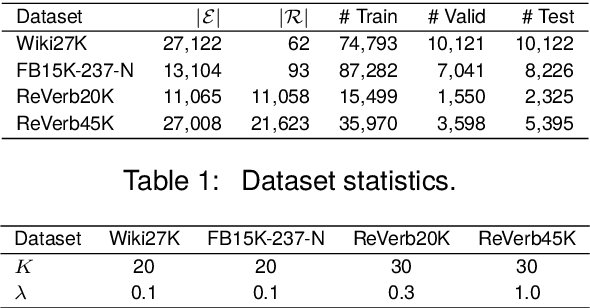
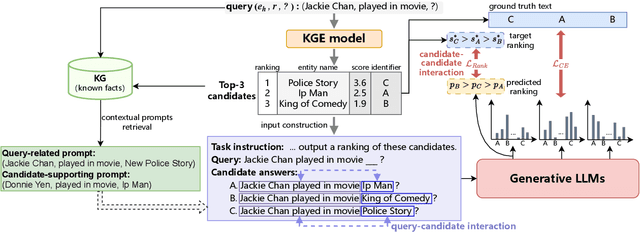
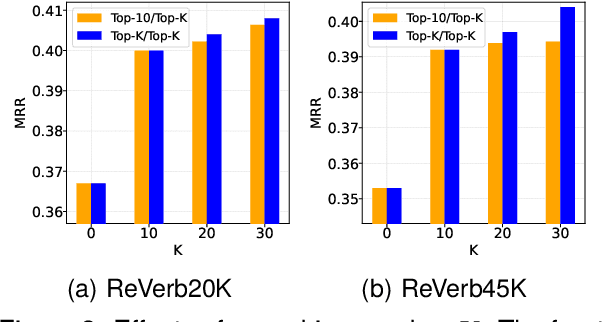
The goal of knowledge graph completion (KGC) is to predict missing facts among entities. Previous methods for KGC re-ranking are mostly built on non-generative language models to obtain the probability of each candidate. Recently, generative large language models (LLMs) have shown outstanding performance on several tasks such as information extraction and dialog systems. Leveraging them for KGC re-ranking is beneficial for leveraging the extensive pre-trained knowledge and powerful generative capabilities. However, it may encounter new problems when accomplishing the task, namely mismatch, misordering and omission. To this end, we introduce KC-GenRe, a knowledge-constrained generative re-ranking method based on LLMs for KGC. To overcome the mismatch issue, we formulate the KGC re-ranking task as a candidate identifier sorting generation problem implemented by generative LLMs. To tackle the misordering issue, we develop a knowledge-guided interactive training method that enhances the identification and ranking of candidates. To address the omission issue, we design a knowledge-augmented constrained inference method that enables contextual prompting and controlled generation, so as to obtain valid rankings. Experimental results show that KG-GenRe achieves state-of-the-art performance on four datasets, with gains of up to 6.7% and 7.7% in the MRR and Hits@1 metric compared to previous methods, and 9.0% and 11.1% compared to that without re-ranking. Extensive analysis demonstrates the effectiveness of components in KG-GenRe.
Array Camera Image Fusion using Physics-Aware Transformers
Jul 05, 2022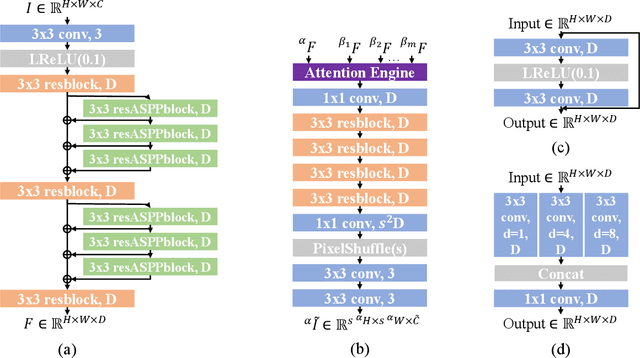


We demonstrate a physics-aware transformer for feature-based data fusion from cameras with diverse resolution, color spaces, focal planes, focal lengths, and exposure. We also demonstrate a scalable solution for synthetic training data generation for the transformer using open-source computer graphics software. We demonstrate image synthesis on arrays with diverse spectral responses, instantaneous field of view and frame rate.
ICLEA: Interactive Contrastive Learning for Self-supervised Entity Alignment
Jan 17, 2022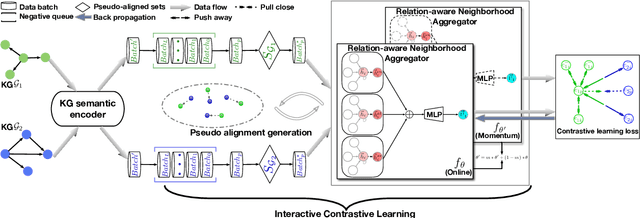
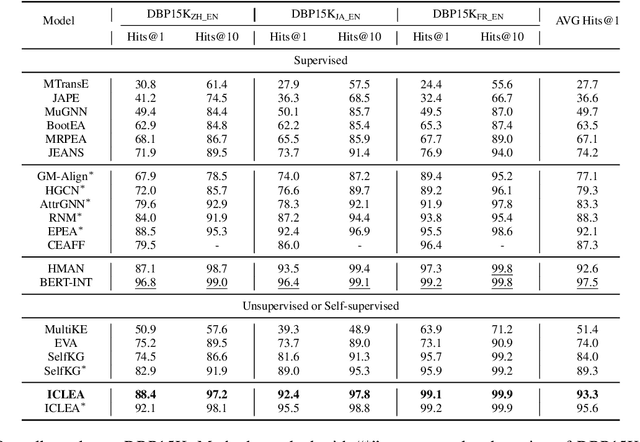
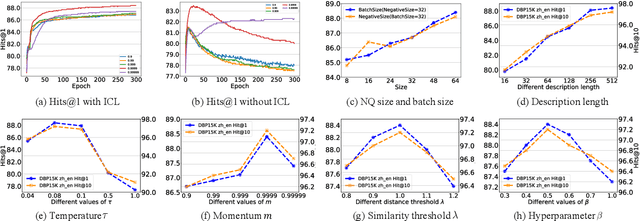
Self-supervised entity alignment (EA) aims to link equivalent entities across different knowledge graphs (KGs) without seed alignments. The current SOTA self-supervised EA method draws inspiration from contrastive learning, originally designed in computer vision based on instance discrimination and contrastive loss, and suffers from two shortcomings. Firstly, it puts unidirectional emphasis on pushing sampled negative entities far away rather than pulling positively aligned pairs close, as is done in the well-established supervised EA. Secondly, KGs contain rich side information (e.g., entity description), and how to effectively leverage those information has not been adequately investigated in self-supervised EA. In this paper, we propose an interactive contrastive learning model for self-supervised EA. The model encodes not only structures and semantics of entities (including entity name, entity description, and entity neighborhood), but also conducts cross-KG contrastive learning by building pseudo-aligned entity pairs. Experimental results show that our approach outperforms previous best self-supervised results by a large margin (over 9% average improvement) and performs on par with previous SOTA supervised counterparts, demonstrating the effectiveness of the interactive contrastive learning for self-supervised EA.
Snapshot Ptychography on Array cameras
Nov 05, 2021
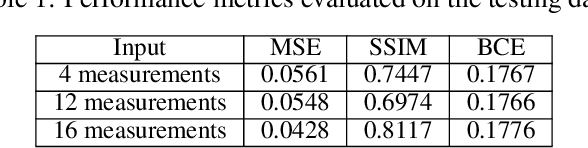


We use convolutional neural networks to recover images optically down-sampled by $6.7\times$ using coherent aperture synthesis over a 16 camera array. Where conventional ptychography relies on scanning and oversampling, here we apply decompressive neural estimation to recover full resolution image from a single snapshot, although as shown in simulation multiple snapshots can be used to improve SNR. In place training on experimental measurements eliminates the need to directly calibrate the measurement system. We also present simulations of diverse array camera sampling strategies to explore how snapshot compressive systems might be optimized.
A Multi-Type Multi-Span Network for Reading Comprehension that Requires Discrete Reasoning
Aug 30, 2019



Rapid progress has been made in the field of reading comprehension and question answering, where several systems have achieved human parity in some simplified settings. However, the performance of these models degrades significantly when they are applied to more realistic scenarios, such as answers involve various types, multiple text strings are correct answers, or discrete reasoning abilities are required. In this paper, we introduce the Multi-Type Multi-Span Network (MTMSN), a neural reading comprehension model that combines a multi-type answer predictor designed to support various answer types (e.g., span, count, negation, and arithmetic expression) with a multi-span extraction method for dynamically producing one or multiple text spans. In addition, an arithmetic expression reranking mechanism is proposed to rank expression candidates for further confirming the prediction. Experiments show that our model achieves 79.9 F1 on the DROP hidden test set, creating new state-of-the-art results. Source code\footnote{\url{https://github.com/huminghao16/MTMSN}} is released to facilitate future work.
Retrieve, Read, Rerank: Towards End-to-End Multi-Document Reading Comprehension
Jun 11, 2019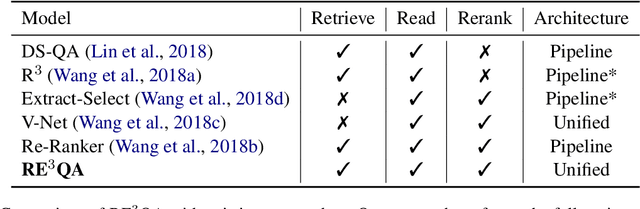
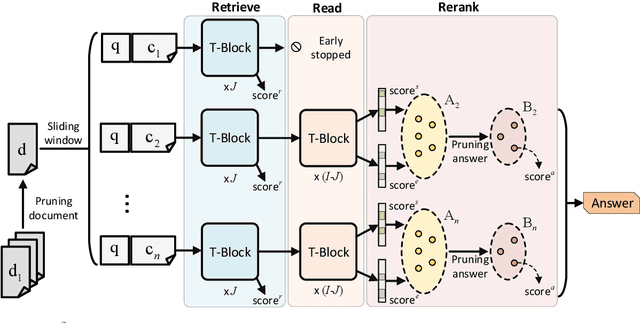

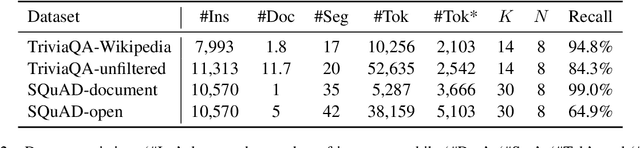
This paper considers the reading comprehension task in which multiple documents are given as input. Prior work has shown that a pipeline of retriever, reader, and reranker can improve the overall performance. However, the pipeline system is inefficient since the input is re-encoded within each module, and is unable to leverage upstream components to help downstream training. In this work, we present RE$^3$QA, a unified question answering model that combines context retrieving, reading comprehension, and answer reranking to predict the final answer. Unlike previous pipelined approaches, RE$^3$QA shares contextualized text representation across different components, and is carefully designed to use high-quality upstream outputs (e.g., retrieved context or candidate answers) for directly supervising downstream modules (e.g., the reader or the reranker). As a result, the whole network can be trained end-to-end to avoid the context inconsistency problem. Experiments show that our model outperforms the pipelined baseline and achieves state-of-the-art results on two versions of TriviaQA and two variants of SQuAD.
Open-Domain Targeted Sentiment Analysis via Span-Based Extraction and Classification
Jun 10, 2019
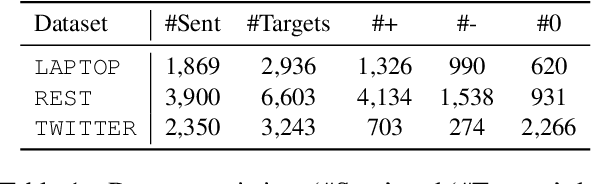


Open-domain targeted sentiment analysis aims to detect opinion targets along with their sentiment polarities from a sentence. Prior work typically formulates this task as a sequence tagging problem. However, such formulation suffers from problems such as huge search space and sentiment inconsistency. To address these problems, we propose a span-based extract-then-classify framework, where multiple opinion targets are directly extracted from the sentence under the supervision of target span boundaries, and corresponding polarities are then classified using their span representations. We further investigate three approaches under this framework, namely the pipeline, joint, and collapsed models. Experiments on three benchmark datasets show that our approach consistently outperforms the sequence tagging baseline. Moreover, we find that the pipeline model achieves the best performance compared with the other two models.
Attention-Guided Answer Distillation for Machine Reading Comprehension
Sep 17, 2018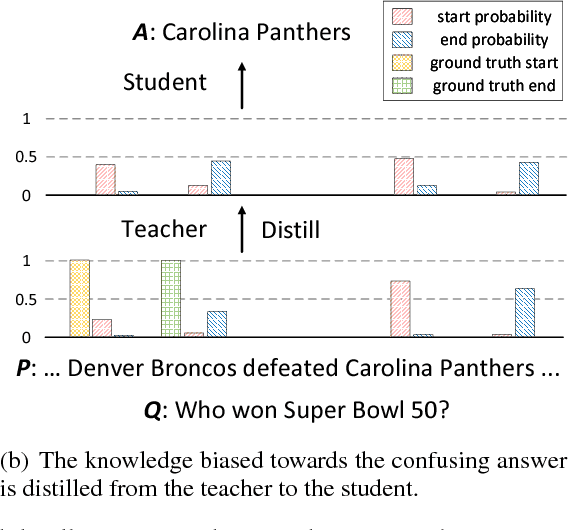

Despite that current reading comprehension systems have achieved significant advancements, their promising performances are often obtained at the cost of making an ensemble of numerous models. Besides, existing approaches are also vulnerable to adversarial attacks. This paper tackles these problems by leveraging knowledge distillation, which aims to transfer knowledge from an ensemble model to a single model. We first demonstrate that vanilla knowledge distillation applied to answer span prediction is effective for reading comprehension systems. We then propose two novel approaches that not only penalize the prediction on confusing answers but also guide the training with alignment information distilled from the ensemble. Experiments show that our best student model has only a slight drop of 0.4% F1 on the SQuAD test set compared to the ensemble teacher, while running 12x faster during inference. It even outperforms the teacher on adversarial SQuAD datasets and NarrativeQA benchmark.
Read + Verify: Machine Reading Comprehension with Unanswerable Questions
Sep 05, 2018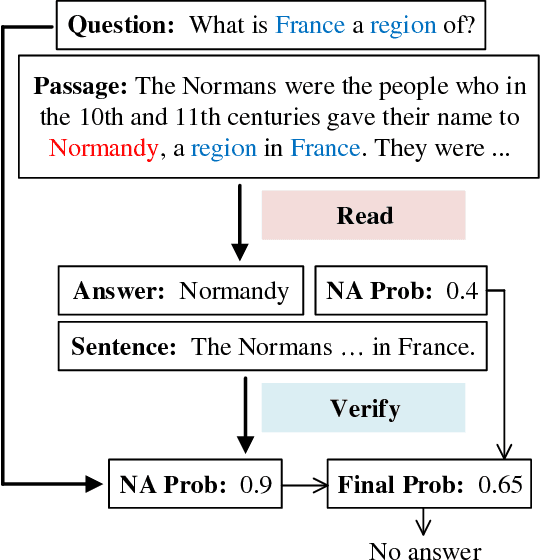
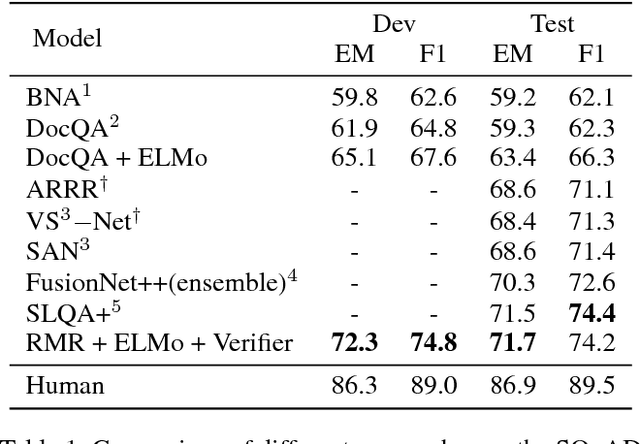
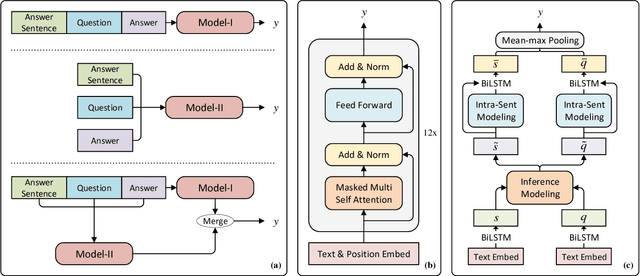
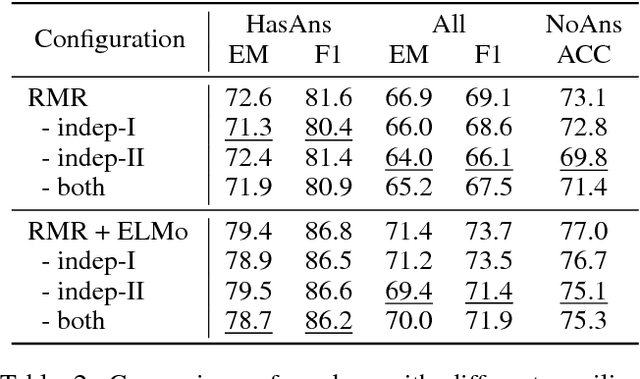
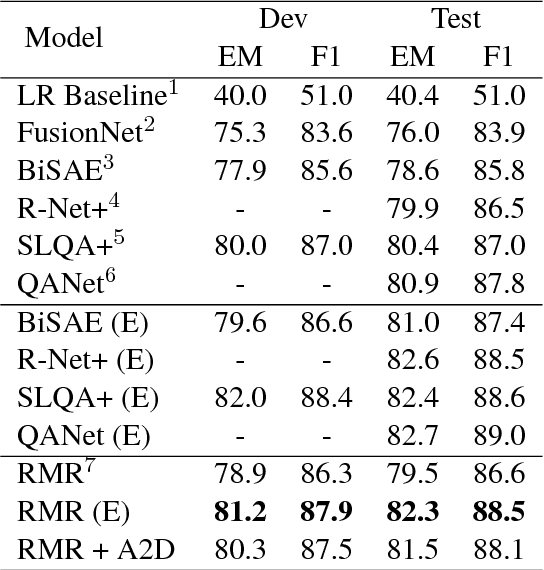
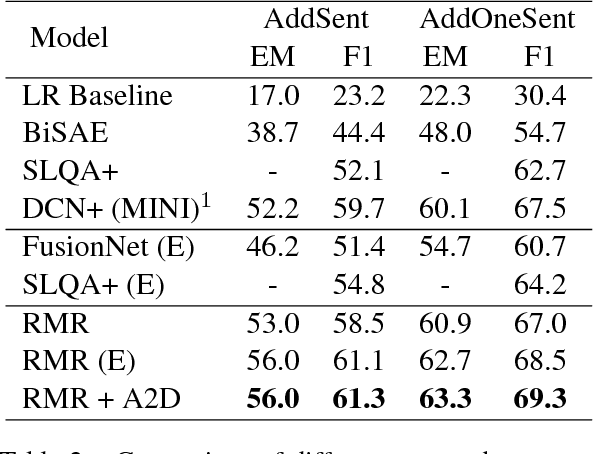
Machine reading comprehension with unanswerable questions aims to abstain from answering when no answer can be inferred. In addition to extract answers, previous works usually predict an additional "no-answer" probability to detect unanswerable cases. However, they fail to validate the answerability of the question by verifying the legitimacy of the predicted answer. To address this problem, we propose a novel read-then-verify system, which not only utilizes a neural reader to extract candidate answers and produce no-answer probabilities, but also leverages an answer verifier to decide whether the predicted answer is entailed by the input snippets. Moreover, we introduce two auxiliary losses to help the reader better handle answer extraction as well as no-answer detection, and investigate three different architectures for the answer verifier. Our experiments on the SQuAD 2.0 dataset show that our system achieves a score of 74.2 F1 on the test set, outperforming all previous approaches at the time of submission (Aug. 23th, 2018).