 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosing the Reality Gap: Zero-Shot Sim-to-Real Deployment for Dexterous Force-Based Grasping and Manipulation
Jan 06, 2026Human-like dexterous hands with multiple fingers offer human-level manipulation capabilities, but training control policies that can directly deploy on real hardware remains difficult due to contact-rich physics and imperfect actuation. We close this gap with a practical sim-to-real reinforcement learning (RL) framework that utilizes dense tactile feedback combined with joint torque sensing to explicitly regulate physical interactions. To enable effective sim-to-real transfer, we introduce (i) a computationally fast tactile simulation that computes distances between dense virtual tactile units and the object via parallel forward kinematics, providing high-rate, high-resolution touch signals needed by RL; (ii) a current-to-torque calibration that eliminates the need for torque sensors on dexterous hands by mapping motor current to joint torque; and (iii) actuator dynamics modeling to bridge the actuation gaps with randomization of non-ideal effects such as backlash, torque-speed saturation. Using an asymmetric actor-critic PPO pipeline trained entirely in simulation, our policies deploy directly to a five-finger hand. The resulting policies demonstrated two essential skills: (1) command-based, controllable grasp force tracking, and (2) reorientation of objects in the hand, both of which were robustly executed without fine-tuning on the robot. By combining tactile and torque in the observation space with effective sensing/actuation modeling, our system provides a practical solution to achieve reliable dexterous manipulation. To our knowledge, this is the first demonstration of controllable grasping on a multi-finger dexterous hand trained entirely in simulation and transferred zero-shot on real hardware.
Learning Visual Quadrupedal Loco-Manipulation from Demonstrations
Mar 29, 2024



Quadruped robots are progressively being integrated into human environments. Despite the growing locomotion capabilities of quadrupedal robots, their interaction with objects in realistic scenes is still limited. While additional robotic arms on quadrupedal robots enable manipulating objects, they are sometimes redundant given that a quadruped robot is essentially a mobile unit equipped with four limbs, each possessing 3 degrees of freedom (DoFs). Hence, we aim to empower a quadruped robot to execute real-world manipulation tasks using only its legs. We decompose the loco-manipulation process into a low-level reinforcement learning (RL)-based controller and a high-level Behavior Cloning (BC)-based planner. By parameterizing the manipulation trajectory, we synchronize the efforts of the upper and lower layers, thereby leveraging the advantages of both RL and BC. Our approach is validated through simulations and real-world experiments, demonstrating the robot's ability to perform tasks that demand mobility and high precision, such as lifting a basket from the ground while moving, closing a dishwasher, pressing a button, and pushing a door. Project website: https://zhengmaohe.github.io/leg-manip
Uni-O4: Unifying Online and Offline Deep Reinforcement Learning with Multi-Step On-Policy Optimization
Nov 06, 2023Combining offline and online reinforcement learning (RL) is crucial for efficient and safe learning. However, previous approaches treat offline and online learning as separate procedures, resulting in redundant designs and limited performance. We ask: Can we achieve straightforward yet effective offline and online learning without introducing extra conservatism or regularization? In this study, we propose Uni-o4, which utilizes an on-policy objective for both offline and online learning. Owning to the alignment of objectives in two phases, the RL agent can transfer between offline and online learning seamlessly. This property enhances the flexibility of the learning paradigm, allowing for arbitrary combinations of pretraining, fine-tuning, offline, and online learning. In the offline phase, specifically, Uni-o4 leverages diverse ensemble policies to address the mismatch issues between the estimated behavior policy and the offline dataset. Through a simple offline policy evaluation (OPE) approach, Uni-o4 can achieve multi-step policy improvement safely. We demonstrate that by employing the method above, the fusion of these two paradigms can yield superior offline initialization as well as stable and rapid online fine-tuning capabilities. Through real-world robot tasks, we highlight the benefits of this paradigm for rapid deployment in challenging, previously unseen real-world environments. Additionally, through comprehensive evaluations using numerous simulated benchmarks, we substantiate that our method achieves state-of-the-art performance in both offline and offline-to-online fine-tuning learning. Our website: https://lei-kun.github.io/uni-o4/ .
ArrayBot: Reinforcement Learning for Generalizable Distributed Manipulation through Touch
Jun 29, 2023
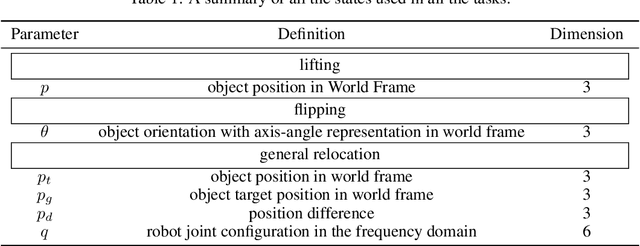


We present ArrayBot, a distributed manipulation system consisting of a $16 \times 16$ array of vertically sliding pillars integrated with tactile sensors, which can simultaneously support, perceive, and manipulate the tabletop objects. Towards generalizable distributed manipulation, we leverage reinforcement learning (RL) algorithms for the automatic discovery of control policies. In the face of the massively redundant actions, we propose to reshape the action space by considering the spatially local action patch and the low-frequency actions in the frequency domain. With this reshaped action space, we train RL agents that can relocate diverse objects through tactile observations only. Surprisingly, we find that the discovered policy can not only generalize to unseen object shapes in the simulator but also transfer to the physical robot without any domain randomization. Leveraging the deployed policy, we present abundant real-world manipulation tasks, illustrating the vast potential of RL on ArrayBot for distributed manipulation.