 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Equivariant Visuomotor Policy Learning via Spherical Projection
May 22, 2025Equivariant models have recently been shown to improve the data efficiency of diffusion policy by a significant margin. However, prior work that explored this direction focused primarily on point cloud inputs generated by multiple cameras fixed in the workspace. This type of point cloud input is not compatible with the now-common setting where the primary input modality is an eye-in-hand RGB camera like a GoPro. This paper closes this gap by incorporating into the diffusion policy model a process that projects features from the 2D RGB camera image onto a sphere. This enables us to reason about symmetries in SO(3) without explicitly reconstructing a point cloud. We perform extensive experiments in both simulation and the real world that demonstrate that our method consistently outperforms strong baselines in terms of both performance and sample efficiency. Our work is the first SO(3)-equivariant policy learning framework for robotic manipulation that works using only monocular RGB inputs.
Coarse-to-Fine 3D Keyframe Transporter
Feb 03, 2025

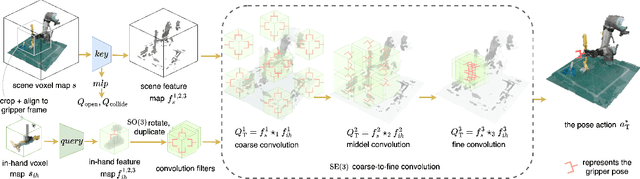
Recent advances in Keyframe Imitation Learning (IL) have enabled learning-based agents to solve a diverse range of manipulation tasks. However, most approaches ignore the rich symmetries in the problem setting and, as a consequence, are sample-inefficient. This work identifies and utilizes the bi-equivariant symmetry within Keyframe IL to design a policy that generalizes to transformations of both the workspace and the objects grasped by the gripper. We make two main contributions: First, we analyze the bi-equivariance properties of the keyframe action scheme and propose a Keyframe Transporter derived from the Transporter Networks, which evaluates actions using cross-correlation between the features of the grasped object and the features of the scene. Second, we propose a computationally efficient coarse-to-fine SE(3) action evaluation scheme for reasoning the intertwined translation and rotation action. The resulting method outperforms strong Keyframe IL baselines by an average of >10% on a wide range of simulation tasks, and by an average of 55% in 4 physical experiments.
Equivariant Reinforcement Learning under Partial Observability
Aug 26, 2024Incorporating inductive biases is a promising approach for tackling challenging robot learning domains with sample-efficient solutions. This paper identifies partially observable domains where symmetries can be a useful inductive bias for efficient learning. Specifically, by encoding the equivariance regarding specific group symmetries into the neural networks, our actor-critic reinforcement learning agents can reuse solutions in the past for related scenarios. Consequently, our equivariant agents outperform non-equivariant approaches significantly in terms of sample efficiency and final performance, demonstrated through experiments on a range of robotic tasks in simulation and real hardware.
Equivariant Offline Reinforcement Learning
Jun 20, 2024Sample efficiency is critical when applying learning-based methods to robotic manipulation due to the high cost of collecting expert demonstrations and the challenges of on-robot policy learning through online Reinforcement Learning (RL). Offline RL addresses this issue by enabling policy learning from an offline dataset collected using any behavioral policy, regardless of its quality. However, recent advancements in offline RL have predominantly focused on learning from large datasets. Given that many robotic manipulation tasks can be formulated as rotation-symmetric problems, we investigate the use of $SO(2)$-equivariant neural networks for offline RL with a limited number of demonstrations. Our experimental results show that equivariant versions of Conservative Q-Learning (CQL) and Implicit Q-Learning (IQL) outperform their non-equivariant counterparts. We provide empirical evidence demonstrating how equivariance improves offline learning algorithms in the low-data regime.
Equivariant Single View Pose Prediction Via Induced and Restricted Representations
Jul 07, 2023Learning about the three-dimensional world from two-dimensional images is a fundamental problem in computer vision. An ideal neural network architecture for such tasks would leverage the fact that objects can be rotated and translated in three dimensions to make predictions about novel images. However, imposing SO(3)-equivariance on two-dimensional inputs is difficult because the group of three-dimensional rotations does not have a natural action on the two-dimensional plane. Specifically, it is possible that an element of SO(3) will rotate an image out of plane. We show that an algorithm that learns a three-dimensional representation of the world from two dimensional images must satisfy certain geometric consistency properties which we formulate as SO(2)-equivariance constraints. We use the induced and restricted representations of SO(2) on SO(3) to construct and classify architectures which satisfy these geometric consistency constraints. We prove that any architecture which respects said consistency constraints can be realized as an instance of our construction. We show that three previously proposed neural architectures for 3D pose prediction are special cases of our construction. We propose a new algorithm that is a learnable generalization of previously considered methods. We test our architecture on three pose predictions task and achieve SOTA results on both the PASCAL3D+ and SYMSOL pose estimation tasks.
SEIL: Simulation-augmented Equivariant Imitation Learning
Oct 31, 2022In robotic manipulation, acquiring samples is extremely expensive because it often requires interacting with the real world. Traditional image-level data augmentation has shown the potential to improve sample efficiency in various machine learning tasks. However, image-level data augmentation is insufficient for an imitation learning agent to learn good manipulation policies in a reasonable amount of demonstrations. We propose Simulation-augmented Equivariant Imitation Learning (SEIL), a method that combines a novel data augmentation strategy of supplementing expert trajectories with simulated transitions and an equivariant model that exploits the $\mathrm{O}(2)$ symmetry in robotic manipulation. Experimental evaluations demonstrate that our method can learn non-trivial manipulation tasks within ten demonstrations and outperforms the baselines with a significant margin.
Graph-Structured Policy Learning for Multi-Goal Manipulation Tasks
Jul 22, 2022
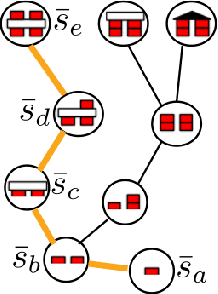
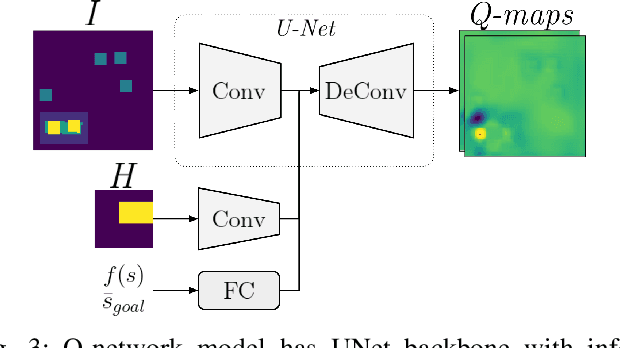
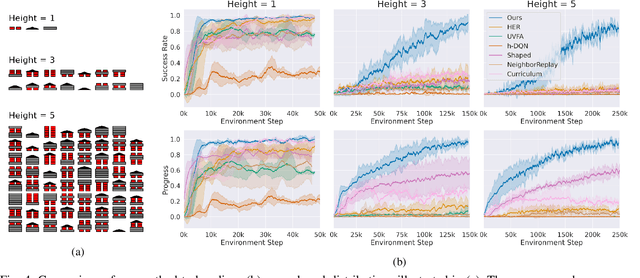
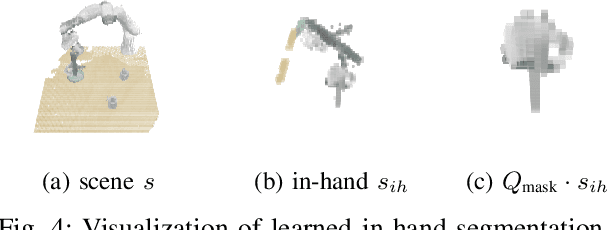
Multi-goal policy learning for robotic manipulation is challenging. Prior successes have used state-based representations of the objects or provided demonstration data to facilitate learning. In this paper, by hand-coding a high-level discrete representation of the domain, we show that policies to reach dozens of goals can be learned with a single network using Q-learning from pixels. The agent focuses learning on simpler, local policies which are sequenced together by planning in the abstract space. We compare our method against standard multi-goal RL baselines, as well as other methods that leverage the discrete representation, on a challenging block construction domain. We find that our method can build more than a hundred different block structures, and demonstrate forward transfer to structures with novel objects. Lastly, we deploy the policy learned in simulation on a real robot.
I2I: Image to Icosahedral Projection for $\mathrm{SO}(3)$ Object Reasoning from Single-View Images
Jul 18, 2022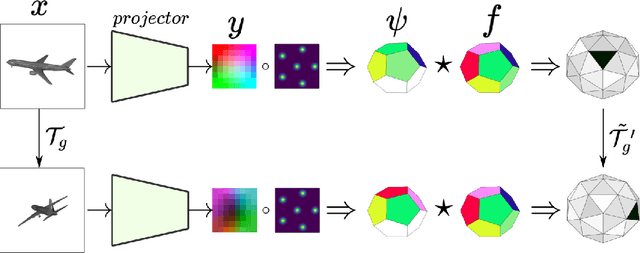
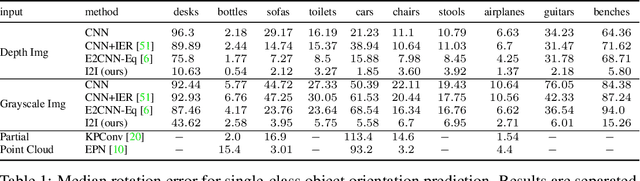
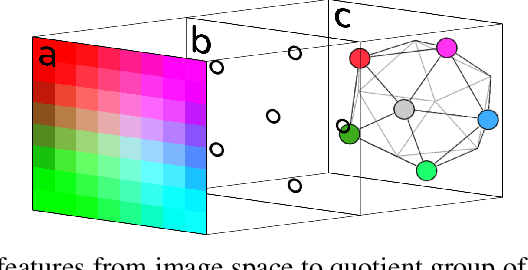
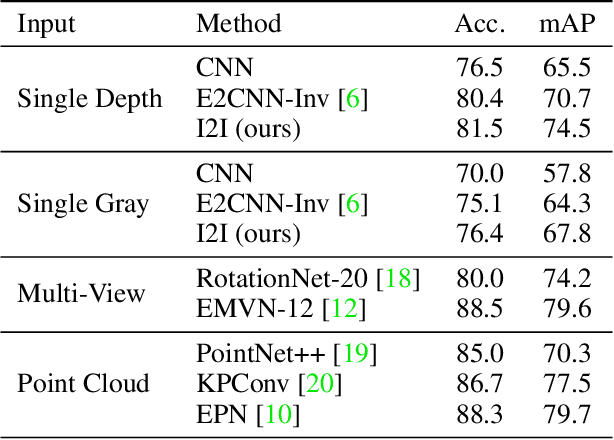
Reasoning about 3D objects based on 2D images is challenging due to large variations in appearance caused by viewing the object from different orientations. Ideally, our model would be invariant or equivariant to changes in object pose. Unfortunately, this is typically not possible with 2D image input because we do not have an a priori model of how the image would change under out-of-plane object rotations. The only $\mathrm{SO}(3)$-equivariant models that currently exist require point cloud input rather than 2D images. In this paper, we propose a novel model architecture based on icosahedral group convolution that reasons in $\mathrm{SO(3)}$ by projecting the input image onto an icosahedron. As a result of this projection, the model is approximately equivariant to rotation in $\mathrm{SO}(3)$. We apply this model to an object pose estimation task and find that it outperforms reasonable baselines.
Factored World Models for Zero-Shot Generalization in Robotic Manipulation
Feb 10, 2022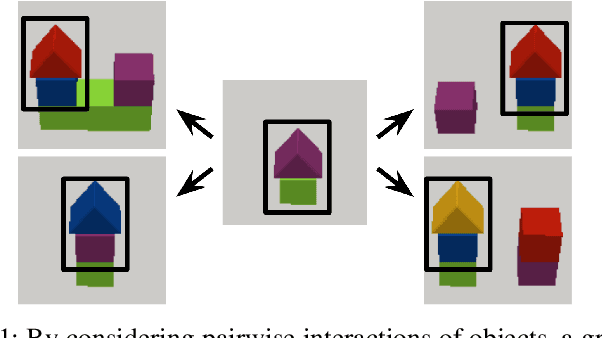

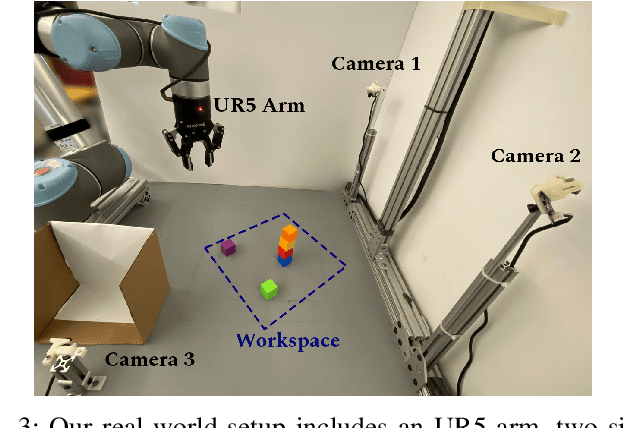
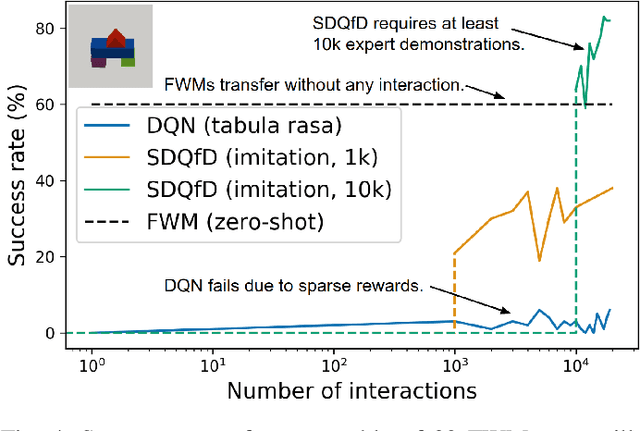
World models for environments with many objects face a combinatorial explosion of states: as the number of objects increases, the number of possible arrangements grows exponentially. In this paper, we learn to generalize over robotic pick-and-place tasks using object-factored world models, which combat the combinatorial explosion by ensuring that predictions are equivariant to permutations of objects. Previous object-factored models were limited either by their inability to model actions, or by their inability to plan for complex manipulation tasks. We build on recent contrastive methods for training object-factored world models, which we extend to model continuous robot actions and to accurately predict the physics of robotic pick-and-place. To do so, we use a residual stack of graph neural networks that receive action information at multiple levels in both their node and edge neural networks. Crucially, our learned model can make predictions about tasks not represented in the training data. That is, we demonstrate successful zero-shot generalization to novel tasks, with only a minor decrease in model performance. Moreover, we show that an ensemble of our models can be used to plan for tasks involving up to 12 pick and place actions using heuristic search. We also demonstrate transfer to a physical robot.