 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman and AI collaboration in Fitness Education:A Longitudinal Study with a Pilates Instructor
Jun 05, 2025Artificial intelligence is poised to transform teaching and coaching practices,yet its optimal role alongside human expertise remains unclear.This study investigates human and AI collaboration in fitness education through a one year qualitative case study with a Pilates instructor.The researcher participated in the instructor classes and conducted biweekly semi structured interviews to explore how generative AI could be integrated into class planning and instruction.
Assessing employment and labour issues implicated by using AI
Apr 08, 2025This chapter critiques the dominant reductionist approach in AI and work studies, which isolates tasks and skills as replaceable components. Instead, it advocates for a systemic perspective that emphasizes the interdependence of tasks, roles, and workplace contexts. Two complementary approaches are proposed: an ethnographic, context-rich method that highlights how AI reconfigures work environments and expertise; and a relational task-based analysis that bridges micro-level work descriptions with macro-level labor trends. The authors argue that effective AI impact assessments must go beyond predicting automation rates to include ethical, well-being, and expertise-related questions. Drawing on empirical case studies, they demonstrate how AI reshapes human-technology relations, professional roles, and tacit knowledge practices. The chapter concludes by calling for a human-centric, holistic framework that guides organizational and policy decisions, balancing technological possibilities with social desirability and sustainability of work.
The application of GPT-4 in grading design university students' assignment and providing feedback: An exploratory study
Sep 26, 2024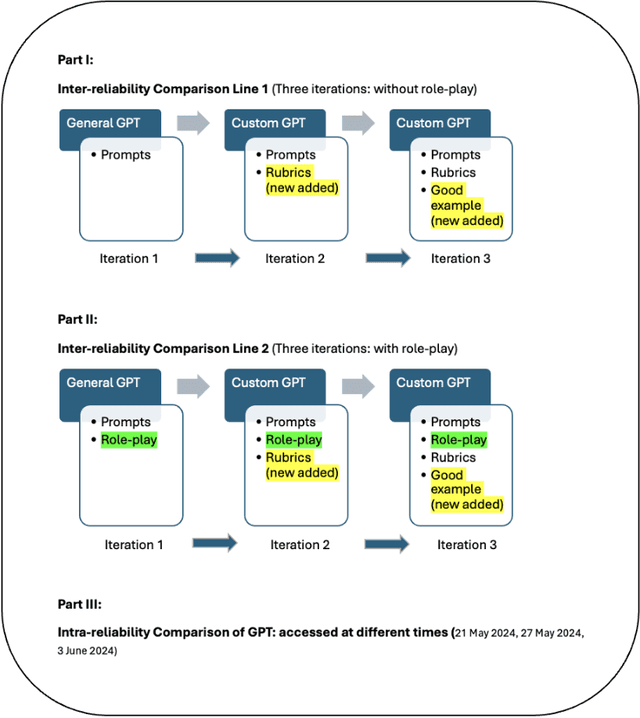



This study aims to investigate whether GPT-4 can effectively grade assignments for design university students and provide useful feedback. In design education, assignments do not have a single correct answer and often involve solving an open-ended design problem. This subjective nature of design projects often leads to grading problems,as grades can vary between different raters,for instance instructor from engineering background or architecture background. This study employs an iterative research approach in developing a Custom GPT with the aim of achieving more reliable results and testing whether it can provide design students with constructive feedback. The findings include: First,through several rounds of iterations the inter-reliability between GPT and human raters reached a level that is generally accepted by educators. This indicates that by providing accurate prompts to GPT,and continuously iterating to build a Custom GPT, it can be used to effectively grade students' design assignments, serving as a reliable complement to human raters. Second, the intra-reliability of GPT's scoring at different times is between 0.65 and 0.78. This indicates that, with adequate instructions, a Custom GPT gives consistent results which is a precondition for grading students. As consistency and comparability are the two main rules to ensure the reliability of educational assessment, this study has looked at whether a Custom GPT can be developed that adheres to these two rules. We finish the paper by testing whether Custom GPT can provide students with useful feedback and reflecting on how educators can develop and iterate a Custom GPT to serve as a complementary rater.