 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLJP: Legal Judgment Prediction via First-Order Logic Rule-enhanced with Large Language Models
May 27, 2025Legal Judgment Prediction (LJP) is a pivotal task in legal AI. Existing semantic-enhanced LJP models integrate judicial precedents and legal knowledge for high performance. But they neglect legal reasoning logic, a critical component of legal judgments requiring rigorous logical analysis. Although some approaches utilize legal reasoning logic for high-quality predictions, their logic rigidity hinders adaptation to case-specific logical frameworks, particularly in complex cases that are lengthy and detailed. This paper proposes a rule-enhanced legal judgment prediction framework based on first-order logic (FOL) formalism and comparative learning (CL) to develop an adaptive adjustment mechanism for legal judgment logic and further enhance performance in LJP. Inspired by the process of human exam preparation, our method follows a three-stage approach: first, we initialize judgment rules using the FOL formalism to capture complex reasoning logic accurately; next, we propose a Confusion-aware Contrastive Learning (CACL) to dynamically optimize the judgment rules through a quiz consisting of confusable cases; finally, we utilize the optimized judgment rules to predict legal judgments. Experimental results on two public datasets show superior performance across all metrics. The code is publicly available{https://anonymous.4open.science/r/RLJP-FDF1}.
RGB-Event based Pedestrian Attribute Recognition: A Benchmark Dataset and An Asymmetric RWKV Fusion Framework
Apr 14, 2025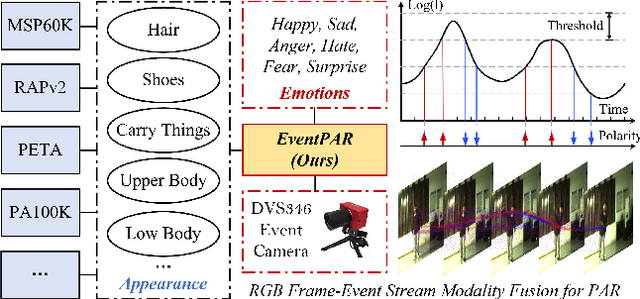
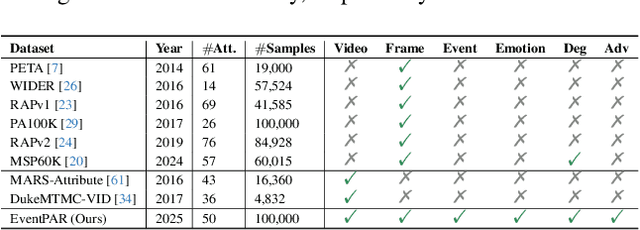

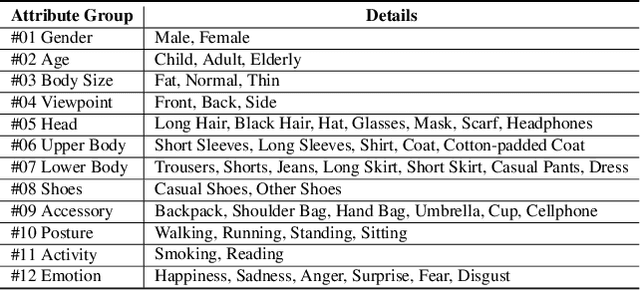
Existing pedestrian attribute recognition methods are generally developed based on RGB frame cameras. However, these approaches are constrained by the limitations of RGB cameras, such as sensitivity to lighting conditions and motion blur, which hinder their performance. Furthermore, current attribute recognition primarily focuses on analyzing pedestrians' external appearance and clothing, lacking an exploration of emotional dimensions. In this paper, we revisit these issues and propose a novel multi-modal RGB-Event attribute recognition task by drawing inspiration from the advantages of event cameras in low-light, high-speed, and low-power consumption. Specifically, we introduce the first large-scale multi-modal pedestrian attribute recognition dataset, termed EventPAR, comprising 100K paired RGB-Event samples that cover 50 attributes related to both appearance and six human emotions, diverse scenes, and various seasons. By retraining and evaluating mainstream PAR models on this dataset, we establish a comprehensive benchmark and provide a solid foundation for future research in terms of data and algorithmic baselines. In addition, we propose a novel RWKV-based multi-modal pedestrian attribute recognition framework, featuring an RWKV visual encoder and an asymmetric RWKV fusion module. Extensive experiments are conducted on our proposed dataset as well as two simulated datasets (MARS-Attribute and DukeMTMC-VID-Attribute), achieving state-of-the-art results. The source code and dataset will be released on https://github.com/Event-AHU/OpenPAR
DeFine: A Decomposed and Fine-Grained Annotated Dataset for Long-form Article Generation
Mar 10, 2025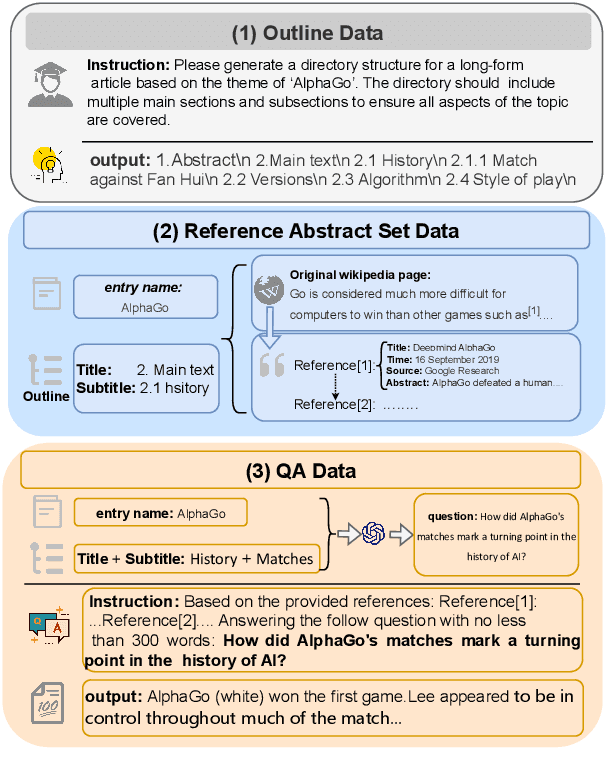
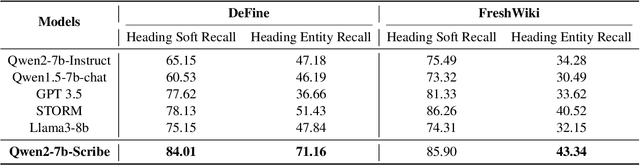
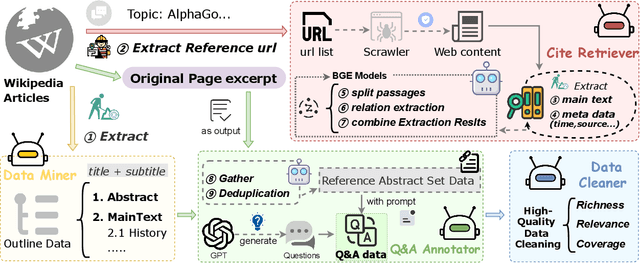
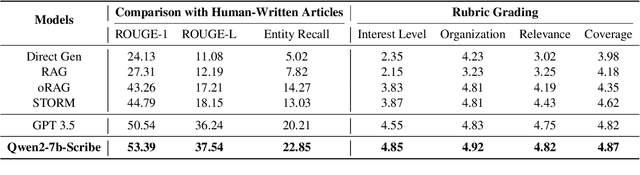
Long-form article generation (LFAG) presents challenges such as maintaining logical consistency, comprehensive topic coverage, and narrative coherence across extended articles. Existing datasets often lack both the hierarchical structure and fine-grained annotation needed to effectively decompose tasks, resulting in shallow, disorganized article generation. To address these limitations, we introduce DeFine, a Decomposed and Fine-grained annotated dataset for long-form article generation. DeFine is characterized by its hierarchical decomposition strategy and the integration of domain-specific knowledge with multi-level annotations, ensuring granular control and enhanced depth in article generation. To construct the dataset, a multi-agent collaborative pipeline is proposed, which systematically segments the generation process into four parts: Data Miner, Cite Retreiver, Q&A Annotator and Data Cleaner. To validate the effectiveness of DeFine, we designed and tested three LFAG baselines: the web retrieval, the local retrieval, and the grounded reference. We fine-tuned the Qwen2-7b-Instruct model using the DeFine training dataset. The experimental results showed significant improvements in text quality, specifically in topic coverage, depth of information, and content fidelity. Our dataset publicly available to facilitate future research.
UFO: A Unified Approach to Fine-grained Visual Perception via Open-ended Language Interface
Mar 04, 2025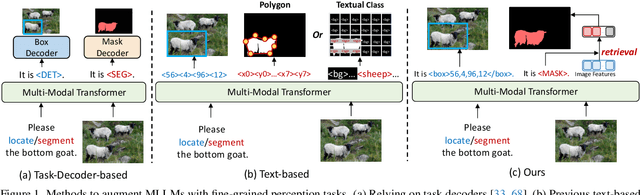
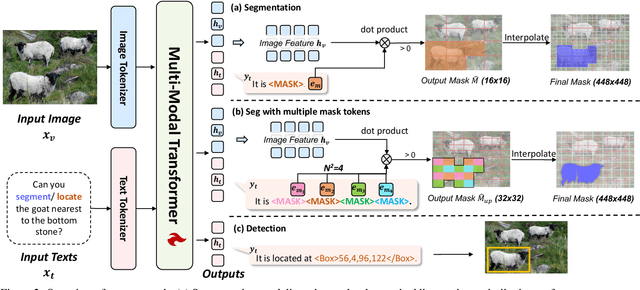
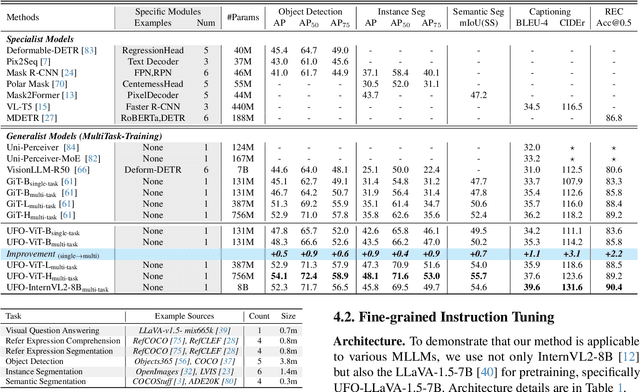
Generalist models have achieved remarkable success in both language and vision-language tasks, showcasing the potential of unified modeling. However, effectively integrating fine-grained perception tasks like detection and segmentation into these models remains a significant challenge. This is primarily because these tasks often rely heavily on task-specific designs and architectures that can complicate the modeling process. To address this challenge, we present \ours, a framework that \textbf{U}nifies \textbf{F}ine-grained visual perception tasks through an \textbf{O}pen-ended language interface. By transforming all perception targets into the language space, \ours unifies object-level detection, pixel-level segmentation, and image-level vision-language tasks into a single model. Additionally, we introduce a novel embedding retrieval approach that relies solely on the language interface to support segmentation tasks. Our framework bridges the gap between fine-grained perception and vision-language tasks, significantly simplifying architectural design and training strategies while achieving comparable or superior performance to methods with intricate task-specific designs. After multi-task training on five standard visual perception datasets, \ours outperforms the previous state-of-the-art generalist models by 12.3 mAP on COCO instance segmentation and 3.3 mIoU on ADE20K semantic segmentation. Furthermore, our method seamlessly integrates with existing MLLMs, effectively combining fine-grained perception capabilities with their advanced language abilities, thereby enabling more challenging tasks such as reasoning segmentation. Code and models are available at https://github.com/nnnth/UFO.
TokenFormer: Rethinking Transformer Scaling with Tokenized Model Parameters
Oct 30, 2024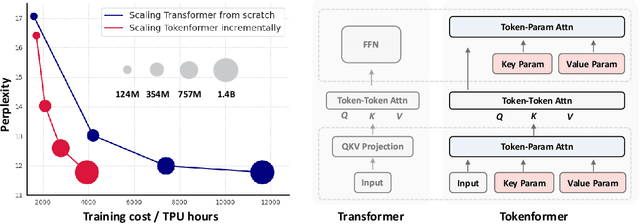
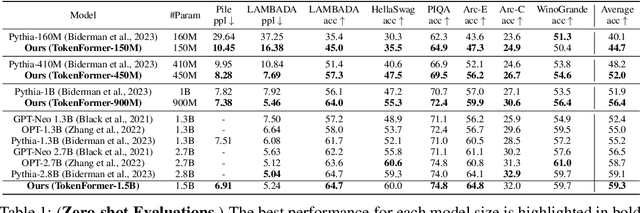
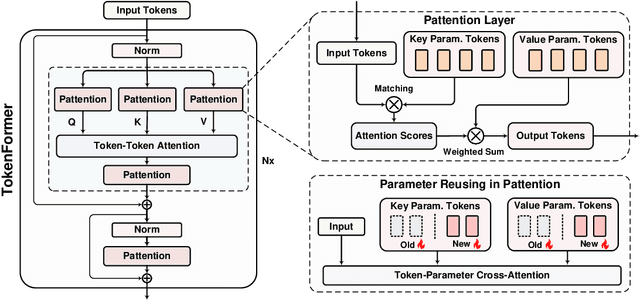
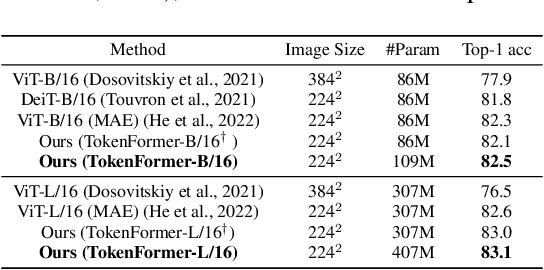
Transformers have become the predominant architecture in foundation models due to their excellent performance across various domains. However, the substantial cost of scaling these models remains a significant concern. This problem arises primarily from their dependence on a fixed number of parameters within linear projections. When architectural modifications (e.g., channel dimensions) are introduced, the entire model typically requires retraining from scratch. As model sizes continue growing, this strategy results in increasingly high computational costs and becomes unsustainable. To overcome this problem, we introduce TokenFormer, a natively scalable architecture that leverages the attention mechanism not only for computations among input tokens but also for interactions between tokens and model parameters, thereby enhancing architectural flexibility. By treating model parameters as tokens, we replace all the linear projections in Transformers with our token-parameter attention layer, where input tokens act as queries and model parameters as keys and values. This reformulation allows for progressive and efficient scaling without necessitating retraining from scratch. Our model scales from 124M to 1.4B parameters by incrementally adding new key-value parameter pairs, achieving performance comparable to Transformers trained from scratch while greatly reducing training costs. Code and models are available at \url{https://github.com/Haiyang-W/TokenFormer}.
SNN-PAR: Energy Efficient Pedestrian Attribute Recognition via Spiking Neural Networks
Oct 10, 2024Artificial neural network based Pedestrian Attribute Recognition (PAR) has been widely studied in recent years, despite many progresses, however, the energy consumption is still high. To address this issue, in this paper, we propose a Spiking Neural Network (SNN) based framework for energy-efficient attribute recognition. Specifically, we first adopt a spiking tokenizer module to transform the given pedestrian image into spiking feature representations. Then, the output will be fed into the spiking Transformer backbone networks for energy-efficient feature extraction. We feed the enhanced spiking features into a set of feed-forward networks for pedestrian attribute recognition. In addition to the widely used binary cross-entropy loss function, we also exploit knowledge distillation from the artificial neural network to the spiking Transformer network for more accurate attribute recognition. Extensive experiments on three widely used PAR benchmark datasets fully validated the effectiveness of our proposed SNN-PAR framework. The source code of this paper is released on \url{https://github.com/Event-AHU/OpenPAR}.
Pedestrian Attribute Recognition: A New Benchmark Dataset and A Large Language Model Augmented Framework
Aug 19, 2024Pedestrian Attribute Recognition (PAR) is one of the indispensable tasks in human-centered research. However, existing datasets neglect different domains (e.g., environments, times, populations, and data sources), only conducting simple random splits, and the performance of these datasets has already approached saturation. In the past five years, no large-scale dataset has been opened to the public. To address this issue, this paper proposes a new large-scale, cross-domain pedestrian attribute recognition dataset to fill the data gap, termed MSP60K. It consists of 60,122 images and 57 attribute annotations across eight scenarios. Synthetic degradation is also conducted to further narrow the gap between the dataset and real-world challenging scenarios. To establish a more rigorous benchmark, we evaluate 17 representative PAR models under both random and cross-domain split protocols on our dataset. Additionally, we propose an innovative Large Language Model (LLM) augmented PAR framework, named LLM-PAR. This framework processes pedestrian images through a Vision Transformer (ViT) backbone to extract features and introduces a multi-embedding query Transformer to learn partial-aware features for attribute classification. Significantly, we enhance this framework with LLM for ensemble learning and visual feature augmentation. Comprehensive experiments across multiple PAR benchmark datasets have thoroughly validated the efficacy of our proposed framework. The dataset and source code accompanying this paper will be made publicly available at \url{https://github.com/Event-AHU/OpenPAR}.
GiT: Towards Generalist Vision Transformer through Universal Language Interface
Mar 14, 2024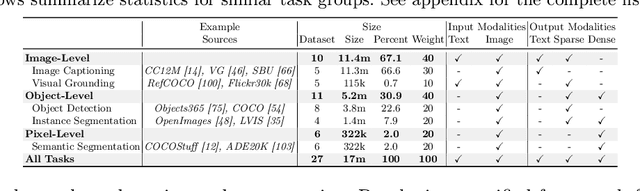

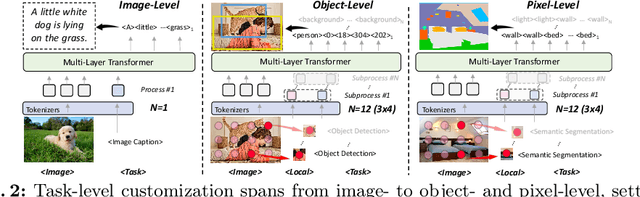
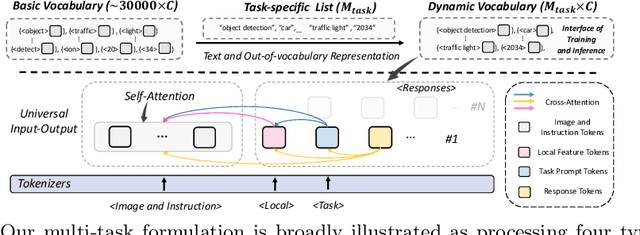
This paper proposes a simple, yet effective framework, called GiT, simultaneously applicable for various vision tasks only with a vanilla ViT. Motivated by the universality of the Multi-layer Transformer architecture (e.g, GPT) widely used in large language models (LLMs), we seek to broaden its scope to serve as a powerful vision foundation model (VFM). However, unlike language modeling, visual tasks typically require specific modules, such as bounding box heads for detection and pixel decoders for segmentation, greatly hindering the application of powerful multi-layer transformers in the vision domain. To solve this, we design a universal language interface that empowers the successful auto-regressive decoding to adeptly unify various visual tasks, from image-level understanding (e.g., captioning), over sparse perception (e.g., detection), to dense prediction (e.g., segmentation). Based on the above designs, the entire model is composed solely of a ViT, without any specific additions, offering a remarkable architectural simplification. GiT is a multi-task visual model, jointly trained across five representative benchmarks without task-specific fine-tuning. Interestingly, our GiT builds a new benchmark in generalist performance, and fosters mutual enhancement across tasks, leading to significant improvements compared to isolated training. This reflects a similar impact observed in LLMs. Further enriching training with 27 datasets, GiT achieves strong zero-shot results over various tasks. Due to its simple design, this paradigm holds promise for narrowing the architectural gap between vision and language. Code and models will be available at \url{https://github.com/Haiyang-W/GiT}.
GSINA: Improving Subgraph Extraction for Graph Invariant Learning via Graph Sinkhorn Attention
Feb 11, 2024Graph invariant learning (GIL) has been an effective approach to discovering the invariant relationships between graph data and its labels for different graph learning tasks under various distribution shifts. Many recent endeavors of GIL focus on extracting the invariant subgraph from the input graph for prediction as a regularization strategy to improve the generalization performance of graph learning. Despite their success, such methods also have various limitations in obtaining their invariant subgraphs. In this paper, we provide in-depth analyses of the drawbacks of existing works and propose corresponding principles of our invariant subgraph extraction: 1) the sparsity, to filter out the variant features, 2) the softness, for a broader solution space, and 3) the differentiability, for a soundly end-to-end optimization. To meet these principles in one shot, we leverage the Optimal Transport (OT) theory and propose a novel graph attention mechanism called Graph Sinkhorn Attention (GSINA). This novel approach serves as a powerful regularization method for GIL tasks. By GSINA, we are able to obtain meaningful, differentiable invariant subgraphs with controllable sparsity and softness. Moreover, GSINA is a general graph learning framework that could handle GIL tasks of multiple data grain levels. Extensive experiments on both synthetic and real-world datasets validate the superiority of our GSINA, which outperforms the state-of-the-art GIL methods by large margins on both graph-level tasks and node-level tasks. Our code is publicly available at \url{https://github.com/dingfangyu/GSINA}.
PRED: Pre-training via Semantic Rendering on LiDAR Point Clouds
Nov 08, 2023Pre-training is crucial in 3D-related fields such as autonomous driving where point cloud annotation is costly and challenging. Many recent studies on point cloud pre-training, however, have overlooked the issue of incompleteness, where only a fraction of the points are captured by LiDAR, leading to ambiguity during the training phase. On the other hand, images offer more comprehensive information and richer semantics that can bolster point cloud encoders in addressing the incompleteness issue inherent in point clouds. Yet, incorporating images into point cloud pre-training presents its own challenges due to occlusions, potentially causing misalignments between points and pixels. In this work, we propose PRED, a novel image-assisted pre-training framework for outdoor point clouds in an occlusion-aware manner. The main ingredient of our framework is a Birds-Eye-View (BEV) feature map conditioned semantic rendering, leveraging the semantics of images for supervision through neural rendering. We further enhance our model's performance by incorporating point-wise masking with a high mask ratio (95%). Extensive experiments demonstrate PRED's superiority over prior point cloud pre-training methods, providing significant improvements on various large-scale datasets for 3D perception tasks. Codes will be available at https://github.com/PRED4pc/PRED.