 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRL-VLM-F: Reinforcement Learning from Vision Language Foundation Model Feedback
Feb 10, 2024



Reward engineering has long been a challenge in Reinforcement Learning (RL) research, as it often requires extensive human effort and iterative processes of trial-and-error to design effective reward functions. In this paper, we propose RL-VLM-F, a method that automatically generates reward functions for agents to learn new tasks, using only a text description of the task goal and the agent's visual observations, by leveraging feedbacks from vision language foundation models (VLMs). The key to our approach is to query these models to give preferences over pairs of the agent's image observations based on the text description of the task goal, and then learn a reward function from the preference labels, rather than directly prompting these models to output a raw reward score, which can be noisy and inconsistent. We demonstrate that RL-VLM-F successfully produces effective rewards and policies across various domains - including classic control, as well as manipulation of rigid, articulated, and deformable objects - without the need for human supervision, outperforming prior methods that use large pretrained models for reward generation under the same assumptions.
Force-Constrained Visual Policy: Safe Robot-Assisted Dressing via Multi-Modal Sensing
Nov 07, 2023Robot-assisted dressing could profoundly enhance the quality of life of adults with physical disabilities. To achieve this, a robot can benefit from both visual and force sensing. The former enables the robot to ascertain human body pose and garment deformations, while the latter helps maintain safety and comfort during the dressing process. In this paper, we introduce a new technique that leverages both vision and force modalities for this assistive task. Our approach first trains a vision-based dressing policy using reinforcement learning in simulation with varying body sizes, poses, and types of garments. We then learn a force dynamics model for action planning to ensure safety. Due to limitations of simulating accurate force data when deformable garments interact with the human body, we learn a force dynamics model directly from real-world data. Our proposed method combines the vision-based policy, trained in simulation, with the force dynamics model, learned in the real world, by solving a constrained optimization problem to infer actions that facilitate the dressing process without applying excessive force on the person. We evaluate our system in simulation and in a real-world human study with 10 participants across 240 dressing trials, showing it greatly outperforms prior baselines. Video demonstrations are available on our project website\footnote{\url{https://sites.google.com/view/dressing-fcvp}}.
One Policy to Dress Them All: Learning to Dress People with Diverse Poses and Garments
Jun 21, 2023



Robot-assisted dressing could benefit the lives of many people such as older adults and individuals with disabilities. Despite such potential, robot-assisted dressing remains a challenging task for robotics as it involves complex manipulation of deformable cloth in 3D space. Many prior works aim to solve the robot-assisted dressing task, but they make certain assumptions such as a fixed garment and a fixed arm pose that limit their ability to generalize. In this work, we develop a robot-assisted dressing system that is able to dress different garments on people with diverse poses from partial point cloud observations, based on a learned policy. We show that with proper design of the policy architecture and Q function, reinforcement learning (RL) can be used to learn effective policies with partial point cloud observations that work well for dressing diverse garments. We further leverage policy distillation to combine multiple policies trained on different ranges of human arm poses into a single policy that works over a wide range of different arm poses. We conduct comprehensive real-world evaluations of our system with 510 dressing trials in a human study with 17 participants with different arm poses and dressed garments. Our system is able to dress 86% of the length of the participants' arms on average. Videos can be found on our project webpage: https://sites.google.com/view/one-policy-dress.
ViTCoD: Vision Transformer Acceleration via Dedicated Algorithm and Accelerator Co-Design
Oct 18, 2022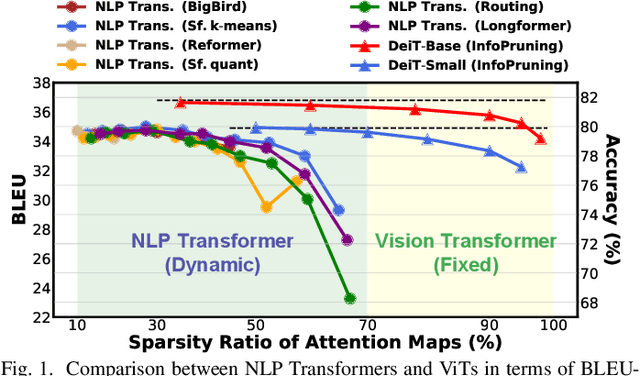


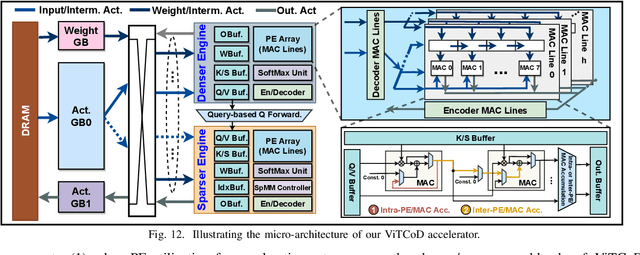
Vision Transformers (ViTs) have achieved state-of-the-art performance on various vision tasks. However, ViTs' self-attention module is still arguably a major bottleneck, limiting their achievable hardware efficiency. Meanwhile, existing accelerators dedicated to NLP Transformers are not optimal for ViTs. This is because there is a large difference between ViTs and NLP Transformers: ViTs have a relatively fixed number of input tokens, whose attention maps can be pruned by up to 90% even with fixed sparse patterns; while NLP Transformers need to handle input sequences of varying numbers of tokens and rely on on-the-fly predictions of dynamic sparse attention patterns for each input to achieve a decent sparsity (e.g., >=50%). To this end, we propose a dedicated algorithm and accelerator co-design framework dubbed ViTCoD for accelerating ViTs. Specifically, on the algorithm level, ViTCoD prunes and polarizes the attention maps to have either denser or sparser fixed patterns for regularizing two levels of workloads without hurting the accuracy, largely reducing the attention computations while leaving room for alleviating the remaining dominant data movements; on top of that, we further integrate a lightweight and learnable auto-encoder module to enable trading the dominant high-cost data movements for lower-cost computations. On the hardware level, we develop a dedicated accelerator to simultaneously coordinate the enforced denser/sparser workloads and encoder/decoder engines for boosted hardware utilization. Extensive experiments and ablation studies validate that ViTCoD largely reduces the dominant data movement costs, achieving speedups of up to 235.3x, 142.9x, 86.0x, 10.1x, and 6.8x over general computing platforms CPUs, EdgeGPUs, GPUs, and prior-art Transformer accelerators SpAtten and Sanger under an attention sparsity of 90%, respectively.
SuperTickets: Drawing Task-Agnostic Lottery Tickets from Supernets via Jointly Architecture Searching and Parameter Pruning
Jul 08, 2022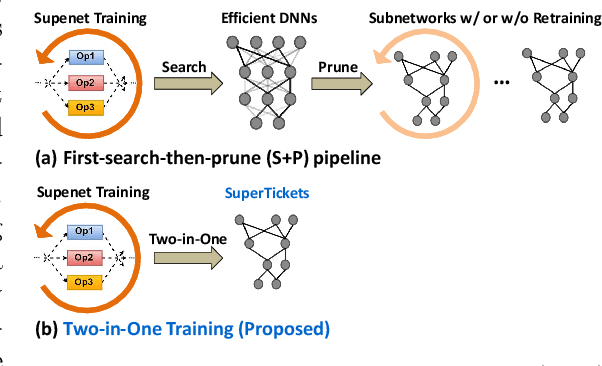

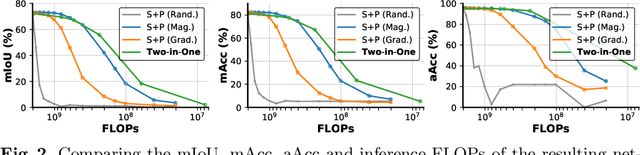

Neural architecture search (NAS) has demonstrated amazing success in searching for efficient deep neural networks (DNNs) from a given supernet. In parallel, the lottery ticket hypothesis has shown that DNNs contain small subnetworks that can be trained from scratch to achieve a comparable or higher accuracy than original DNNs. As such, it is currently a common practice to develop efficient DNNs via a pipeline of first search and then prune. Nevertheless, doing so often requires a search-train-prune-retrain process and thus prohibitive computational cost. In this paper, we discover for the first time that both efficient DNNs and their lottery subnetworks (i.e., lottery tickets) can be directly identified from a supernet, which we term as SuperTickets, via a two-in-one training scheme with jointly architecture searching and parameter pruning. Moreover, we develop a progressive and unified SuperTickets identification strategy that allows the connectivity of subnetworks to change during supernet training, achieving better accuracy and efficiency trade-offs than conventional sparse training. Finally, we evaluate whether such identified SuperTickets drawn from one task can transfer well to other tasks, validating their potential of handling multiple tasks simultaneously. Extensive experiments and ablation studies on three tasks and four benchmark datasets validate that our proposed SuperTickets achieve boosted accuracy and efficiency trade-offs than both typical NAS and pruning pipelines, regardless of having retraining or not. Codes and pretrained models are available at https://github.com/RICE-EIC/SuperTickets.