 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Foundational Generative Model for Breast Ultrasound Image Analysis
Jan 12, 2025



Foundational models have emerged as powerful tools for addressing various tasks in clinical settings. However, their potential development to breast ultrasound analysis remains untapped. In this paper, we present BUSGen, the first foundational generative model specifically designed for breast ultrasound image analysis. Pretrained on over 3.5 million breast ultrasound images, BUSGen has acquired extensive knowledge of breast structures, pathological features, and clinical variations. With few-shot adaptation, BUSGen can generate repositories of realistic and informative task-specific data, facilitating the development of models for a wide range of downstream tasks. Extensive experiments highlight BUSGen's exceptional adaptability, significantly exceeding real-data-trained foundational models in breast cancer screening, diagnosis, and prognosis. In breast cancer early diagnosis, our approach outperformed all board-certified radiologists (n=9), achieving an average sensitivity improvement of 16.5% (P-value<0.0001). Additionally, we characterized the scaling effect of using generated data which was as effective as the collected real-world data for training diagnostic models. Moreover, extensive experiments demonstrated that our approach improved the generalization ability of downstream models. Importantly, BUSGen protected patient privacy by enabling fully de-identified data sharing, making progress forward in secure medical data utilization. An online demo of BUSGen is available at https://aibus.bio.
LarvSeg: Exploring Image Classification Data For Large Vocabulary Semantic Segmentation via Category-wise Attentive Classifier
Jan 12, 2025



Scaling up the vocabulary of semantic segmentation models is extremely challenging because annotating large-scale mask labels is labour-intensive and time-consuming. Recently, language-guided segmentation models have been proposed to address this challenge. However, their performance drops significantly when applied to out-of-distribution categories. In this paper, we propose a new large vocabulary semantic segmentation framework, called LarvSeg. Different from previous works, LarvSeg leverages image classification data to scale the vocabulary of semantic segmentation models as large-vocabulary classification datasets usually contain balanced categories and are much easier to obtain. However, for classification tasks, the category is image-level, while for segmentation we need to predict the label at pixel level. To address this issue, we first propose a general baseline framework to incorporate image-level supervision into the training process of a pixel-level segmentation model, making the trained network perform semantic segmentation on newly introduced categories in the classification data. We then observe that a model trained on segmentation data can group pixel features of categories beyond the training vocabulary. Inspired by this finding, we design a category-wise attentive classifier to apply supervision to the precise regions of corresponding categories to improve the model performance. Extensive experiments demonstrate that LarvSeg significantly improves the large vocabulary semantic segmentation performance, especially in the categories without mask labels. For the first time, we provide a 21K-category semantic segmentation model with the help of ImageNet21K. The code is available at https://github.com/HaojunYu1998/large_voc_seg.
Knowledge-driven AI-generated data for accurate and interpretable breast ultrasound diagnoses
Jul 23, 2024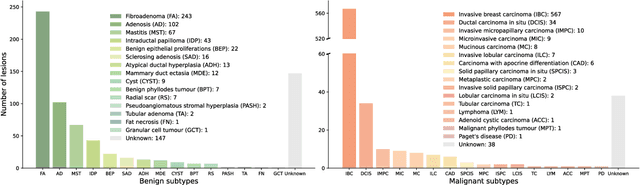
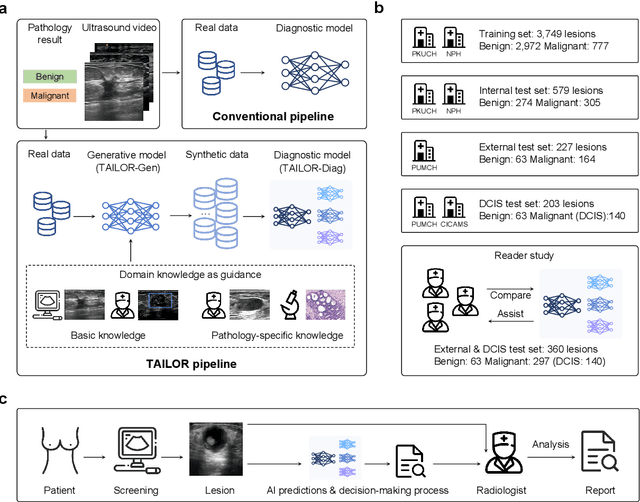
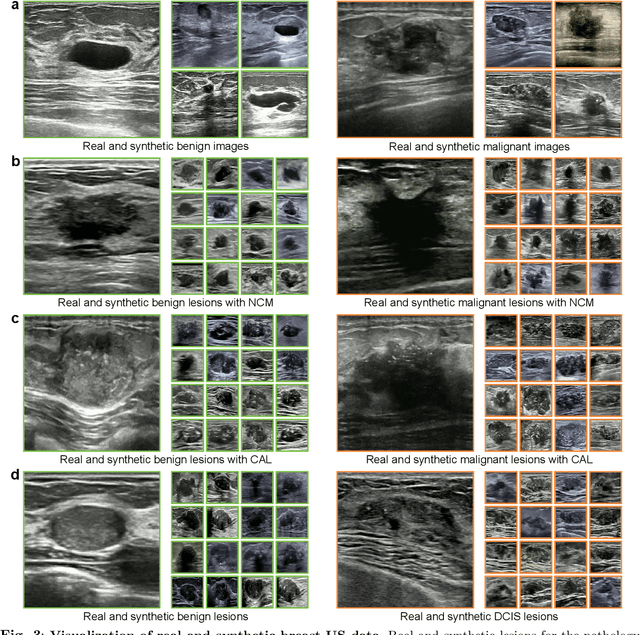
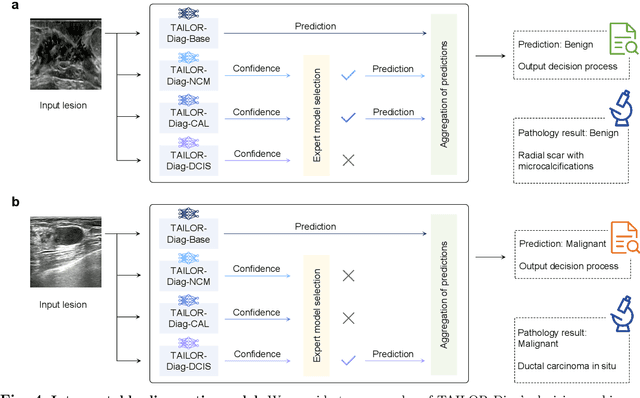
Data-driven deep learning models have shown great capabilities to assist radiologists in breast ultrasound (US) diagnoses. However, their effectiveness is limited by the long-tail distribution of training data, which leads to inaccuracies in rare cases. In this study, we address a long-standing challenge of improving the diagnostic model performance on rare cases using long-tailed data. Specifically, we introduce a pipeline, TAILOR, that builds a knowledge-driven generative model to produce tailored synthetic data. The generative model, using 3,749 lesions as source data, can generate millions of breast-US images, especially for error-prone rare cases. The generated data can be further used to build a diagnostic model for accurate and interpretable diagnoses. In the prospective external evaluation, our diagnostic model outperforms the average performance of nine radiologists by 33.5% in specificity with the same sensitivity, improving their performance by providing predictions with an interpretable decision-making process. Moreover, on ductal carcinoma in situ (DCIS), our diagnostic model outperforms all radiologists by a large margin, with only 34 DCIS lesions in the source data. We believe that TAILOR can potentially be extended to various diseases and imaging modalities.
PRED: Pre-training via Semantic Rendering on LiDAR Point Clouds
Nov 08, 2023Pre-training is crucial in 3D-related fields such as autonomous driving where point cloud annotation is costly and challenging. Many recent studies on point cloud pre-training, however, have overlooked the issue of incompleteness, where only a fraction of the points are captured by LiDAR, leading to ambiguity during the training phase. On the other hand, images offer more comprehensive information and richer semantics that can bolster point cloud encoders in addressing the incompleteness issue inherent in point clouds. Yet, incorporating images into point cloud pre-training presents its own challenges due to occlusions, potentially causing misalignments between points and pixels. In this work, we propose PRED, a novel image-assisted pre-training framework for outdoor point clouds in an occlusion-aware manner. The main ingredient of our framework is a Birds-Eye-View (BEV) feature map conditioned semantic rendering, leveraging the semantics of images for supervision through neural rendering. We further enhance our model's performance by incorporating point-wise masking with a high mask ratio (95%). Extensive experiments demonstrate PRED's superiority over prior point cloud pre-training methods, providing significant improvements on various large-scale datasets for 3D perception tasks. Codes will be available at https://github.com/PRED4pc/PRED.