 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial-Temporal Transformer for Video Snapshot Compressive Imaging
Paper and Code
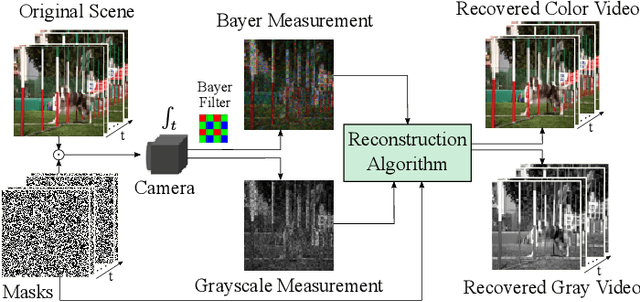
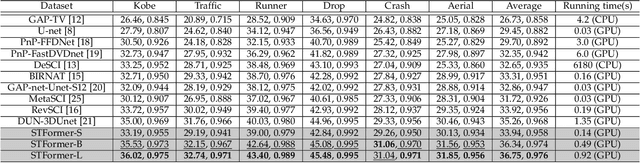
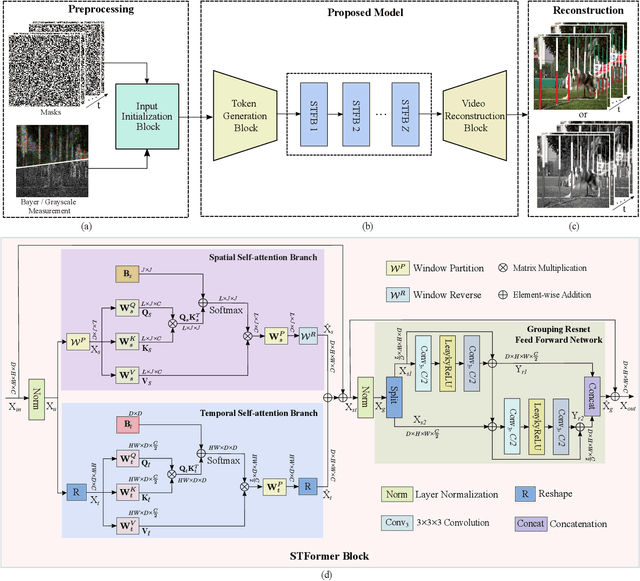
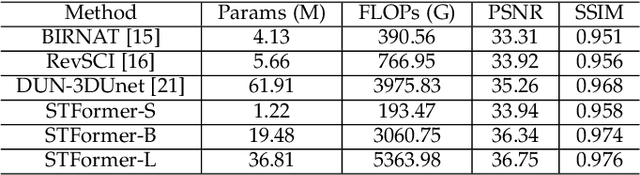
Video snapshot compressive imaging (SCI) captures multiple sequential video frames by a single measurement using the idea of computational imaging. The underlying principle is to modulate high-speed frames through different masks and these modulated frames are summed to a single measurement captured by a low-speed 2D sensor (dubbed optical encoder); following this, algorithms are employed to reconstruct the desired high-speed frames (dubbed software decoder) if needed. In this paper, we consider the reconstruction algorithm in video SCI, i.e., recovering a series of video frames from a compressed measurement. Specifically, we propose a Spatial-Temporal transFormer (STFormer) to exploit the correlation in both spatial and temporal domains. STFormer network is composed of a token generation block, a video reconstruction block, and these two blocks are connected by a series of STFormer blocks. Each STFormer block consists of a spatial self-attention branch, a temporal self-attention branch and the outputs of these two branches are integrated by a fusion network. Extensive results on both simulated and real data demonstrate the state-of-the-art performance of STFormer. The code and models are publicly available at https://github.com/ucaswangls/STFormer.git