 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniDex: A Robot Foundation Suite for Universal Dexterous Hand Control from Egocentric Human Videos
Mar 23, 2026Dexterous manipulation remains challenging due to the cost of collecting real-robot teleoperation data, the heterogeneity of hand embodiments, and the high dimensionality of control. We present UniDex, a robot foundation suite that couples a large-scale robot-centric dataset with a unified vision-language-action (VLA) policy and a practical human-data capture setup for universal dexterous hand control. First, we construct UniDex-Dataset, a robot-centric dataset over 50K trajectories across eight dexterous hands (6--24 DoFs), derived from egocentric human video datasets. To transform human data into robot-executable trajectories, we employ a human-in-the-loop retargeting procedure to align fingertip trajectories while preserving plausible hand-object contacts, and we operate on explicit 3D pointclouds with human hands masked to narrow kinematic and visual gaps. Second, we introduce the Function-Actuator-Aligned Space (FAAS), a unified action space that maps functionally similar actuators to shared coordinates, enabling cross-hand transfer. Leveraging FAAS as the action parameterization, we train UniDex-VLA, a 3D VLA policy pretrained on UniDex-Dataset and finetuned with task demonstrations. In addition, we build UniDex-Cap, a simple portable capture setup that records synchronized RGB-D streams and human hand poses and converts them into robot-executable trajectories to enable human-robot data co-training that reduces reliance on costly robot demonstrations. On challenging tool-use tasks across two different hands, UniDex-VLA achieves 81% average task progress and outperforms prior VLA baselines by a large margin, while exhibiting strong spatial, object, and zero-shot cross-hand generalization. Together, UniDex-Dataset, UniDex-VLA, and UniDex-Cap provide a scalable foundation suite for universal dexterous manipulation.
X-Distill: Cross-Architecture Vision Distillation for Visuomotor Learning
Jan 16, 2026Visuomotor policies often leverage large pre-trained Vision Transformers (ViTs) for their powerful generalization capabilities. However, their significant data requirements present a major challenge in the data-scarce context of most robotic learning settings, where compact CNNs with strong inductive biases can be more easily optimized. To address this trade-off, we introduce X-Distill, a simple yet highly effective method that synergizes the strengths of both architectures. Our approach involves an offline, cross-architecture knowledge distillation, transferring the rich visual representations of a large, frozen DINOv2 teacher to a compact ResNet-18 student on the general-purpose ImageNet dataset. This distilled encoder, now endowed with powerful visual priors, is then jointly fine-tuned with a diffusion policy head on the target manipulation tasks. Extensive experiments on $34$ simulated benchmarks and $5$ challenging real-world tasks demonstrate that our method consistently outperforms policies equipped with from-scratch ResNet or fine-tuned DINOv2 encoders. Notably, X-Distill also surpasses 3D encoders that utilize privileged point cloud observations or much larger Vision-Language Models. Our work highlights the efficacy of a simple, well-founded distillation strategy for achieving state-of-the-art performance in data-efficient robotic manipulation.
Reactive Diffusion Policy: Slow-Fast Visual-Tactile Policy Learning for Contact-Rich Manipulation
Mar 04, 2025Humans can accomplish complex contact-rich tasks using vision and touch, with highly reactive capabilities such as quick adjustments to environmental changes and adaptive control of contact forces; however, this remains challenging for robots. Existing visual imitation learning (IL) approaches rely on action chunking to model complex behaviors, which lacks the ability to respond instantly to real-time tactile feedback during the chunk execution. Furthermore, most teleoperation systems struggle to provide fine-grained tactile / force feedback, which limits the range of tasks that can be performed. To address these challenges, we introduce TactAR, a low-cost teleoperation system that provides real-time tactile feedback through Augmented Reality (AR), along with Reactive Diffusion Policy (RDP), a novel slow-fast visual-tactile imitation learning algorithm for learning contact-rich manipulation skills. RDP employs a two-level hierarchy: (1) a slow latent diffusion policy for predicting high-level action chunks in latent space at low frequency, (2) a fast asymmetric tokenizer for closed-loop tactile feedback control at high frequency. This design enables both complex trajectory modeling and quick reactive behavior within a unified framework. Through extensive evaluation across three challenging contact-rich tasks, RDP significantly improves performance compared to state-of-the-art visual IL baselines through rapid response to tactile / force feedback. Furthermore, experiments show that RDP is applicable across different tactile / force sensors. Code and videos are available on https://reactive-diffusion-policy.github.io/.
Learning to Manipulate Anywhere: A Visual Generalizable Framework For Reinforcement Learning
Jul 22, 2024



Can we endow visuomotor robots with generalization capabilities to operate in diverse open-world scenarios? In this paper, we propose \textbf{Maniwhere}, a generalizable framework tailored for visual reinforcement learning, enabling the trained robot policies to generalize across a combination of multiple visual disturbance types. Specifically, we introduce a multi-view representation learning approach fused with Spatial Transformer Network (STN) module to capture shared semantic information and correspondences among different viewpoints. In addition, we employ a curriculum-based randomization and augmentation approach to stabilize the RL training process and strengthen the visual generalization ability. To exhibit the effectiveness of Maniwhere, we meticulously design 8 tasks encompassing articulate objects, bi-manual, and dexterous hand manipulation tasks, demonstrating Maniwhere's strong visual generalization and sim2real transfer abilities across 3 hardware platforms. Our experiments show that Maniwhere significantly outperforms existing state-of-the-art methods. Videos are provided at https://gemcollector.github.io/maniwhere/.
Thin-Shell Object Manipulations With Differentiable Physics Simulations
Mar 30, 2024



In this work, we aim to teach robots to manipulate various thin-shell materials. Prior works studying thin-shell object manipulation mostly rely on heuristic policies or learn policies from real-world video demonstrations, and only focus on limited material types and tasks (e.g., cloth unfolding). However, these approaches face significant challenges when extended to a wider variety of thin-shell materials and a diverse range of tasks. While virtual simulations are shown to be effective in diverse robot skill learning and evaluation, prior thin-shell simulation environments only support a subset of thin-shell materials, which also limits their supported range of tasks. We introduce ThinShellLab - a fully differentiable simulation platform tailored for robotic interactions with diverse thin-shell materials possessing varying material properties, enabling flexible thin-shell manipulation skill learning and evaluation. Our experiments suggest that manipulating thin-shell objects presents several unique challenges: 1) thin-shell manipulation relies heavily on frictional forces due to the objects' co-dimensional nature, 2) the materials being manipulated are highly sensitive to minimal variations in interaction actions, and 3) the constant and frequent alteration in contact pairs makes trajectory optimization methods susceptible to local optima, and neither standard reinforcement learning algorithms nor trajectory optimization methods (either gradient-based or gradient-free) are able to solve the tasks alone. To overcome these challenges, we present an optimization scheme that couples sampling-based trajectory optimization and gradient-based optimization, boosting both learning efficiency and converged performance across various proposed tasks. In addition, the differentiable nature of our platform facilitates a smooth sim-to-real transition.
DIFFTACTILE: A Physics-based Differentiable Tactile Simulator for Contact-rich Robotic Manipulation
Mar 13, 2024We introduce DIFFTACTILE, a physics-based differentiable tactile simulation system designed to enhance robotic manipulation with dense and physically accurate tactile feedback. In contrast to prior tactile simulators which primarily focus on manipulating rigid bodies and often rely on simplified approximations to model stress and deformations of materials in contact, DIFFTACTILE emphasizes physics-based contact modeling with high fidelity, supporting simulations of diverse contact modes and interactions with objects possessing a wide range of material properties. Our system incorporates several key components, including a Finite Element Method (FEM)-based soft body model for simulating the sensing elastomer, a multi-material simulator for modeling diverse object types (such as elastic, elastoplastic, cables) under manipulation, a penalty-based contact model for handling contact dynamics. The differentiable nature of our system facilitates gradient-based optimization for both 1) refining physical properties in simulation using real-world data, hence narrowing the sim-to-real gap and 2) efficient learning of tactile-assisted grasping and contact-rich manipulation skills. Additionally, we introduce a method to infer the optical response of our tactile sensor to contact using an efficient pixel-based neural module. We anticipate that DIFFTACTILE will serve as a useful platform for studying contact-rich manipulations, leveraging the benefits of dense tactile feedback and differentiable physics. Code and supplementary materials are available at the project website https://difftactile.github.io/.
3D Diffusion Policy
Mar 06, 2024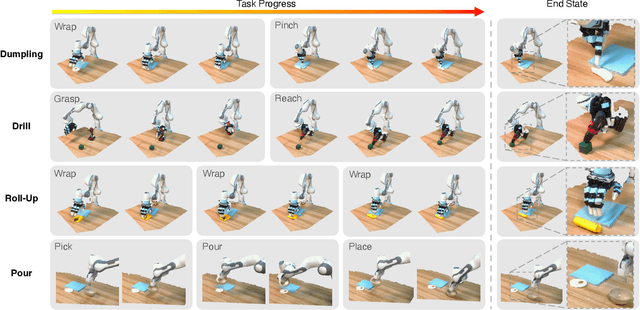

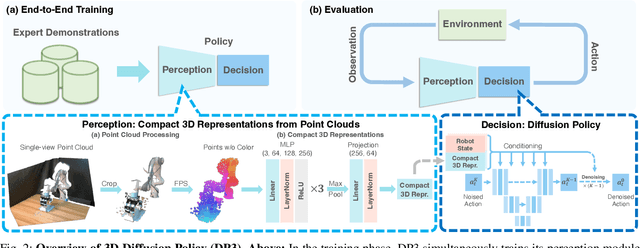
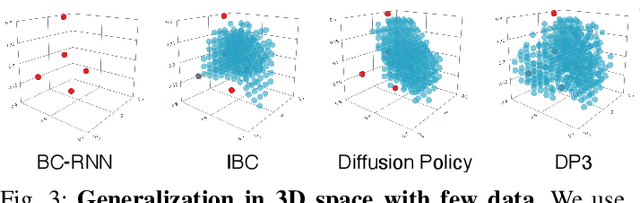
Imitation learning provides an efficient way to teach robots dexterous skills; however, learning complex skills robustly and generalizablely usually consumes large amounts of human demonstrations. To tackle this challenging problem, we present 3D Diffusion Policy (DP3), a novel visual imitation learning approach that incorporates the power of 3D visual representations into diffusion policies, a class of conditional action generative models. The core design of DP3 is the utilization of a compact 3D visual representation, extracted from sparse point clouds with an efficient point encoder. In our experiments involving 72 simulation tasks, DP3 successfully handles most tasks with just 10 demonstrations and surpasses baselines with a 55.3% relative improvement. In 4 real robot tasks, DP3 demonstrates precise control with a high success rate of 85%, given only 40 demonstrations of each task, and shows excellent generalization abilities in diverse aspects, including space, viewpoint, appearance, and instance. Interestingly, in real robot experiments, DP3 rarely violates safety requirements, in contrast to baseline methods which frequently do, necessitating human intervention. Our extensive evaluation highlights the critical importance of 3D representations in real-world robot learning. Videos, code, and data are available on https://3d-diffusion-policy.github.io .
Robo-ABC: Affordance Generalization Beyond Categories via Semantic Correspondence for Robot Manipulation
Jan 15, 2024



Enabling robotic manipulation that generalizes to out-of-distribution scenes is a crucial step toward open-world embodied intelligence. For human beings, this ability is rooted in the understanding of semantic correspondence among objects, which naturally transfers the interaction experience of familiar objects to novel ones. Although robots lack such a reservoir of interaction experience, the vast availability of human videos on the Internet may serve as a valuable resource, from which we extract an affordance memory including the contact points. Inspired by the natural way humans think, we propose Robo-ABC: when confronted with unfamiliar objects that require generalization, the robot can acquire affordance by retrieving objects that share visual or semantic similarities from the affordance memory. The next step is to map the contact points of the retrieved objects to the new object. While establishing this correspondence may present formidable challenges at first glance, recent research finds it naturally arises from pre-trained diffusion models, enabling affordance mapping even across disparate object categories. Through the Robo-ABC framework, robots may generalize to manipulate out-of-category objects in a zero-shot manner without any manual annotation, additional training, part segmentation, pre-coded knowledge, or viewpoint restrictions. Quantitatively, Robo-ABC significantly enhances the accuracy of visual affordance retrieval by a large margin of 31.6% compared to state-of-the-art (SOTA) end-to-end affordance models. We also conduct real-world experiments of cross-category object-grasping tasks. Robo-ABC achieved a success rate of 85.7%, proving its capacity for real-world tasks.
Flexible Handover with Real-Time Robust Dynamic Grasp Trajectory Generation
Aug 29, 2023



In recent years, there has been a significant effort dedicated to developing efficient, robust, and general human-to-robot handover systems. However, the area of flexible handover in the context of complex and continuous objects' motion remains relatively unexplored. In this work, we propose an approach for effective and robust flexible handover, which enables the robot to grasp moving objects with flexible motion trajectories with a high success rate. The key innovation of our approach is the generation of real-time robust grasp trajectories. We also design a future grasp prediction algorithm to enhance the system's adaptability to dynamic handover scenes. We conduct one-motion handover experiments and motion-continuous handover experiments on our novel benchmark that includes 31 diverse household objects. The system we have developed allows users to move and rotate objects in their hands within a relatively large range. The success rate of the robot grasping such moving objects is 78.15% over the entire household object benchmark.
ArrayBot: Reinforcement Learning for Generalizable Distributed Manipulation through Touch
Jun 29, 2023
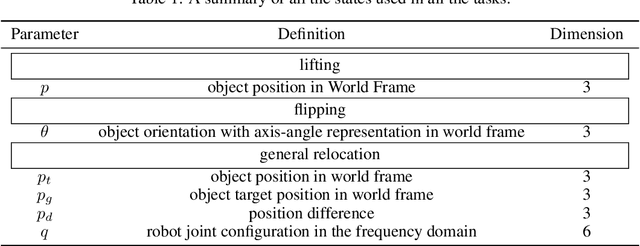


We present ArrayBot, a distributed manipulation system consisting of a $16 \times 16$ array of vertically sliding pillars integrated with tactile sensors, which can simultaneously support, perceive, and manipulate the tabletop objects. Towards generalizable distributed manipulation, we leverage reinforcement learning (RL) algorithms for the automatic discovery of control policies. In the face of the massively redundant actions, we propose to reshape the action space by considering the spatially local action patch and the low-frequency actions in the frequency domain. With this reshaped action space, we train RL agents that can relocate diverse objects through tactile observations only. Surprisingly, we find that the discovered policy can not only generalize to unseen object shapes in the simulator but also transfer to the physical robot without any domain randomization. Leveraging the deployed policy, we present abundant real-world manipulation tasks, illustrating the vast potential of RL on ArrayBot for distributed manipulation.