 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Large-scale Single-shot Millimeter-wave Imaging for Low-cost Security Inspection
May 25, 2023Millimeter-wave (MMW) imaging is emerging as a promising technique for safe security inspection. It achieves a delicate balance between imaging resolution, penetrability and human safety, resulting in higher resolution compared to low-frequency microwave, stronger penetrability compared to visible light, and stronger safety compared to X ray. Despite of recent advance in the last decades, the high cost of requisite large-scale antenna array hinders widespread adoption of MMW imaging in practice. To tackle this challenge, we report a large-scale single-shot MMW imaging framework using sparse antenna array, achieving low-cost but high-fidelity security inspection under an interpretable learning scheme. We first collected extensive full-sampled MMW echoes to study the statistical ranking of each element in the large-scale array. These elements are then sampled based on the ranking, building the experimentally optimal sparse sampling strategy that reduces the cost of antenna array by up to one order of magnitude. Additionally, we derived an untrained interpretable learning scheme, which realizes robust and accurate image reconstruction from sparsely sampled echoes. Last, we developed a neural network for automatic object detection, and experimentally demonstrated successful detection of concealed centimeter-sized targets using 10% sparse array, whereas all the other contemporary approaches failed at the same sample sampling ratio. The performance of the reported technique presents higher than 50% superiority over the existing MMW imaging schemes on various metrics including precision, recall, and mAP50. With such strong detection ability and order-of-magnitude cost reduction, we anticipate that this technique provides a practical way for large-scale single-shot MMW imaging, and could advocate its further practical applications.
Large-scale Global Low-rank Optimization for Computational Compressed Imaging
Jan 08, 2023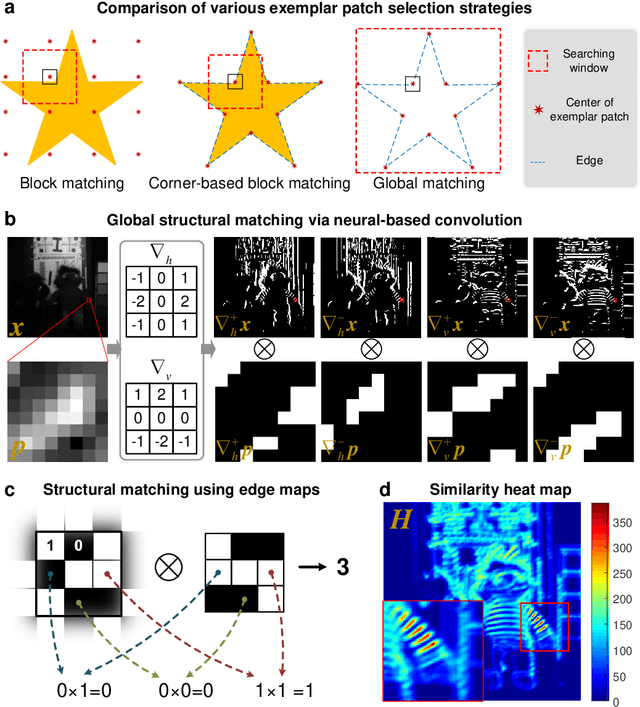
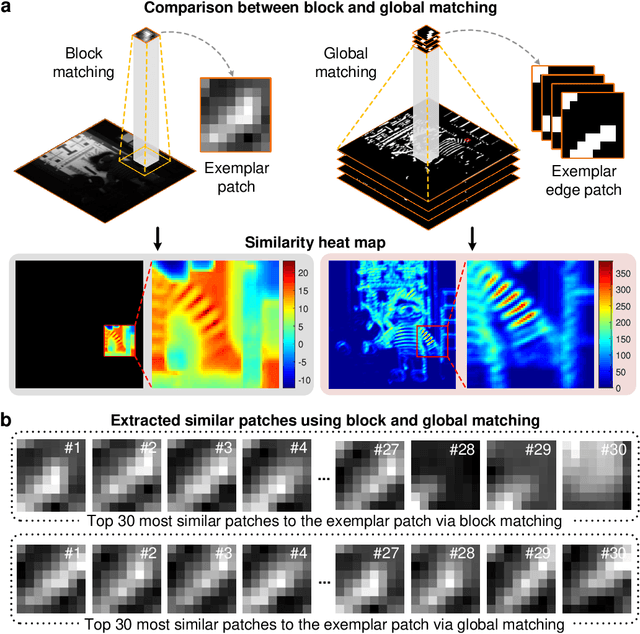
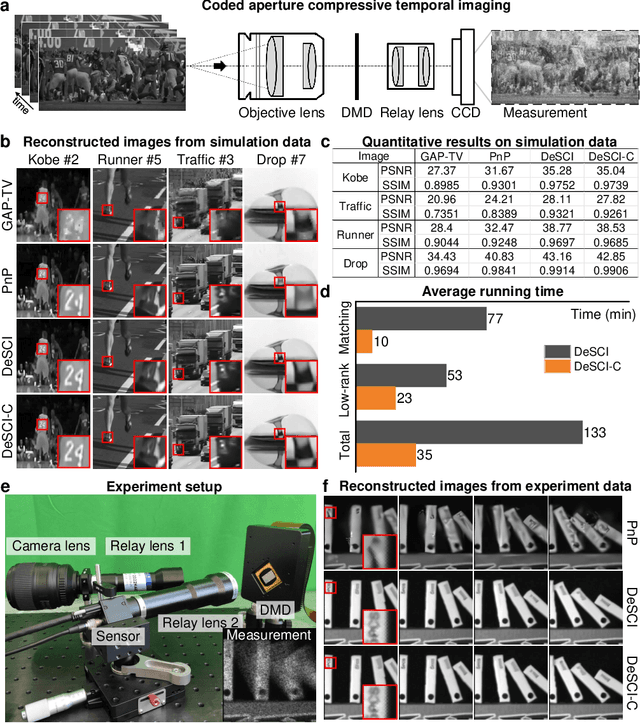
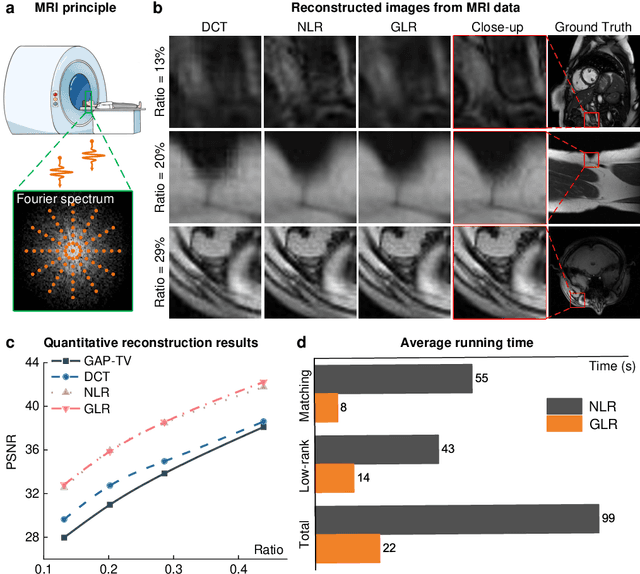
Computational reconstruction plays a vital role in computer vision and computational photography. Most of the conventional optimization and deep learning techniques explore local information for reconstruction. Recently, nonlocal low-rank (NLR) reconstruction has achieved remarkable success in improving accuracy and generalization. However, the computational cost has inhibited NLR from seeking global structural similarity, which consequentially keeps it trapped in the tradeoff between accuracy and efficiency and prevents it from high-dimensional large-scale tasks. To address this challenge, we report here the global low-rank (GLR) optimization technique, realizing highly-efficient large-scale reconstruction with global self-similarity. Inspired by the self-attention mechanism in deep learning, GLR extracts exemplar image patches by feature detection instead of conventional uniform selection. This directly produces key patches using structural features to avoid burdensome computational redundancy. Further, it performs patch matching across the entire image via neural-based convolution, which produces the global similarity heat map in parallel, rather than conventional sequential block-wise matching. As such, GLR improves patch grouping efficiency by more than one order of magnitude. We experimentally demonstrate GLR's effectiveness on temporal, frequency, and spectral dimensions, including different computational imaging modalities of compressive temporal imaging, magnetic resonance imaging, and multispectral filter array demosaicing. This work presents the superiority of inherent fusion of deep learning strategies and iterative optimization, and breaks the persistent dilemma of the tradeoff between accuracy and efficiency for various large-scale reconstruction tasks.
Affine-modeled video extraction from a single motion blurred image
Apr 08, 2021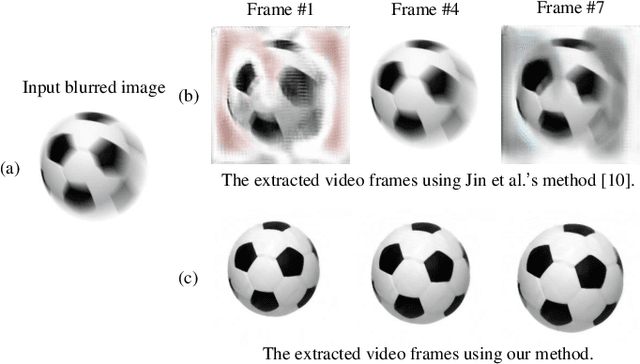
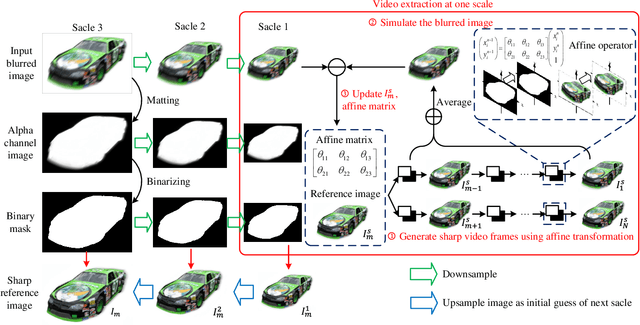


A motion-blurred image is the temporal average of multiple sharp frames over the exposure time. Recovering these sharp video frames from a single blurred image is nontrivial, due to not only its strong ill-posedness, but also various types of complex motion in reality such as rotation and motion in depth. In this work, we report a generalized video extraction method using the affine motion modeling, enabling to tackle multiple types of complex motion and their mixing. In its workflow, the moving objects are first segemented in the alpha channel. This allows separate recovery of different objects with different motion. Then, we reduce the variable space by modeling each video clip as a series of affine transformations of a reference frame, and introduce the $l0$-norm total variation regularization to attenuate the ringing artifact. The differentiable affine operators are employed to realize gradient-descent optimization of the affine model, which follows a novel coarse-to-fine strategy to further reduce artifacts. As a result, both the affine parameters and sharp reference image are retrieved. They are finally input into stepwise affine transformation to recover the sharp video frames. The stepwise retrieval maintains the nature to bypass the frame order ambiguity. Experiments on both public datasets and real captured data validate the state-of-the-art performance of the reported technique.