 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoarse-to-Fine 3D Keyframe Transporter
Feb 03, 2025

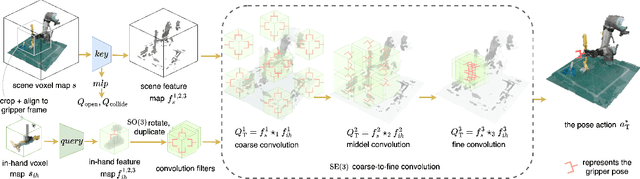
Recent advances in Keyframe Imitation Learning (IL) have enabled learning-based agents to solve a diverse range of manipulation tasks. However, most approaches ignore the rich symmetries in the problem setting and, as a consequence, are sample-inefficient. This work identifies and utilizes the bi-equivariant symmetry within Keyframe IL to design a policy that generalizes to transformations of both the workspace and the objects grasped by the gripper. We make two main contributions: First, we analyze the bi-equivariance properties of the keyframe action scheme and propose a Keyframe Transporter derived from the Transporter Networks, which evaluates actions using cross-correlation between the features of the grasped object and the features of the scene. Second, we propose a computationally efficient coarse-to-fine SE(3) action evaluation scheme for reasoning the intertwined translation and rotation action. The resulting method outperforms strong Keyframe IL baselines by an average of >10% on a wide range of simulation tasks, and by an average of 55% in 4 physical experiments.
Equivariant Offline Reinforcement Learning
Jun 20, 2024Sample efficiency is critical when applying learning-based methods to robotic manipulation due to the high cost of collecting expert demonstrations and the challenges of on-robot policy learning through online Reinforcement Learning (RL). Offline RL addresses this issue by enabling policy learning from an offline dataset collected using any behavioral policy, regardless of its quality. However, recent advancements in offline RL have predominantly focused on learning from large datasets. Given that many robotic manipulation tasks can be formulated as rotation-symmetric problems, we investigate the use of $SO(2)$-equivariant neural networks for offline RL with a limited number of demonstrations. Our experimental results show that equivariant versions of Conservative Q-Learning (CQL) and Implicit Q-Learning (IQL) outperform their non-equivariant counterparts. We provide empirical evidence demonstrating how equivariance improves offline learning algorithms in the low-data regime.
Leveraging Symmetries in Pick and Place
Aug 15, 2023Robotic pick and place tasks are symmetric under translations and rotations of both the object to be picked and the desired place pose. For example, if the pick object is rotated or translated, then the optimal pick action should also rotate or translate. The same is true for the place pose; if the desired place pose changes, then the place action should also transform accordingly. A recently proposed pick and place framework known as Transporter Net captures some of these symmetries, but not all. This paper analytically studies the symmetries present in planar robotic pick and place and proposes a method of incorporating equivariant neural models into Transporter Net in a way that captures all symmetries. The new model, which we call Equivariant Transporter Net, is equivariant to both pick and place symmetries and can immediately generalize pick and place knowledge to different pick and place poses. We evaluate the new model empirically and show that it is much more sample efficient than the non-symmetric version, resulting in a system that can imitate demonstrated pick and place behavior using very few human demonstrations on a variety of imitation learning tasks.
Auxiliary Heuristics for Frontier Based Planners
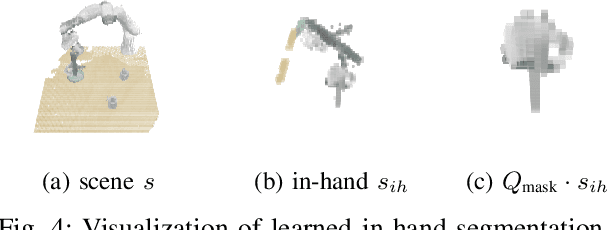
Aug 26, 2021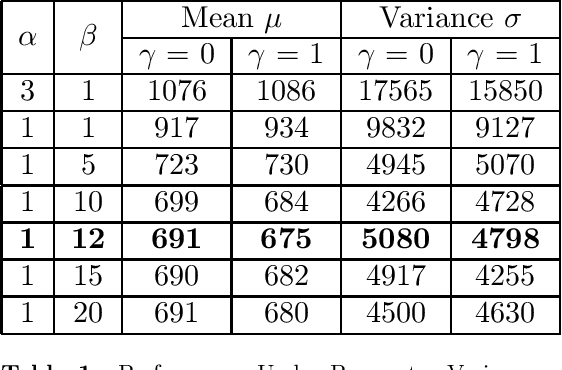
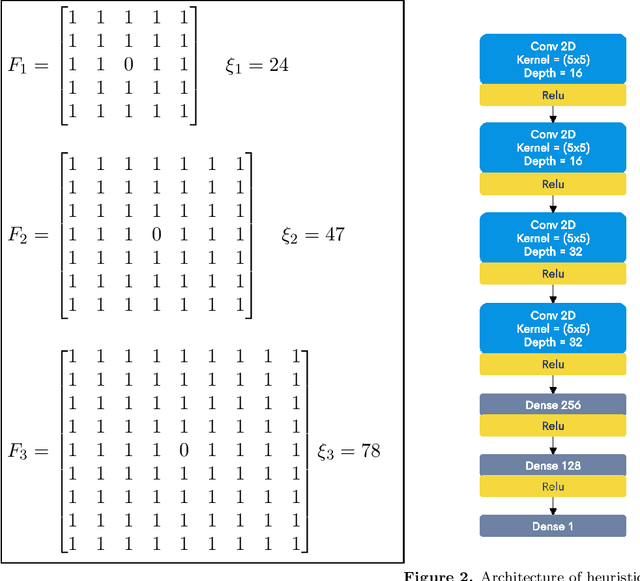
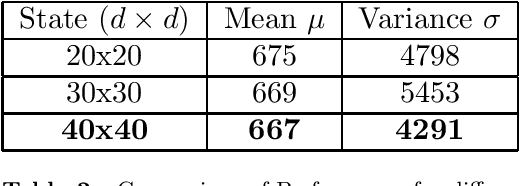
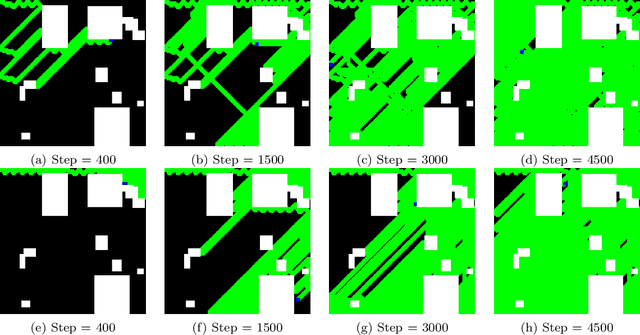
Autonomous exploration of unknown environments is a vital function for robots and has applications in a wide variety of scenarios. Our focus primarily lies in its application for the task of efficient coverage of unknown environments. Various methods have been proposed for this task and frontier based methods are an efficient category in this class of methods. Efficiency is of utmost importance in exploration and heuristics play a critical role in guiding our search. In this work we demonstrate the ability of heuristics that are learnt by imitating clairvoyant oracles. These learnt heuristics can be used to predict the expected future return from selected states without building search trees, which are inefficient and limited by on-board compute. We also propose an additional filter-based heuristic which results in an enhancement in the performance of the frontier-based planner with respect to certain tasks such as coverage planning.