 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Latent Space: Foundation, Evolution, Mechanism, Ability, and Outlook
Apr 02, 2026Latent space is rapidly emerging as a native substrate for language-based models. While modern systems are still commonly understood through explicit token-level generation, an increasing body of work shows that many critical internal processes are more naturally carried out in continuous latent space than in human-readable verbal traces. This shift is driven by the structural limitations of explicit-space computation, including linguistic redundancy, discretization bottlenecks, sequential inefficiency, and semantic loss. This survey aims to provide a unified and up-to-date landscape of latent space in language-based models. We organize the survey into five sequential perspectives: Foundation, Evolution, Mechanism, Ability, and Outlook. We begin by delineating the scope of latent space, distinguishing it from explicit or verbal space and from the latent spaces commonly studied in generative visual models. We then trace the field's evolution from early exploratory efforts to the current large-scale expansion. To organize the technical landscape, we examine existing work through the complementary lenses of mechanism and ability. From the perspective of Mechanism, we identify four major lines of development: Architecture, Representation, Computation, and Optimization. From the perspective of Ability, we show how latent space supports a broad capability spectrum spanning Reasoning, Planning, Modeling, Perception, Memory, Collaboration, and Embodiment. Beyond consolidation, we discuss the key open challenges, and outline promising directions for future research. We hope this survey serves not only as a reference for existing work, but also as a foundation for understanding latent space as a general computational and systems paradigm for next-generation intelligence.
MME-CoF-Pro: Evaluating Reasoning Coherence in Video Generative Models with Text and Visual Hints
Mar 20, 2026Video generative models show emerging reasoning behaviors. It is essential to ensure that generated events remain causally consistent across frames for reliable deployment, a property we define as reasoning coherence. To bridge the gap in literature for missing reasoning coherence evaluation, we propose MME-CoF-Pro, a comprehensive video reasoning benchmark to assess reasoning coherence in video models. Specifically, MME-CoF-Pro contains 303 samples across 16 categories, ranging from visual logical to scientific reasoning. It introduces Reasoning Score as evaluation metric for assessing process-level necessary intermediate reasoning steps, and includes three evaluation settings, (a) no hint (b) text hint and (c) visual hint, enabling a controlled investigation into the underlying mechanisms of reasoning hint guidance. Evaluation results in 7 open and closed-source video models reveals insights including: (1) Video generative models exhibit weak reasoning coherence, decoupled from generation quality. (2) Text hints boost apparent correctness but often cause inconsistency and hallucinated reasoning (3) Visual hints benefit structured perceptual tasks but struggle with fine-grained perception. Website: https://video-reasoning-coherence.github.io/
3D Equivariant Visuomotor Policy Learning via Spherical Projection
May 22, 2025Equivariant models have recently been shown to improve the data efficiency of diffusion policy by a significant margin. However, prior work that explored this direction focused primarily on point cloud inputs generated by multiple cameras fixed in the workspace. This type of point cloud input is not compatible with the now-common setting where the primary input modality is an eye-in-hand RGB camera like a GoPro. This paper closes this gap by incorporating into the diffusion policy model a process that projects features from the 2D RGB camera image onto a sphere. This enables us to reason about symmetries in SO(3) without explicitly reconstructing a point cloud. We perform extensive experiments in both simulation and the real world that demonstrate that our method consistently outperforms strong baselines in terms of both performance and sample efficiency. Our work is the first SO(3)-equivariant policy learning framework for robotic manipulation that works using only monocular RGB inputs.
Coarse-to-Fine 3D Keyframe Transporter
Feb 03, 2025

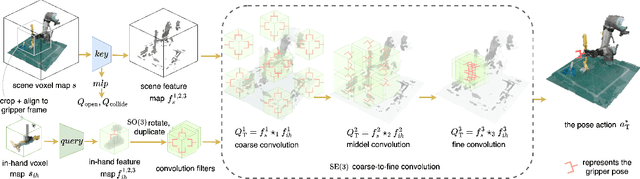
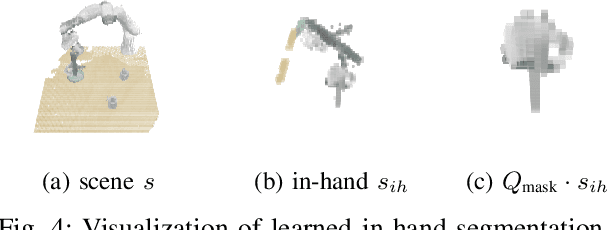
Recent advances in Keyframe Imitation Learning (IL) have enabled learning-based agents to solve a diverse range of manipulation tasks. However, most approaches ignore the rich symmetries in the problem setting and, as a consequence, are sample-inefficient. This work identifies and utilizes the bi-equivariant symmetry within Keyframe IL to design a policy that generalizes to transformations of both the workspace and the objects grasped by the gripper. We make two main contributions: First, we analyze the bi-equivariance properties of the keyframe action scheme and propose a Keyframe Transporter derived from the Transporter Networks, which evaluates actions using cross-correlation between the features of the grasped object and the features of the scene. Second, we propose a computationally efficient coarse-to-fine SE(3) action evaluation scheme for reasoning the intertwined translation and rotation action. The resulting method outperforms strong Keyframe IL baselines by an average of >10% on a wide range of simulation tasks, and by an average of 55% in 4 physical experiments.
Leverage Task Context for Object Affordance Ranking
Nov 25, 2024Intelligent agents accomplish different tasks by utilizing various objects based on their affordance, but how to select appropriate objects according to task context is not well-explored. Current studies treat objects within the affordance category as equivalent, ignoring that object affordances vary in priority with different task contexts, hindering accurate decision-making in complex environments. To enable agents to develop a deeper understanding of the objects required to perform tasks, we propose to leverage task context for object affordance ranking, i.e., given image of a complex scene and the textual description of the affordance and task context, revealing task-object relationships and clarifying the priority rank of detected objects. To this end, we propose a novel Context-embed Group Ranking Framework with task relation mining module and graph group update module to deeply integrate task context and perform global relative relationship transmission. Due to the lack of such data, we construct the first large-scale task-oriented affordance ranking dataset with 25 common tasks, over 50k images and more than 661k objects. Experimental results demonstrate the feasibility of the task context based affordance learning paradigm and the superiority of our model over state-of-the-art models in the fields of saliency ranking and multimodal object detection. The source code and dataset will be made available to the public.
ThinkGrasp: A Vision-Language System for Strategic Part Grasping in Clutter
Jul 16, 2024



Robotic grasping in cluttered environments remains a significant challenge due to occlusions and complex object arrangements. We have developed ThinkGrasp, a plug-and-play vision-language grasping system that makes use of GPT-4o's advanced contextual reasoning for heavy clutter environment grasping strategies. ThinkGrasp can effectively identify and generate grasp poses for target objects, even when they are heavily obstructed or nearly invisible, by using goal-oriented language to guide the removal of obstructing objects. This approach progressively uncovers the target object and ultimately grasps it with a few steps and a high success rate. In both simulated and real experiments, ThinkGrasp achieved a high success rate and significantly outperformed state-of-the-art methods in heavily cluttered environments or with diverse unseen objects, demonstrating strong generalization capabilities.
OrbitGrasp: $SE(3)$-Equivariant Grasp Learning
Jul 03, 2024



While grasp detection is an important part of any robotic manipulation pipeline, reliable and accurate grasp detection in $SE(3)$ remains a research challenge. Many robotics applications in unstructured environments such as the home or warehouse would benefit a lot from better grasp performance. This paper proposes a novel framework for detecting $SE(3)$ grasp poses based on point cloud input. Our main contribution is to propose an $SE(3)$-equivariant model that maps each point in the cloud to a continuous grasp quality function over the 2-sphere $S^2$ using a spherical harmonic basis. Compared with reasoning about a finite set of samples, this formulation improves the accuracy and efficiency of our model when a large number of samples would otherwise be needed. In order to accomplish this, we propose a novel variation on EquiFormerV2 that leverages a UNet-style backbone to enlarge the number of points the model can handle. Our resulting method, which we name $\textit{OrbitGrasp}$, significantly outperforms baselines in both simulation and physical experiments.
Equivariant Diffusion Policy
Jul 01, 2024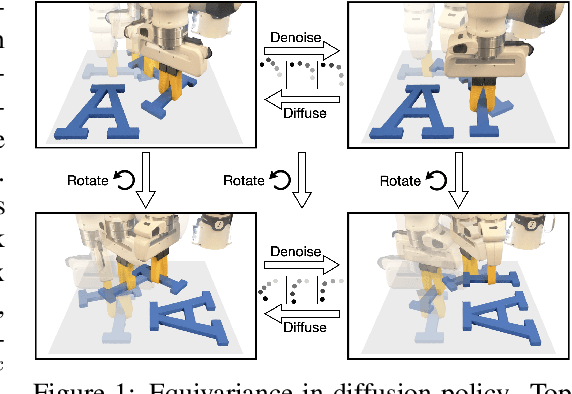



Recent work has shown diffusion models are an effective approach to learning the multimodal distributions arising from demonstration data in behavior cloning. However, a drawback of this approach is the need to learn a denoising function, which is significantly more complex than learning an explicit policy. In this work, we propose Equivariant Diffusion Policy, a novel diffusion policy learning method that leverages domain symmetries to obtain better sample efficiency and generalization in the denoising function. We theoretically analyze the $\mathrm{SO}(2)$ symmetry of full 6-DoF control and characterize when a diffusion model is $\mathrm{SO}(2)$-equivariant. We furthermore evaluate the method empirically on a set of 12 simulation tasks in MimicGen, and show that it obtains a success rate that is, on average, 21.9% higher than the baseline Diffusion Policy. We also evaluate the method on a real-world system to show that effective policies can be learned with relatively few training samples, whereas the baseline Diffusion Policy cannot.
Open-vocabulary Pick and Place via Patch-level Semantic Maps
Jun 21, 2024Controlling robots through natural language instructions in open-vocabulary scenarios is pivotal for enhancing human-robot collaboration and complex robot behavior synthesis. However, achieving this capability poses significant challenges due to the need for a system that can generalize from limited data to a wide range of tasks and environments. Existing methods rely on large, costly datasets and struggle with generalization. This paper introduces Grounded Equivariant Manipulation (GEM), a novel approach that leverages the generative capabilities of pre-trained vision-language models and geometric symmetries to facilitate few-shot and zero-shot learning for open-vocabulary robot manipulation tasks. Our experiments demonstrate GEM's high sample efficiency and superior generalization across diverse pick-and-place tasks in both simulation and real-world experiments, showcasing its ability to adapt to novel instructions and unseen objects with minimal data requirements. GEM advances a significant step forward in the domain of language-conditioned robot control, bridging the gap between semantic understanding and action generation in robotic systems.
Imagination Policy: Using Generative Point Cloud Models for Learning Manipulation Policies
Jun 17, 2024


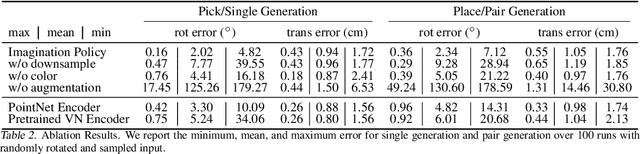
Humans can imagine goal states during planning and perform actions to match those goals. In this work, we propose Imagination Policy, a novel multi-task key-frame policy network for solving high-precision pick and place tasks. Instead of learning actions directly, Imagination Policy generates point clouds to imagine desired states which are then translated to actions using rigid action estimation. This transforms action inference into a local generative task. We leverage pick and place symmetries underlying the tasks in the generation process and achieve extremely high sample efficiency and generalizability to unseen configurations. Finally, we demonstrate state-of-the-art performance across various tasks on the RLbench benchmark compared with several strong baselines.