 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Inference Efficiency to Embodied Efficiency: Revisiting Efficiency Metrics for Vision-Language-Action Models
Mar 19, 2026Vision-Language-Action (VLA) models have recently enabled embodied agents to perform increasingly complex tasks by jointly reasoning over visual, linguistic, and motor modalities. However, we find that the prevailing notion of ``efficiency'' in current VLA research, characterized by parameters, FLOPs, or token decoding throughput, does not reflect actual performance on robotic platforms. In real-world execution, efficiency is determined by system-level embodied behaviors such as task completion time, trajectory smoothness, cumulative joint rotation, and motion energy. Through controlled studies across model compression, token sparsification, and action sequence compression, we make several observations that challenge common assumptions. (1) Methods that reduce computation under conventional metrics often increase end-to-end execution cost or degrade motion quality, despite maintaining task success rates. (2) System-level embodied efficiency metrics reveal performance differences in the learned action policies that remain hidden under conventional evaluations. (3) Common adaptation methods such as in-context prompting or supervised fine-tuning show only mild and metric-specific improvements in embodied efficiency. While these methods can reduce targeted embodied-efficiency metrics such as jerk or action rate, the resulting gains may come with trade-offs in other metrics, such as longer completion time. Taken together, our results suggest that conventional inference efficiency metrics can overlook important aspects of embodied execution. Incorporating embodied efficiency provides a more complete view of policy behavior and practical performance, enabling fairer and more comprehensive comparisons of VLA models.
Early-Bird Diffusion: Investigating and Leveraging Timestep-Aware Early-Bird Tickets in Diffusion Models for Efficient Training
Apr 13, 2025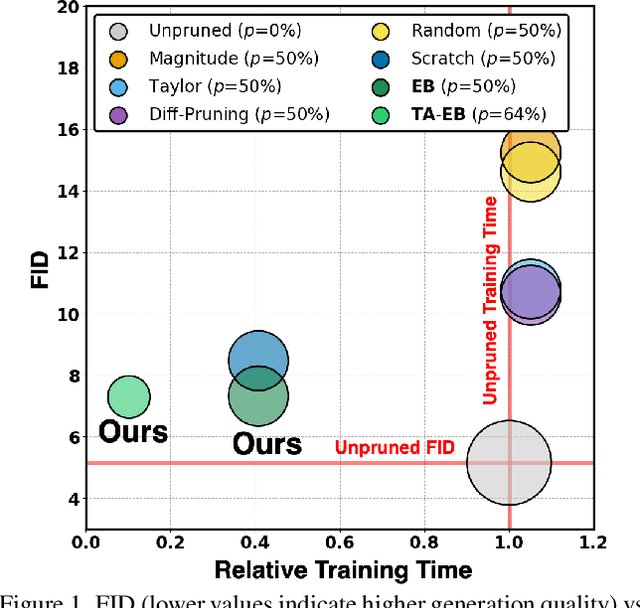
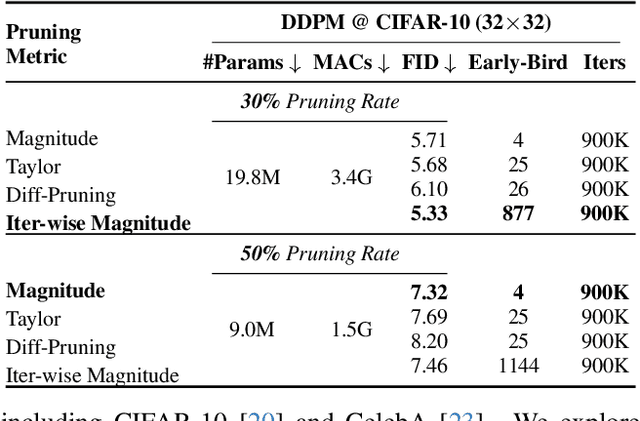
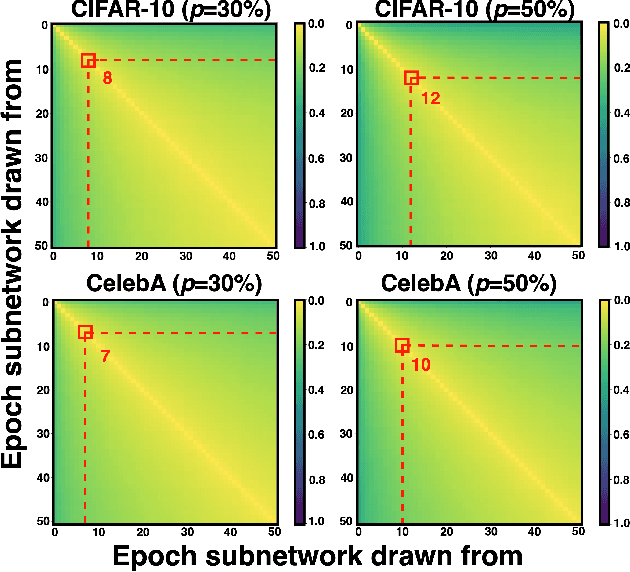
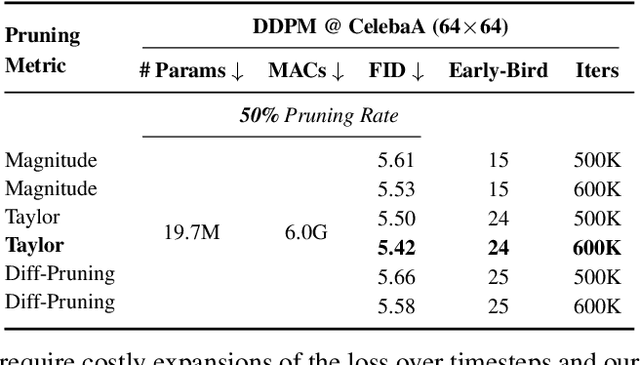
Training diffusion models (DMs) requires substantial computational resources due to multiple forward and backward passes across numerous timesteps, motivating research into efficient training techniques. In this paper, we propose EB-Diff-Train, a new efficient DM training approach that is orthogonal to other methods of accelerating DM training, by investigating and leveraging Early-Bird (EB) tickets -- sparse subnetworks that manifest early in the training process and maintain high generation quality. We first investigate the existence of traditional EB tickets in DMs, enabling competitive generation quality without fully training a dense model. Then, we delve into the concept of diffusion-dedicated EB tickets, drawing on insights from varying importance of different timestep regions. These tickets adapt their sparsity levels according to the importance of corresponding timestep regions, allowing for aggressive sparsity during non-critical regions while conserving computational resources for crucial timestep regions. Building on this, we develop an efficient DM training technique that derives timestep-aware EB tickets, trains them in parallel, and combines them during inference for image generation. Extensive experiments validate the existence of both traditional and timestep-aware EB tickets, as well as the effectiveness of our proposed EB-Diff-Train method. This approach can significantly reduce training time both spatially and temporally -- achieving 2.9$\times$ to 5.8$\times$ speedups over training unpruned dense models, and up to 10.3$\times$ faster training compared to standard train-prune-finetune pipelines -- without compromising generative quality. Our code is available at https://github.com/GATECH-EIC/Early-Bird-Diffusion.
Scaling Laws of Graph Neural Networks for Atomistic Materials Modeling
Apr 10, 2025Atomistic materials modeling is a critical task with wide-ranging applications, from drug discovery to materials science, where accurate predictions of the target material property can lead to significant advancements in scientific discovery. Graph Neural Networks (GNNs) represent the state-of-the-art approach for modeling atomistic material data thanks to their capacity to capture complex relational structures. While machine learning performance has historically improved with larger models and datasets, GNNs for atomistic materials modeling remain relatively small compared to large language models (LLMs), which leverage billions of parameters and terabyte-scale datasets to achieve remarkable performance in their respective domains. To address this gap, we explore the scaling limits of GNNs for atomistic materials modeling by developing a foundational model with billions of parameters, trained on extensive datasets in terabyte-scale. Our approach incorporates techniques from LLM libraries to efficiently manage large-scale data and models, enabling both effective training and deployment of these large-scale GNN models. This work addresses three fundamental questions in scaling GNNs: the potential for scaling GNN model architectures, the effect of dataset size on model accuracy, and the applicability of LLM-inspired techniques to GNN architectures. Specifically, the outcomes of this study include (1) insights into the scaling laws for GNNs, highlighting the relationship between model size, dataset volume, and accuracy, (2) a foundational GNN model optimized for atomistic materials modeling, and (3) a GNN codebase enhanced with advanced LLM-based training techniques. Our findings lay the groundwork for large-scale GNNs with billions of parameters and terabyte-scale datasets, establishing a scalable pathway for future advancements in atomistic materials modeling.
Uni-Render: A Unified Accelerator for Real-Time Rendering Across Diverse Neural Renderers
Mar 31, 2025Recent advancements in neural rendering technologies and their supporting devices have paved the way for immersive 3D experiences, significantly transforming human interaction with intelligent devices across diverse applications. However, achieving the desired real-time rendering speeds for immersive interactions is still hindered by (1) the lack of a universal algorithmic solution for different application scenarios and (2) the dedication of existing devices or accelerators to merely specific rendering pipelines. To overcome this challenge, we have developed a unified neural rendering accelerator that caters to a wide array of typical neural rendering pipelines, enabling real-time and on-device rendering across different applications while maintaining both efficiency and compatibility. Our accelerator design is based on the insight that, although neural rendering pipelines vary and their algorithm designs are continually evolving, they typically share common operators, predominantly executing similar workloads. Building on this insight, we propose a reconfigurable hardware architecture that can dynamically adjust dataflow to align with specific rendering metric requirements for diverse applications, effectively supporting both typical and the latest hybrid rendering pipelines. Benchmarking experiments and ablation studies on both synthetic and real-world scenes demonstrate the effectiveness of the proposed accelerator. The proposed unified accelerator stands out as the first solution capable of achieving real-time neural rendering across varied representative pipelines on edge devices, potentially paving the way for the next generation of neural graphics applications.
Omni-Recon: Towards General-Purpose Neural Radiance Fields for Versatile 3D Applications
Mar 17, 2024Recent breakthroughs in Neural Radiance Fields (NeRFs) have sparked significant demand for their integration into real-world 3D applications. However, the varied functionalities required by different 3D applications often necessitate diverse NeRF models with various pipelines, leading to tedious NeRF training for each target task and cumbersome trial-and-error experiments. Drawing inspiration from the generalization capability and adaptability of emerging foundation models, our work aims to develop one general-purpose NeRF for handling diverse 3D tasks. We achieve this by proposing a framework called Omni-Recon, which is capable of (1) generalizable 3D reconstruction and zero-shot multitask scene understanding, and (2) adaptability to diverse downstream 3D applications such as real-time rendering and scene editing. Our key insight is that an image-based rendering pipeline, with accurate geometry and appearance estimation, can lift 2D image features into their 3D counterparts, thus extending widely explored 2D tasks to the 3D world in a generalizable manner. Specifically, our Omni-Recon features a general-purpose NeRF model using image-based rendering with two decoupled branches: one complex transformer-based branch that progressively fuses geometry and appearance features for accurate geometry estimation, and one lightweight branch for predicting blending weights of source views. This design achieves state-of-the-art (SOTA) generalizable 3D surface reconstruction quality with blending weights reusable across diverse tasks for zero-shot multitask scene understanding. In addition, it can enable real-time rendering after baking the complex geometry branch into meshes, swift adaptation to achieve SOTA generalizable 3D understanding performance, and seamless integration with 2D diffusion models for text-guided 3D editing.
Towards Cognitive AI Systems: a Survey and Prospective on Neuro-Symbolic AI
Jan 02, 2024The remarkable advancements in artificial intelligence (AI), primarily driven by deep neural networks, have significantly impacted various aspects of our lives. However, the current challenges surrounding unsustainable computational trajectories, limited robustness, and a lack of explainability call for the development of next-generation AI systems. Neuro-symbolic AI (NSAI) emerges as a promising paradigm, fusing neural, symbolic, and probabilistic approaches to enhance interpretability, robustness, and trustworthiness while facilitating learning from much less data. Recent NSAI systems have demonstrated great potential in collaborative human-AI scenarios with reasoning and cognitive capabilities. In this paper, we provide a systematic review of recent progress in NSAI and analyze the performance characteristics and computational operators of NSAI models. Furthermore, we discuss the challenges and potential future directions of NSAI from both system and architectural perspectives.
MixRT: Mixed Neural Representations For Real-Time NeRF Rendering
Dec 20, 2023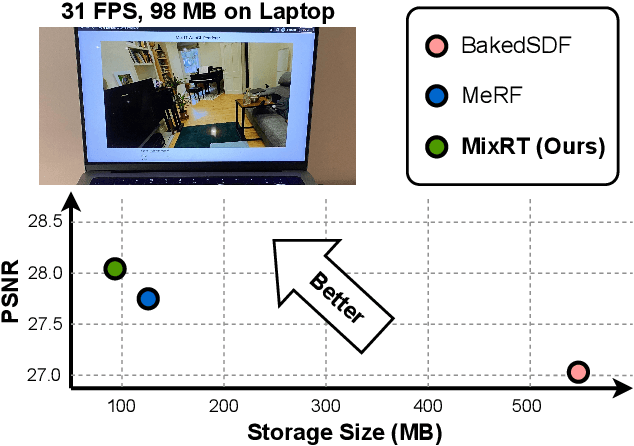

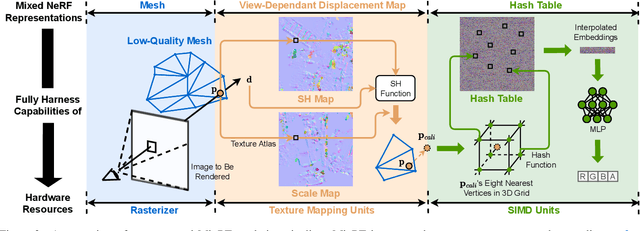

Neural Radiance Field (NeRF) has emerged as a leading technique for novel view synthesis, owing to its impressive photorealistic reconstruction and rendering capability. Nevertheless, achieving real-time NeRF rendering in large-scale scenes has presented challenges, often leading to the adoption of either intricate baked mesh representations with a substantial number of triangles or resource-intensive ray marching in baked representations. We challenge these conventions, observing that high-quality geometry, represented by meshes with substantial triangles, is not necessary for achieving photorealistic rendering quality. Consequently, we propose MixRT, a novel NeRF representation that includes a low-quality mesh, a view-dependent displacement map, and a compressed NeRF model. This design effectively harnesses the capabilities of existing graphics hardware, thus enabling real-time NeRF rendering on edge devices. Leveraging a highly-optimized WebGL-based rendering framework, our proposed MixRT attains real-time rendering speeds on edge devices (over 30 FPS at a resolution of 1280 x 720 on a MacBook M1 Pro laptop), better rendering quality (0.2 PSNR higher in indoor scenes of the Unbounded-360 datasets), and a smaller storage size (less than 80% compared to state-of-the-art methods).
GPT4AIGChip: Towards Next-Generation AI Accelerator Design Automation via Large Language Models
Sep 19, 2023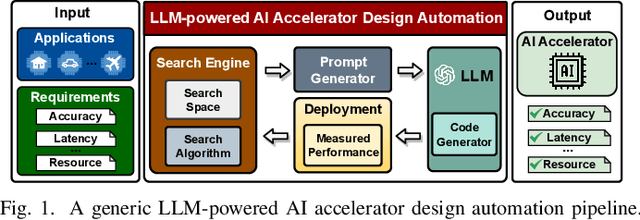
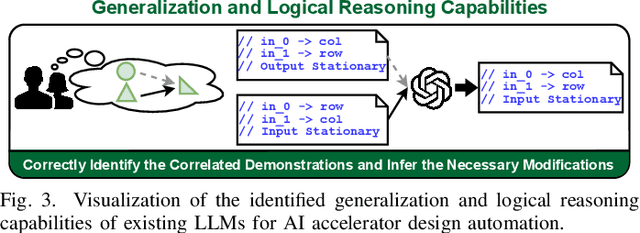
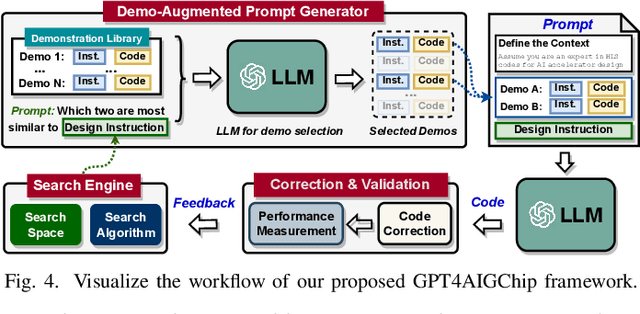
The remarkable capabilities and intricate nature of Artificial Intelligence (AI) have dramatically escalated the imperative for specialized AI accelerators. Nonetheless, designing these accelerators for various AI workloads remains both labor- and time-intensive. While existing design exploration and automation tools can partially alleviate the need for extensive human involvement, they still demand substantial hardware expertise, posing a barrier to non-experts and stifling AI accelerator development. Motivated by the astonishing potential of large language models (LLMs) for generating high-quality content in response to human language instructions, we embark on this work to examine the possibility of harnessing LLMs to automate AI accelerator design. Through this endeavor, we develop GPT4AIGChip, a framework intended to democratize AI accelerator design by leveraging human natural languages instead of domain-specific languages. Specifically, we first perform an in-depth investigation into LLMs' limitations and capabilities for AI accelerator design, thus aiding our understanding of our current position and garnering insights into LLM-powered automated AI accelerator design. Furthermore, drawing inspiration from the above insights, we develop a framework called GPT4AIGChip, which features an automated demo-augmented prompt-generation pipeline utilizing in-context learning to guide LLMs towards creating high-quality AI accelerator design. To our knowledge, this work is the first to demonstrate an effective pipeline for LLM-powered automated AI accelerator generation. Accordingly, we anticipate that our insights and framework can serve as a catalyst for innovations in next-generation LLM-powered design automation tools.
Instant-NeRF: Instant On-Device Neural Radiance Field Training via Algorithm-Accelerator Co-Designed Near-Memory Processing
May 09, 2023
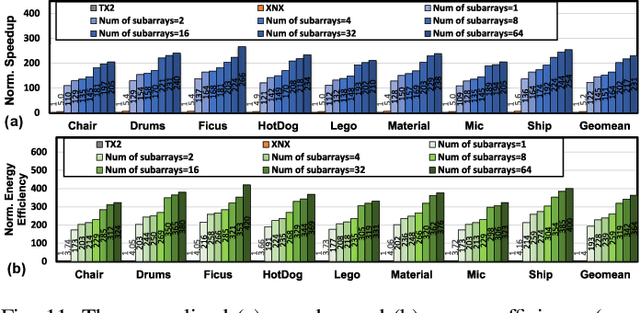
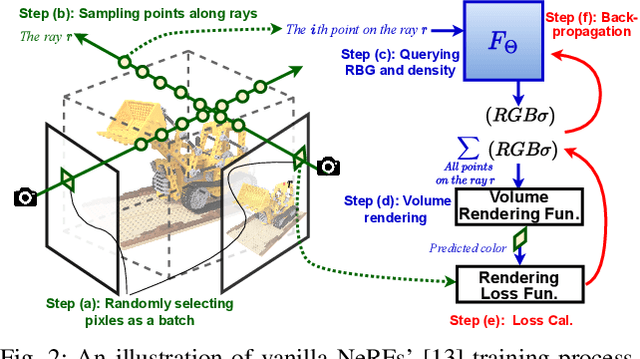
Instant on-device Neural Radiance Fields (NeRFs) are in growing demand for unleashing the promise of immersive AR/VR experiences, but are still limited by their prohibitive training time. Our profiling analysis reveals a memory-bound inefficiency in NeRF training. To tackle this inefficiency, near-memory processing (NMP) promises to be an effective solution, but also faces challenges due to the unique workloads of NeRFs, including the random hash table lookup, random point processing sequence, and heterogeneous bottleneck steps. Therefore, we propose the first NMP framework, Instant-NeRF, dedicated to enabling instant on-device NeRF training. Experiments on eight datasets consistently validate the effectiveness of Instant-NeRF.
ERSAM: Neural Architecture Search For Energy-Efficient and Real-Time Social Ambiance Measurement
Mar 24, 2023Social ambiance describes the context in which social interactions happen, and can be measured using speech audio by counting the number of concurrent speakers. This measurement has enabled various mental health tracking and human-centric IoT applications. While on-device Socal Ambiance Measure (SAM) is highly desirable to ensure user privacy and thus facilitate wide adoption of the aforementioned applications, the required computational complexity of state-of-the-art deep neural networks (DNNs) powered SAM solutions stands at odds with the often constrained resources on mobile devices. Furthermore, only limited labeled data is available or practical when it comes to SAM under clinical settings due to various privacy constraints and the required human effort, further challenging the achievable accuracy of on-device SAM solutions. To this end, we propose a dedicated neural architecture search framework for Energy-efficient and Real-time SAM (ERSAM). Specifically, our ERSAM framework can automatically search for DNNs that push forward the achievable accuracy vs. hardware efficiency frontier of mobile SAM solutions. For example, ERSAM-delivered DNNs only consume 40 mW x 12 h energy and 0.05 seconds processing latency for a 5 seconds audio segment on a Pixel 3 phone, while only achieving an error rate of 14.3% on a social ambiance dataset generated by LibriSpeech. We can expect that our ERSAM framework can pave the way for ubiquitous on-device SAM solutions which are in growing demand.