 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMME-CoF-Pro: Evaluating Reasoning Coherence in Video Generative Models with Text and Visual Hints
Mar 20, 2026Video generative models show emerging reasoning behaviors. It is essential to ensure that generated events remain causally consistent across frames for reliable deployment, a property we define as reasoning coherence. To bridge the gap in literature for missing reasoning coherence evaluation, we propose MME-CoF-Pro, a comprehensive video reasoning benchmark to assess reasoning coherence in video models. Specifically, MME-CoF-Pro contains 303 samples across 16 categories, ranging from visual logical to scientific reasoning. It introduces Reasoning Score as evaluation metric for assessing process-level necessary intermediate reasoning steps, and includes three evaluation settings, (a) no hint (b) text hint and (c) visual hint, enabling a controlled investigation into the underlying mechanisms of reasoning hint guidance. Evaluation results in 7 open and closed-source video models reveals insights including: (1) Video generative models exhibit weak reasoning coherence, decoupled from generation quality. (2) Text hints boost apparent correctness but often cause inconsistency and hallucinated reasoning (3) Visual hints benefit structured perceptual tasks but struggle with fine-grained perception. Website: https://video-reasoning-coherence.github.io/
Towards Compositional Generalization in LLMs for Smart Contract Security: A Case Study on Reentrancy Vulnerabilities
Jan 11, 2026Large language models (LLMs) demonstrate remarkable capabilities in natural language understanding and generation. Despite being trained on large-scale, high-quality data, LLMs still fail to outperform traditional static analysis tools in specialized domains like smart contract vulnerability detection. To address this issue, this paper proposes a post-training algorithm based on atomic task decomposition and fusion. This algorithm aims to achieve combinatorial generalization under limited data by decomposing complex reasoning tasks. Specifically, we decompose the reentrancy vulnerability detection task into four linearly independent atomic tasks: identifying external calls, identifying state updates, identifying data dependencies between external calls and state updates, and determining their data flow order. These tasks form the core components of our approach. By training on synthetic datasets, we generate three compiler-verified datasets. We then employ the Slither tool to extract structural information from the control flow graph and data flow graph, which is used to fine-tune the LLM's adapter. Experimental results demonstrate that low-rank normalization fusion with the LoRA adapter improves the LLM's reentrancy vulnerability detection accuracy to 98.2%, surpassing state-of-the-art methods. On 31 real-world contracts, the algorithm achieves a 20% higher recall than traditional analysis tools.
Residual Rotation Correction using Tactile Equivariance
Nov 11, 2025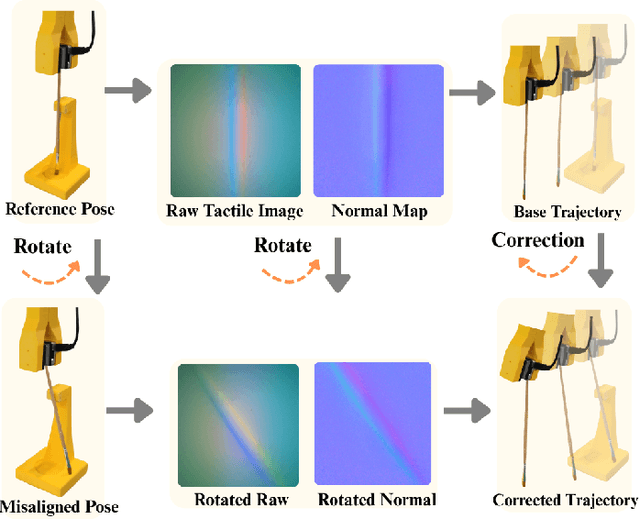
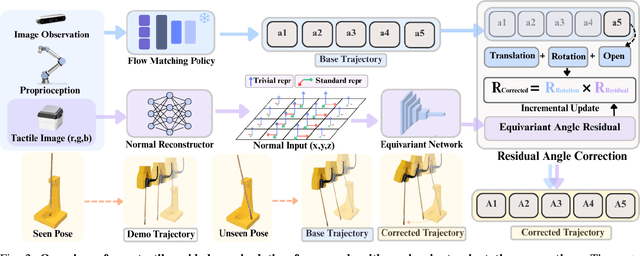
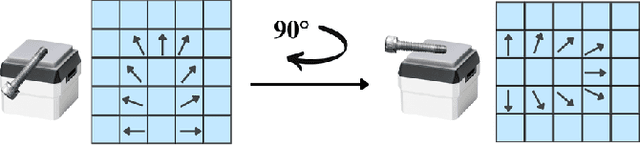

Visuotactile policy learning augments vision-only policies with tactile input, facilitating contact-rich manipulation. However, the high cost of tactile data collection makes sample efficiency the key requirement for developing visuotactile policies. We present EquiTac, a framework that exploits the inherent SO(2) symmetry of in-hand object rotation to improve sample efficiency and generalization for visuotactile policy learning. EquiTac first reconstructs surface normals from raw RGB inputs of vision-based tactile sensors, so rotations of the normal vector field correspond to in-hand object rotations. An SO(2)-equivariant network then predicts a residual rotation action that augments a base visuomotor policy at test time, enabling real-time rotation correction without additional reorientation demonstrations. On a real robot, EquiTac accurately achieves robust zero-shot generalization to unseen in-hand orientations with very few training samples, where baselines fail even with more training data. To our knowledge, this is the first tactile learning method to explicitly encode tactile equivariance for policy learning, yielding a lightweight, symmetry-aware module that improves reliability in contact-rich tasks.
Are Video Models Ready as Zero-Shot Reasoners? An Empirical Study with the MME-CoF Benchmark
Oct 30, 2025Recent video generation models can produce high-fidelity, temporally coherent videos, indicating that they may encode substantial world knowledge. Beyond realistic synthesis, they also exhibit emerging behaviors indicative of visual perception, modeling, and manipulation. Yet, an important question still remains: Are video models ready to serve as zero-shot reasoners in challenging visual reasoning scenarios? In this work, we conduct an empirical study to comprehensively investigate this question, focusing on the leading and popular Veo-3. We evaluate its reasoning behavior across 12 dimensions, including spatial, geometric, physical, temporal, and embodied logic, systematically characterizing both its strengths and failure modes. To standardize this study, we curate the evaluation data into MME-CoF, a compact benchmark that enables in-depth and thorough assessment of Chain-of-Frame (CoF) reasoning. Our findings reveal that while current video models demonstrate promising reasoning patterns on short-horizon spatial coherence, fine-grained grounding, and locally consistent dynamics, they remain limited in long-horizon causal reasoning, strict geometric constraints, and abstract logic. Overall, they are not yet reliable as standalone zero-shot reasoners, but exhibit encouraging signs as complementary visual engines alongside dedicated reasoning models. Project page: https://video-cof.github.io
I Speak and You Find: Robust 3D Visual Grounding with Noisy and Ambiguous Speech Inputs
Jun 17, 2025Existing 3D visual grounding methods rely on precise text prompts to locate objects within 3D scenes. Speech, as a natural and intuitive modality, offers a promising alternative. Real-world speech inputs, however, often suffer from transcription errors due to accents, background noise, and varying speech rates, limiting the applicability of existing 3DVG methods. To address these challenges, we propose \textbf{SpeechRefer}, a novel 3DVG framework designed to enhance performance in the presence of noisy and ambiguous speech-to-text transcriptions. SpeechRefer integrates seamlessly with xisting 3DVG models and introduces two key innovations. First, the Speech Complementary Module captures acoustic similarities between phonetically related words and highlights subtle distinctions, generating complementary proposal scores from the speech signal. This reduces dependence on potentially erroneous transcriptions. Second, the Contrastive Complementary Module employs contrastive learning to align erroneous text features with corresponding speech features, ensuring robust performance even when transcription errors dominate. Extensive experiments on the SpeechRefer and peechNr3D datasets demonstrate that SpeechRefer improves the performance of existing 3DVG methods by a large margin, which highlights SpeechRefer's potential to bridge the gap between noisy speech inputs and reliable 3DVG, enabling more intuitive and practical multimodal systems.
EquAct: An SE(3)-Equivariant Multi-Task Transformer for Open-Loop Robotic Manipulation
May 27, 2025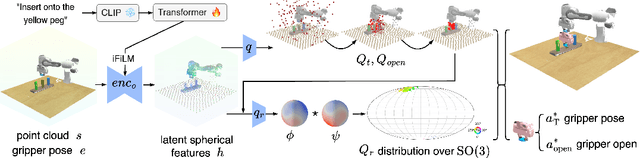
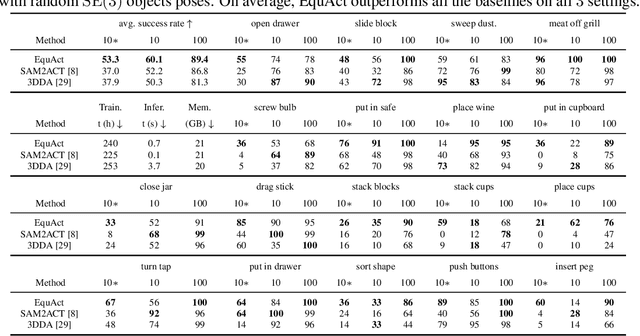
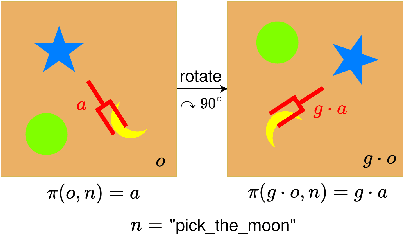
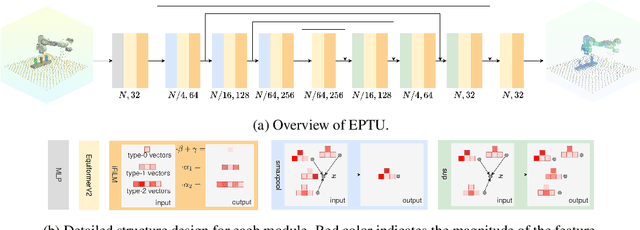
Transformer architectures can effectively learn language-conditioned, multi-task 3D open-loop manipulation policies from demonstrations by jointly processing natural language instructions and 3D observations. However, although both the robot policy and language instructions inherently encode rich 3D geometric structures, standard transformers lack built-in guarantees of geometric consistency, often resulting in unpredictable behavior under SE(3) transformations of the scene. In this paper, we leverage SE(3) equivariance as a key structural property shared by both policy and language, and propose EquAct-a novel SE(3)-equivariant multi-task transformer. EquAct is theoretically guaranteed to be SE(3) equivariant and consists of two key components: (1) an efficient SE(3)-equivariant point cloud-based U-net with spherical Fourier features for policy reasoning, and (2) SE(3)-invariant Feature-wise Linear Modulation (iFiLM) layers for language conditioning. To evaluate its spatial generalization ability, we benchmark EquAct on 18 RLBench simulation tasks with both SE(3) and SE(2) scene perturbations, and on 4 physical tasks. EquAct performs state-of-the-art across these simulation and physical tasks.
Human-like Cognitive Generalization for Large Models via Brain-in-the-loop Supervision
May 14, 2025Recent advancements in deep neural networks (DNNs), particularly large-scale language models, have demonstrated remarkable capabilities in image and natural language understanding. Although scaling up model parameters with increasing volume of training data has progressively improved DNN capabilities, achieving complex cognitive abilities - such as understanding abstract concepts, reasoning, and adapting to novel scenarios, which are intrinsic to human cognition - remains a major challenge. In this study, we show that brain-in-the-loop supervised learning, utilizing a small set of brain signals, can effectively transfer human conceptual structures to DNNs, significantly enhancing their comprehension of abstract and even unseen concepts. Experimental results further indicate that the enhanced cognitive capabilities lead to substantial performance gains in challenging tasks, including few-shot/zero-shot learning and out-of-distribution recognition, while also yielding highly interpretable concept representations. These findings highlight that human-in-the-loop supervision can effectively augment the complex cognitive abilities of large models, offering a promising pathway toward developing more human-like cognitive abilities in artificial systems.
Two by Two: Learning Multi-Task Pairwise Objects Assembly for Generalizable Robot Manipulation
Apr 09, 2025



3D assembly tasks, such as furniture assembly and component fitting, play a crucial role in daily life and represent essential capabilities for future home robots. Existing benchmarks and datasets predominantly focus on assembling geometric fragments or factory parts, which fall short in addressing the complexities of everyday object interactions and assemblies. To bridge this gap, we present 2BY2, a large-scale annotated dataset for daily pairwise objects assembly, covering 18 fine-grained tasks that reflect real-life scenarios, such as plugging into sockets, arranging flowers in vases, and inserting bread into toasters. 2BY2 dataset includes 1,034 instances and 517 pairwise objects with pose and symmetry annotations, requiring approaches that align geometric shapes while accounting for functional and spatial relationships between objects. Leveraging the 2BY2 dataset, we propose a two-step SE(3) pose estimation method with equivariant features for assembly constraints. Compared to previous shape assembly methods, our approach achieves state-of-the-art performance across all 18 tasks in the 2BY2 dataset. Additionally, robot experiments further validate the reliability and generalization ability of our method for complex 3D assembly tasks.
MME-CoT: Benchmarking Chain-of-Thought in Large Multimodal Models for Reasoning Quality, Robustness, and Efficiency
Feb 13, 2025



Answering questions with Chain-of-Thought (CoT) has significantly enhanced the reasoning capabilities of Large Language Models (LLMs), yet its impact on Large Multimodal Models (LMMs) still lacks a systematic assessment and in-depth investigation. In this paper, we introduce MME-CoT, a specialized benchmark evaluating the CoT reasoning performance of LMMs, spanning six domains: math, science, OCR, logic, space-time, and general scenes. As the first comprehensive study in this area, we propose a thorough evaluation suite incorporating three novel metrics that assess the reasoning quality, robustness, and efficiency at a fine-grained level. Leveraging curated high-quality data and a unique evaluation strategy, we conduct an in-depth analysis of state-of-the-art LMMs, uncovering several key insights: 1) Models with reflection mechanism demonstrate a superior CoT quality, with Kimi k1.5 outperforming GPT-4o and demonstrating the highest quality results; 2) CoT prompting often degrades LMM performance on perception-heavy tasks, suggesting a potentially harmful overthinking behavior; and 3) Although the CoT quality is high, LMMs with reflection exhibit significant inefficiency in both normal response and self-correction phases. We hope MME-CoT serves as a foundation for advancing multimodal reasoning in LMMs. Project Page: https://mmecot.github.io/
ThinkGrasp: A Vision-Language System for Strategic Part Grasping in Clutter
Jul 16, 2024



Robotic grasping in cluttered environments remains a significant challenge due to occlusions and complex object arrangements. We have developed ThinkGrasp, a plug-and-play vision-language grasping system that makes use of GPT-4o's advanced contextual reasoning for heavy clutter environment grasping strategies. ThinkGrasp can effectively identify and generate grasp poses for target objects, even when they are heavily obstructed or nearly invisible, by using goal-oriented language to guide the removal of obstructing objects. This approach progressively uncovers the target object and ultimately grasps it with a few steps and a high success rate. In both simulated and real experiments, ThinkGrasp achieved a high success rate and significantly outperformed state-of-the-art methods in heavily cluttered environments or with diverse unseen objects, demonstrating strong generalization capabilities.