 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTnT-LLM: Text Mining at Scale with Large Language Models
Mar 18, 2024Transforming unstructured text into structured and meaningful forms, organized by useful category labels, is a fundamental step in text mining for downstream analysis and application. However, most existing methods for producing label taxonomies and building text-based label classifiers still rely heavily on domain expertise and manual curation, making the process expensive and time-consuming. This is particularly challenging when the label space is under-specified and large-scale data annotations are unavailable. In this paper, we address these challenges with Large Language Models (LLMs), whose prompt-based interface facilitates the induction and use of large-scale pseudo labels. We propose TnT-LLM, a two-phase framework that employs LLMs to automate the process of end-to-end label generation and assignment with minimal human effort for any given use-case. In the first phase, we introduce a zero-shot, multi-stage reasoning approach which enables LLMs to produce and refine a label taxonomy iteratively. In the second phase, LLMs are used as data labelers that yield training samples so that lightweight supervised classifiers can be reliably built, deployed, and served at scale. We apply TnT-LLM to the analysis of user intent and conversational domain for Bing Copilot (formerly Bing Chat), an open-domain chat-based search engine. Extensive experiments using both human and automatic evaluation metrics demonstrate that TnT-LLM generates more accurate and relevant label taxonomies when compared against state-of-the-art baselines, and achieves a favorable balance between accuracy and efficiency for classification at scale. We also share our practical experiences and insights on the challenges and opportunities of using LLMs for large-scale text mining in real-world applications.
Auxiliary Heuristics for Frontier Based Planners
Aug 26, 2021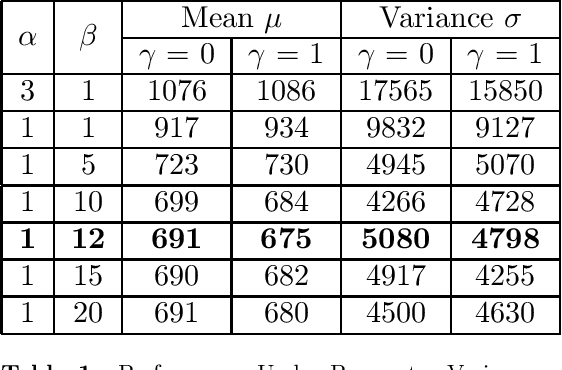
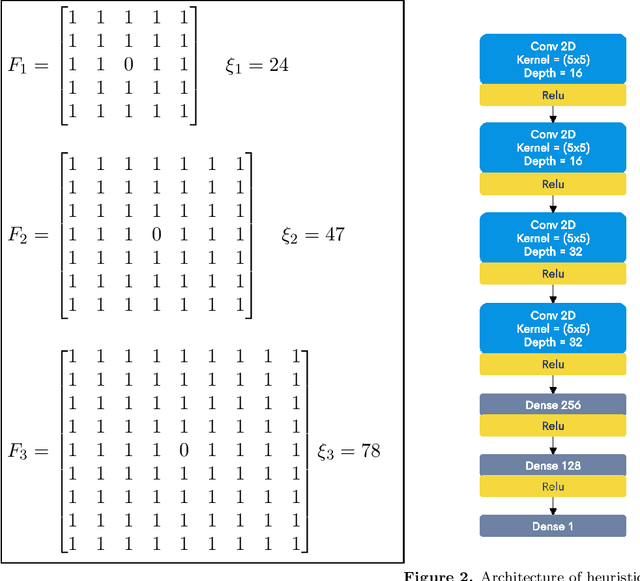
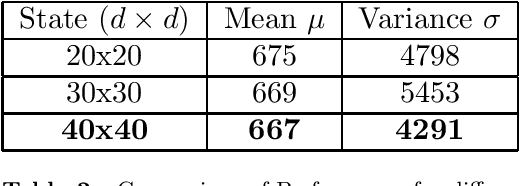
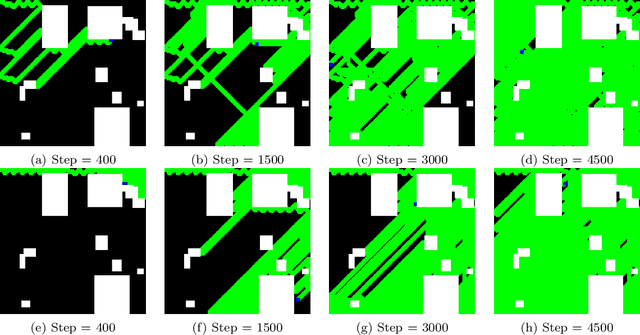
Autonomous exploration of unknown environments is a vital function for robots and has applications in a wide variety of scenarios. Our focus primarily lies in its application for the task of efficient coverage of unknown environments. Various methods have been proposed for this task and frontier based methods are an efficient category in this class of methods. Efficiency is of utmost importance in exploration and heuristics play a critical role in guiding our search. In this work we demonstrate the ability of heuristics that are learnt by imitating clairvoyant oracles. These learnt heuristics can be used to predict the expected future return from selected states without building search trees, which are inefficient and limited by on-board compute. We also propose an additional filter-based heuristic which results in an enhancement in the performance of the frontier-based planner with respect to certain tasks such as coverage planning.