 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking medical vision-language models think causally across modalities with retrieval-augmented cross-modal reasoning
Jan 26, 2026Medical vision-language models (VLMs) achieve strong performance in diagnostic reporting and image-text alignment, yet their underlying reasoning mechanisms remain fundamentally correlational, exhibiting reliance on superficial statistical associations that fail to capture the causal pathophysiological mechanisms central to clinical decision-making. This limitation makes them fragile, prone to hallucinations, and sensitive to dataset biases. Retrieval-augmented generation (RAG) offers a partial remedy by grounding predictions in external knowledge. However, conventional RAG depends on semantic similarity, introducing new spurious correlations. We propose Multimodal Causal Retrieval-Augmented Generation, a framework that integrates causal inference principles with multimodal retrieval. It retrieves clinically relevant exemplars and causal graphs from external sources, conditioning model reasoning on counterfactual and interventional evidence rather than correlations alone. Applied to radiology report generation, diagnosis prediction, and visual question answering, it improves factual accuracy, robustness to distribution shifts, and interpretability. Our results highlight causal retrieval as a scalable path toward medical VLMs that think beyond pattern matching, enabling trustworthy multimodal reasoning in high-stakes clinical settings.
FinMMDocR: Benchmarking Financial Multimodal Reasoning with Scenario Awareness, Document Understanding, and Multi-Step Computation
Dec 31, 2025We introduce FinMMDocR, a novel bilingual multimodal benchmark for evaluating multimodal large language models (MLLMs) on real-world financial numerical reasoning. Compared to existing benchmarks, our work delivers three major advancements. (1) Scenario Awareness: 57.9% of 1,200 expert-annotated problems incorporate 12 types of implicit financial scenarios (e.g., Portfolio Management), challenging models to perform expert-level reasoning based on assumptions; (2) Document Understanding: 837 Chinese/English documents spanning 9 types (e.g., Company Research) average 50.8 pages with rich visual elements, significantly surpassing existing benchmarks in both breadth and depth of financial documents; (3) Multi-Step Computation: Problems demand 11-step reasoning on average (5.3 extraction + 5.7 calculation steps), with 65.0% requiring cross-page evidence (2.4 pages average). The best-performing MLLM achieves only 58.0% accuracy, and different retrieval-augmented generation (RAG) methods show significant performance variations on this task. We expect FinMMDocR to drive improvements in MLLMs and reasoning-enhanced methods on complex multimodal reasoning tasks in real-world scenarios.
Language-Enhanced Mobile Manipulation for Efficient Object Search in Indoor Environments
Aug 28, 2025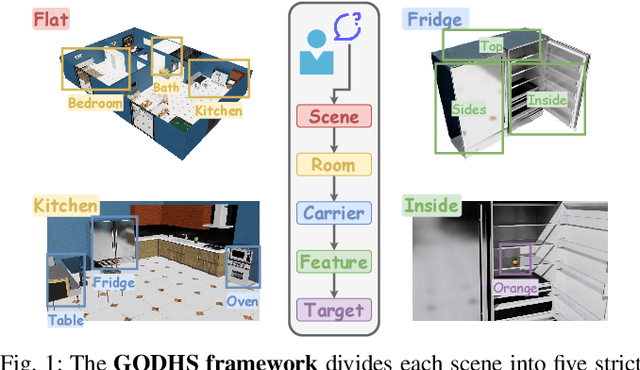
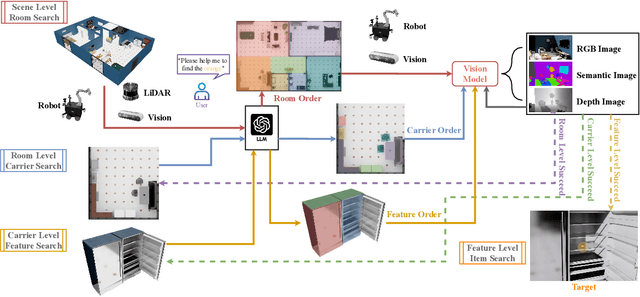
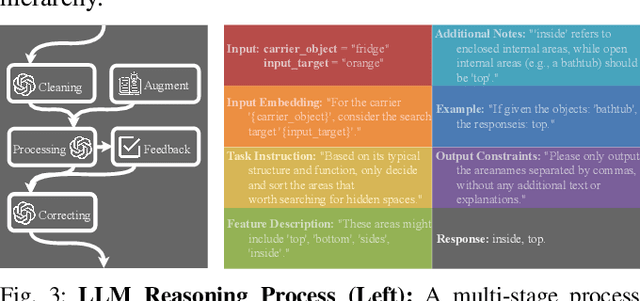

Enabling robots to efficiently search for and identify objects in complex, unstructured environments is critical for diverse applications ranging from household assistance to industrial automation. However, traditional scene representations typically capture only static semantics and lack interpretable contextual reasoning, limiting their ability to guide object search in completely unfamiliar settings. To address this challenge, we propose a language-enhanced hierarchical navigation framework that tightly integrates semantic perception and spatial reasoning. Our method, Goal-Oriented Dynamically Heuristic-Guided Hierarchical Search (GODHS), leverages large language models (LLMs) to infer scene semantics and guide the search process through a multi-level decision hierarchy. Reliability in reasoning is achieved through the use of structured prompts and logical constraints applied at each stage of the hierarchy. For the specific challenges of mobile manipulation, we introduce a heuristic-based motion planner that combines polar angle sorting with distance prioritization to efficiently generate exploration paths. Comprehensive evaluations in Isaac Sim demonstrate the feasibility of our framework, showing that GODHS can locate target objects with higher search efficiency compared to conventional, non-semantic search strategies. Website and Video are available at: https://drapandiger.github.io/GODHS
Human and AI collaboration in Fitness Education:A Longitudinal Study with a Pilates Instructor
Jun 05, 2025Artificial intelligence is poised to transform teaching and coaching practices,yet its optimal role alongside human expertise remains unclear.This study investigates human and AI collaboration in fitness education through a one year qualitative case study with a Pilates instructor.The researcher participated in the instructor classes and conducted biweekly semi structured interviews to explore how generative AI could be integrated into class planning and instruction.
Detecting Sybil Addresses in Blockchain Airdrops: A Subgraph-based Feature Propagation and Fusion Approach
May 14, 2025Sybil attacks pose a significant security threat to blockchain ecosystems, particularly in token airdrop events. This paper proposes a novel sybil address identification method based on subgraph feature extraction lightGBM. The method first constructs a two-layer deep transaction subgraph for each address, then extracts key event operation features according to the lifecycle of sybil addresses, including the time of first transaction, first gas acquisition, participation in airdrop activities, and last transaction. These temporal features effectively capture the consistency of sybil address behavior operations. Additionally, the method extracts amount and network structure features, comprehensively describing address behavior patterns and network topology through feature propagation and fusion. Experiments conducted on a dataset containing 193,701 addresses (including 23,240 sybil addresses) show that this method outperforms existing approaches in terms of precision, recall, F1 score, and AUC, with all metrics exceeding 0.9. The methods and results of this study can be further applied to broader blockchain security areas such as transaction manipulation identification and token liquidity risk assessment, contributing to the construction of a more secure and fair blockchain ecosystem.
BIGCity: A Universal Spatiotemporal Model for Unified Trajectory and Traffic State Data Analysis
Dec 01, 2024



Typical dynamic ST data includes trajectory data (representing individual-level mobility) and traffic state data (representing population-level mobility). Traditional studies often treat trajectory and traffic state data as distinct, independent modalities, each tailored to specific tasks within a single modality. However, real-world applications, such as navigation apps, require joint analysis of trajectory and traffic state data. Treating these data types as two separate domains can lead to suboptimal model performance. Although recent advances in ST data pre-training and ST foundation models aim to develop universal models for ST data analysis, most existing models are "multi-task, solo-data modality" (MTSM), meaning they can handle multiple tasks within either trajectory data or traffic state data, but not both simultaneously. To address this gap, this paper introduces BIGCity, the first multi-task, multi-data modality (MTMD) model for ST data analysis. The model targets two key challenges in designing an MTMD ST model: (1) unifying the representations of different ST data modalities, and (2) unifying heterogeneous ST analysis tasks. To overcome the first challenge, BIGCity introduces a novel ST-unit that represents both trajectories and traffic states in a unified format. Additionally, for the second challenge, BIGCity adopts a tunable large model with ST task-oriented prompt, enabling it to perform a range of heterogeneous tasks without the need for fine-tuning. Extensive experiments on real-world datasets demonstrate that BIGCity achieves state-of-the-art performance across 8 tasks, outperforming 18 baselines. To the best of our knowledge, BIGCity is the first model capable of handling both trajectories and traffic states for diverse heterogeneous tasks. Our code are available at https://github.com/bigscity/BIGCity
The application of GPT-4 in grading design university students' assignment and providing feedback: An exploratory study
Sep 26, 2024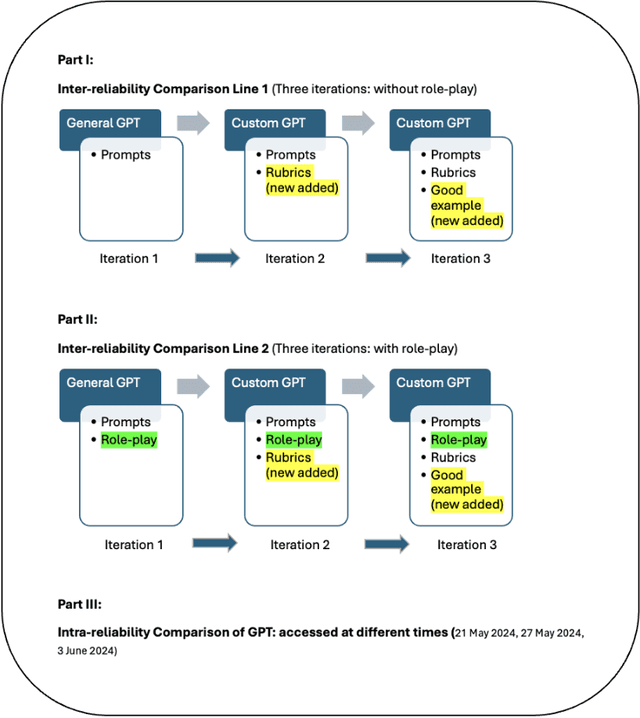



This study aims to investigate whether GPT-4 can effectively grade assignments for design university students and provide useful feedback. In design education, assignments do not have a single correct answer and often involve solving an open-ended design problem. This subjective nature of design projects often leads to grading problems,as grades can vary between different raters,for instance instructor from engineering background or architecture background. This study employs an iterative research approach in developing a Custom GPT with the aim of achieving more reliable results and testing whether it can provide design students with constructive feedback. The findings include: First,through several rounds of iterations the inter-reliability between GPT and human raters reached a level that is generally accepted by educators. This indicates that by providing accurate prompts to GPT,and continuously iterating to build a Custom GPT, it can be used to effectively grade students' design assignments, serving as a reliable complement to human raters. Second, the intra-reliability of GPT's scoring at different times is between 0.65 and 0.78. This indicates that, with adequate instructions, a Custom GPT gives consistent results which is a precondition for grading students. As consistency and comparability are the two main rules to ensure the reliability of educational assessment, this study has looked at whether a Custom GPT can be developed that adheres to these two rules. We finish the paper by testing whether Custom GPT can provide students with useful feedback and reflecting on how educators can develop and iterate a Custom GPT to serve as a complementary rater.
Exploring the Use of ChatGPT for a Systematic Literature Review: a Design-Based Research
Sep 25, 2024ChatGPT has been used in several educational contexts,including learning, teaching and research. It also has potential to conduct the systematic literature review (SLR). However, there are limited empirical studies on how to use ChatGPT in conducting a SLR. Based on a SLR published,this study used ChatGPT to conduct a SLR of the same 33 papers in a design-based approach, to see what the differences are by comparing the reviews' results,and to answer: To what extent can ChatGPT conduct SLR? What strategies can human researchers utilize to structure prompts for ChatGPT that enhance the reliability and validity of a SLR? This study found that ChatGPT could conduct a SLR. It needs detailed and accurate prompts to analyze the literature. It also has limitations. Guiding principles are summarized from this study for researchers to follow when they need to conduct SLRs using ChatGPT.
KAN-HyperpointNet for Point Cloud Sequence-Based 3D Human Action Recognition
Sep 14, 2024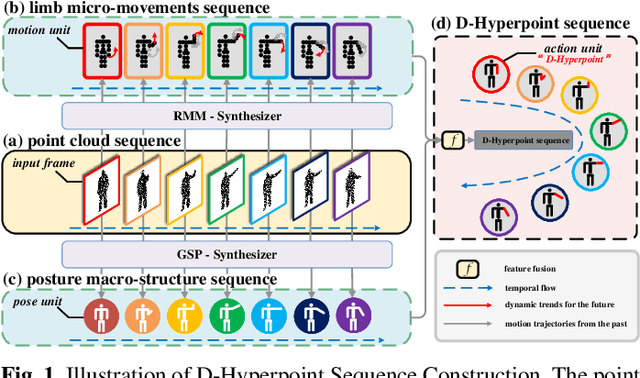
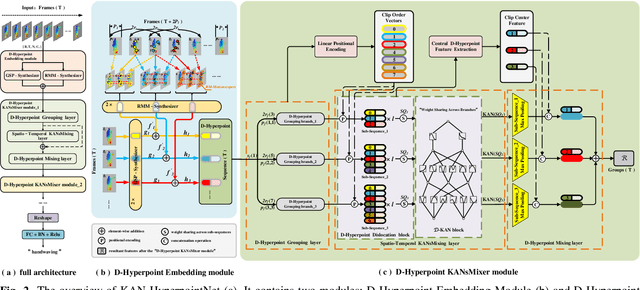
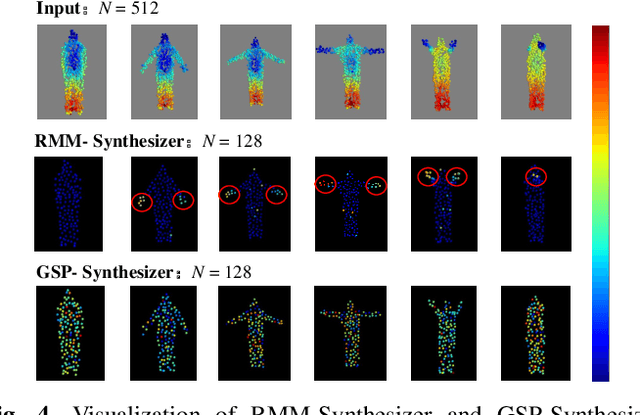
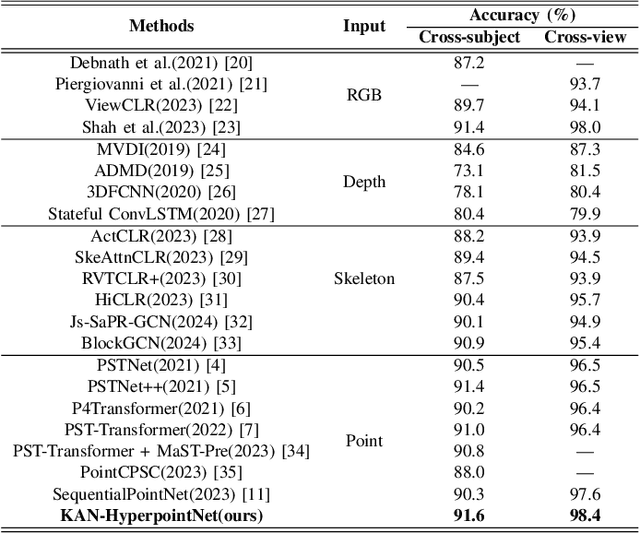
Point cloud sequence-based 3D action recognition has achieved impressive performance and efficiency. However, existing point cloud sequence modeling methods cannot adequately balance the precision of limb micro-movements with the integrity of posture macro-structure, leading to the loss of crucial information cues in action inference. To overcome this limitation, we introduce D-Hyperpoint, a novel data type generated through a D-Hyperpoint Embedding module. D-Hyperpoint encapsulates both regional-momentary motion and global-static posture, effectively summarizing the unit human action at each moment. In addition, we present a D-Hyperpoint KANsMixer module, which is recursively applied to nested groupings of D-Hyperpoints to learn the action discrimination information and creatively integrates Kolmogorov-Arnold Networks (KAN) to enhance spatio-temporal interaction within D-Hyperpoints. Finally, we propose KAN-HyperpointNet, a spatio-temporal decoupled network architecture for 3D action recognition. Extensive experiments on two public datasets: MSR Action3D and NTU-RGB+D 60, demonstrate the state-of-the-art performance of our method.
AvaTaR: Optimizing LLM Agents for Tool-Assisted Knowledge Retrieval
Jun 18, 2024



Large language model (LLM) agents have demonstrated impressive capability in utilizing external tools and knowledge to boost accuracy and reduce hallucinations. However, developing the prompting techniques that make LLM agents able to effectively use external tools and knowledge is a heuristic and laborious task. Here, we introduce AvaTaR, a novel and automatic framework that optimizes an LLM agent to effectively use the provided tools and improve its performance on a given task/domain. During optimization, we design a comparator module to iteratively provide insightful and holistic prompts to the LLM agent via reasoning between positive and negative examples sampled from training data. We demonstrate AvaTaR on four complex multimodal retrieval datasets featuring textual, visual, and relational information. We find AvaTaR consistently outperforms state-of-the-art approaches across all four challenging tasks and exhibits strong generalization ability when applied to novel cases, achieving an average relative improvement of 14% on the Hit@1 metric. Code and dataset are available at https://github.com/zou-group/avatar.