 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFailure-Aware RL: Reliable Offline-to-Online Reinforcement Learning with Self-Recovery for Real-World Manipulation
Jan 12, 2026Post-training algorithms based on deep reinforcement learning can push the limits of robotic models for specific objectives, such as generalizability, accuracy, and robustness. However, Intervention-requiring Failures (IR Failures) (e.g., a robot spilling water or breaking fragile glass) during real-world exploration happen inevitably, hindering the practical deployment of such a paradigm. To tackle this, we introduce Failure-Aware Offline-to-Online Reinforcement Learning (FARL), a new paradigm minimizing failures during real-world reinforcement learning. We create FailureBench, a benchmark that incorporates common failure scenarios requiring human intervention, and propose an algorithm that integrates a world-model-based safety critic and a recovery policy trained offline to prevent failures during online exploration. Extensive simulation and real-world experiments demonstrate the effectiveness of FARL in significantly reducing IR Failures while improving performance and generalization during online reinforcement learning post-training. FARL reduces IR Failures by 73.1% while elevating performance by 11.3% on average during real-world RL post-training. Videos and code are available at https://failure-aware-rl.github.io.
Learning Visual Quadrupedal Loco-Manipulation from Demonstrations
Mar 29, 2024



Quadruped robots are progressively being integrated into human environments. Despite the growing locomotion capabilities of quadrupedal robots, their interaction with objects in realistic scenes is still limited. While additional robotic arms on quadrupedal robots enable manipulating objects, they are sometimes redundant given that a quadruped robot is essentially a mobile unit equipped with four limbs, each possessing 3 degrees of freedom (DoFs). Hence, we aim to empower a quadruped robot to execute real-world manipulation tasks using only its legs. We decompose the loco-manipulation process into a low-level reinforcement learning (RL)-based controller and a high-level Behavior Cloning (BC)-based planner. By parameterizing the manipulation trajectory, we synchronize the efforts of the upper and lower layers, thereby leveraging the advantages of both RL and BC. Our approach is validated through simulations and real-world experiments, demonstrating the robot's ability to perform tasks that demand mobility and high precision, such as lifting a basket from the ground while moving, closing a dishwasher, pressing a button, and pushing a door. Project website: https://zhengmaohe.github.io/leg-manip
Uni-O4: Unifying Online and Offline Deep Reinforcement Learning with Multi-Step On-Policy Optimization
Nov 06, 2023Combining offline and online reinforcement learning (RL) is crucial for efficient and safe learning. However, previous approaches treat offline and online learning as separate procedures, resulting in redundant designs and limited performance. We ask: Can we achieve straightforward yet effective offline and online learning without introducing extra conservatism or regularization? In this study, we propose Uni-o4, which utilizes an on-policy objective for both offline and online learning. Owning to the alignment of objectives in two phases, the RL agent can transfer between offline and online learning seamlessly. This property enhances the flexibility of the learning paradigm, allowing for arbitrary combinations of pretraining, fine-tuning, offline, and online learning. In the offline phase, specifically, Uni-o4 leverages diverse ensemble policies to address the mismatch issues between the estimated behavior policy and the offline dataset. Through a simple offline policy evaluation (OPE) approach, Uni-o4 can achieve multi-step policy improvement safely. We demonstrate that by employing the method above, the fusion of these two paradigms can yield superior offline initialization as well as stable and rapid online fine-tuning capabilities. Through real-world robot tasks, we highlight the benefits of this paradigm for rapid deployment in challenging, previously unseen real-world environments. Additionally, through comprehensive evaluations using numerous simulated benchmarks, we substantiate that our method achieves state-of-the-art performance in both offline and offline-to-online fine-tuning learning. Our website: https://lei-kun.github.io/uni-o4/ .
Behavior Proximal Policy Optimization
Feb 22, 2023



Offline reinforcement learning (RL) is a challenging setting where existing off-policy actor-critic methods perform poorly due to the overestimation of out-of-distribution state-action pairs. Thus, various additional augmentations are proposed to keep the learned policy close to the offline dataset (or the behavior policy). In this work, starting from the analysis of offline monotonic policy improvement, we get a surprising finding that some online on-policy algorithms are naturally able to solve offline RL. Specifically, the inherent conservatism of these on-policy algorithms is exactly what the offline RL method needs to overcome the overestimation. Based on this, we propose Behavior Proximal Policy Optimization (BPPO), which solves offline RL without any extra constraint or regularization introduced compared to PPO. Extensive experiments on the D4RL benchmark indicate this extremely succinct method outperforms state-of-the-art offline RL algorithms. Our implementation is available at https://github.com/Dragon-Zhuang/BPPO.
Solve routing problems with a residual edge-graph attention neural network
May 06, 2021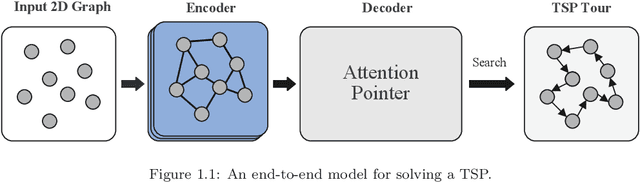
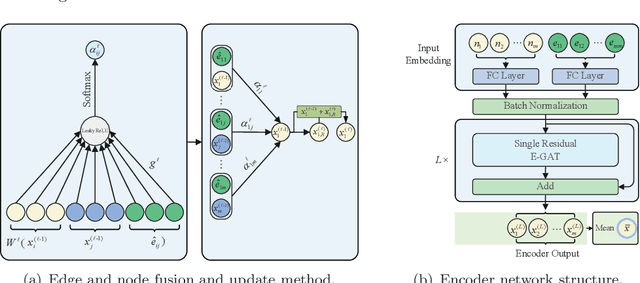
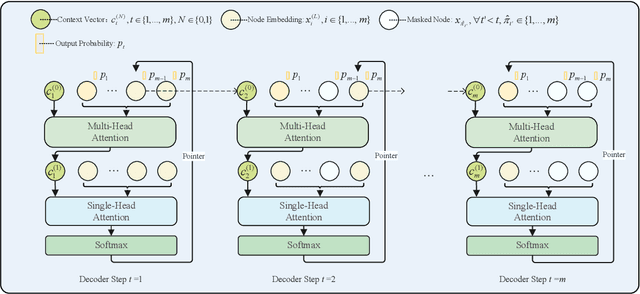
For NP-hard combinatorial optimization problems, it is usually difficult to find high-quality solutions in polynomial time. The design of either an exact algorithm or an approximate algorithm for these problems often requires significantly specialized knowledge. Recently, deep learning methods provide new directions to solve such problems. In this paper, an end-to-end deep reinforcement learning framework is proposed to solve this type of combinatorial optimization problems. This framework can be applied to different problems with only slight changes of input (for example, for a traveling salesman problem (TSP), the input is the two-dimensional coordinates of nodes; while for a capacity-constrained vehicle routing problem (CVRP), the input is simply changed to three-dimensional vectors including the two-dimensional coordinates and the customer demands of nodes), masks and decoder context vectors. The proposed framework is aiming to improve the models in literacy in terms of the neural network model and the training algorithm. The solution quality of TSP and the CVRP up to 100 nodes are significantly improved via our framework. Specifically, the average optimality gap is reduced from 4.53\% (reported best \cite{R22}) to 3.67\% for TSP with 100 nodes and from 7.34\% (reported best \cite{R22}) to 6.68\% for CVRP with 100 nodes when using the greedy decoding strategy. Furthermore, our framework uses about 1/3$\sim$3/4 training samples compared with other existing learning methods while achieving better results. The results performed on randomly generated instances and the benchmark instances from TSPLIB and CVRPLIB confirm that our framework has a linear running time on the problem size (number of nodes) during the testing phase, and has a good generalization performance from random instance training to real-world instance testing.