 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHERMES: Human-to-Robot Embodied Learning from Multi-Source Motion Data for Mobile Dexterous Manipulation
Aug 28, 2025Leveraging human motion data to impart robots with versatile manipulation skills has emerged as a promising paradigm in robotic manipulation. Nevertheless, translating multi-source human hand motions into feasible robot behaviors remains challenging, particularly for robots equipped with multi-fingered dexterous hands characterized by complex, high-dimensional action spaces. Moreover, existing approaches often struggle to produce policies capable of adapting to diverse environmental conditions. In this paper, we introduce HERMES, a human-to-robot learning framework for mobile bimanual dexterous manipulation. First, HERMES formulates a unified reinforcement learning approach capable of seamlessly transforming heterogeneous human hand motions from multiple sources into physically plausible robotic behaviors. Subsequently, to mitigate the sim2real gap, we devise an end-to-end, depth image-based sim2real transfer method for improved generalization to real-world scenarios. Furthermore, to enable autonomous operation in varied and unstructured environments, we augment the navigation foundation model with a closed-loop Perspective-n-Point (PnP) localization mechanism, ensuring precise alignment of visual goals and effectively bridging autonomous navigation and dexterous manipulation. Extensive experimental results demonstrate that HERMES consistently exhibits generalizable behaviors across diverse, in-the-wild scenarios, successfully performing numerous complex mobile bimanual dexterous manipulation tasks. Project Page:https://gemcollector.github.io/HERMES/.
Two by Two: Learning Multi-Task Pairwise Objects Assembly for Generalizable Robot Manipulation
Apr 09, 20253D assembly tasks, such as furniture assembly and component fitting, play a crucial role in daily life and represent essential capabilities for future home robots. Existing benchmarks and datasets predominantly focus on assembling geometric fragments or factory parts, which fall short in addressing the complexities of everyday object interactions and assemblies. To bridge this gap, we present 2BY2, a large-scale annotated dataset for daily pairwise objects assembly, covering 18 fine-grained tasks that reflect real-life scenarios, such as plugging into sockets, arranging flowers in vases, and inserting bread into toasters. 2BY2 dataset includes 1,034 instances and 517 pairwise objects with pose and symmetry annotations, requiring approaches that align geometric shapes while accounting for functional and spatial relationships between objects. Leveraging the 2BY2 dataset, we propose a two-step SE(3) pose estimation method with equivariant features for assembly constraints. Compared to previous shape assembly methods, our approach achieves state-of-the-art performance across all 18 tasks in the 2BY2 dataset. Additionally, robot experiments further validate the reliability and generalization ability of our method for complex 3D assembly tasks.
Learning to Manipulate Anywhere: A Visual Generalizable Framework For Reinforcement Learning
Jul 22, 2024



Can we endow visuomotor robots with generalization capabilities to operate in diverse open-world scenarios? In this paper, we propose \textbf{Maniwhere}, a generalizable framework tailored for visual reinforcement learning, enabling the trained robot policies to generalize across a combination of multiple visual disturbance types. Specifically, we introduce a multi-view representation learning approach fused with Spatial Transformer Network (STN) module to capture shared semantic information and correspondences among different viewpoints. In addition, we employ a curriculum-based randomization and augmentation approach to stabilize the RL training process and strengthen the visual generalization ability. To exhibit the effectiveness of Maniwhere, we meticulously design 8 tasks encompassing articulate objects, bi-manual, and dexterous hand manipulation tasks, demonstrating Maniwhere's strong visual generalization and sim2real transfer abilities across 3 hardware platforms. Our experiments show that Maniwhere significantly outperforms existing state-of-the-art methods. Videos are provided at https://gemcollector.github.io/maniwhere/.
RoboScript: Code Generation for Free-Form Manipulation Tasks across Real and Simulation
Feb 22, 2024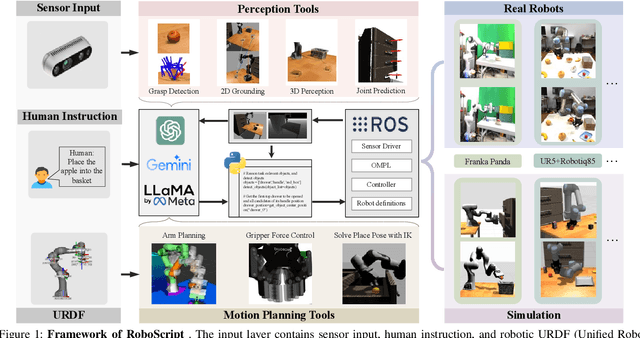



Rapid progress in high-level task planning and code generation for open-world robot manipulation has been witnessed in Embodied AI. However, previous studies put much effort into general common sense reasoning and task planning capabilities of large-scale language or multi-modal models, relatively little effort on ensuring the deployability of generated code on real robots, and other fundamental components of autonomous robot systems including robot perception, motion planning, and control. To bridge this ``ideal-to-real'' gap, this paper presents \textbf{RobotScript}, a platform for 1) a deployable robot manipulation pipeline powered by code generation; and 2) a code generation benchmark for robot manipulation tasks in free-form natural language. The RobotScript platform addresses this gap by emphasizing the unified interface with both simulation and real robots, based on abstraction from the Robot Operating System (ROS), ensuring syntax compliance and simulation validation with Gazebo. We demonstrate the adaptability of our code generation framework across multiple robot embodiments, including the Franka and UR5 robot arms, and multiple grippers. Additionally, our benchmark assesses reasoning abilities for physical space and constraints, highlighting the differences between GPT-3.5, GPT-4, and Gemini in handling complex physical interactions. Finally, we present a thorough evaluation on the whole system, exploring how each module in the pipeline: code generation, perception, motion planning, and even object geometric properties, impact the overall performance of the system.