 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgem4: A Learned Flow-level Network Simulator
Mar 03, 2025



Flow-level simulation is widely used to model large-scale data center networks due to its scalability. Unlike packet-level simulators that model individual packets, flow-level simulators abstract traffic as continuous flows with dynamically assigned transmission rates. While this abstraction enables orders-of-magnitude speedup, it is inaccurate by omitting critical packet-level effects such as queuing, congestion control, and retransmissions. We present m4, an accurate and scalable flow-level simulator that uses machine learning to learn the dynamics of the network of interest. At the core of m4 lies a novel ML architecture that decomposes state transition computations into distinct spatial and temporal components, each represented by a suitable neural network. To efficiently learn the underlying flow-level dynamics, m4 adds dense supervision signals by predicting intermediate network metrics such as remaining flow size and queue length during training. m4 achieves a speedup of up to 104$\times$ over packet-level simulation. Relative to a traditional flow-level simulation, m4 reduces per-flow estimation errors by 45.3% (mean) and 53.0% (p90). For closed-loop applications, m4 accurately predicts network throughput under various congestion control schemes and workloads.
VeriPlan: Integrating Formal Verification and LLMs into End-User Planning
Feb 25, 2025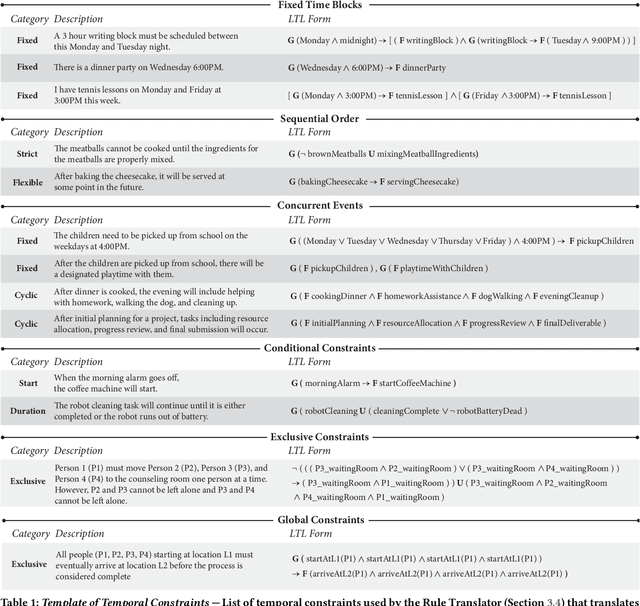



Automated planning is traditionally the domain of experts, utilized in fields like manufacturing and healthcare with the aid of expert planning tools. Recent advancements in LLMs have made planning more accessible to everyday users due to their potential to assist users with complex planning tasks. However, LLMs face several application challenges within end-user planning, including consistency, accuracy, and user trust issues. This paper introduces VeriPlan, a system that applies formal verification techniques, specifically model checking, to enhance the reliability and flexibility of LLMs for end-user planning. In addition to the LLM planner, VeriPlan includes three additional core features -- a rule translator, flexibility sliders, and a model checker -- that engage users in the verification process. Through a user study (n=12), we evaluate VeriPlan, demonstrating improvements in the perceived quality, usability, and user satisfaction of LLMs. Our work shows the effective integration of formal verification and user-control features with LLMs for end-user planning tasks.
Learning Real-World Action-Video Dynamics with Heterogeneous Masked Autoregression
Feb 06, 2025We propose Heterogeneous Masked Autoregression (HMA) for modeling action-video dynamics to generate high-quality data and evaluation in scaling robot learning. Building interactive video world models and policies for robotics is difficult due to the challenge of handling diverse settings while maintaining computational efficiency to run in real time. HMA uses heterogeneous pre-training from observations and action sequences across different robotic embodiments, domains, and tasks. HMA uses masked autoregression to generate quantized or soft tokens for video predictions. \ourshort achieves better visual fidelity and controllability than the previous robotic video generation models with 15 times faster speed in the real world. After post-training, this model can be used as a video simulator from low-level action inputs for evaluating policies and generating synthetic data. See this link https://liruiw.github.io/hma for more information.
Dynamic and Compressive Adaptation of Transformers From Images to Videos
Aug 14, 2024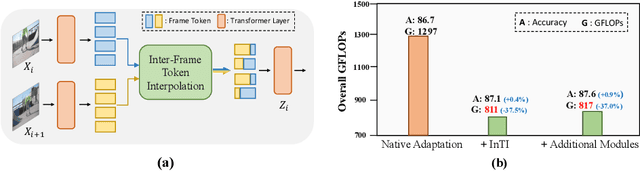
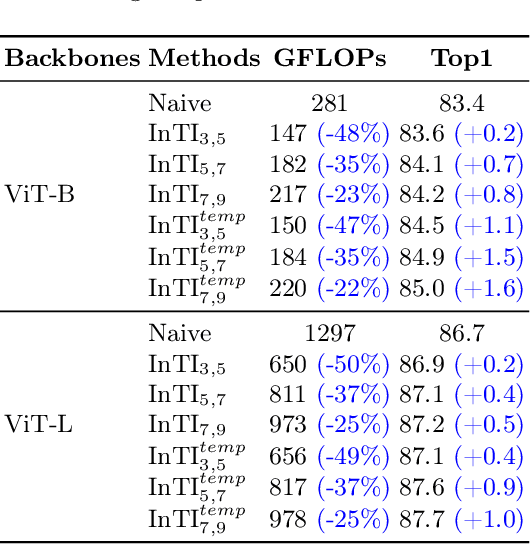
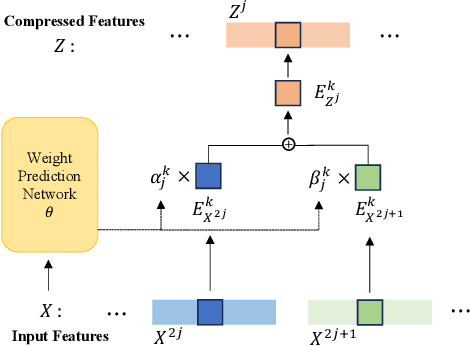
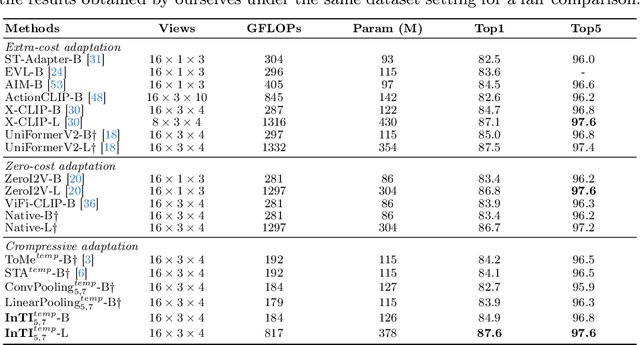
Recently, the remarkable success of pre-trained Vision Transformers (ViTs) from image-text matching has sparked an interest in image-to-video adaptation. However, most current approaches retain the full forward pass for each frame, leading to a high computation overhead for processing entire videos. In this paper, we present InTI, a novel approach for compressive image-to-video adaptation using dynamic Inter-frame Token Interpolation. InTI aims to softly preserve the informative tokens without disrupting their coherent spatiotemporal structure. Specifically, each token pair at identical positions within neighbor frames is linearly aggregated into a new token, where the aggregation weights are generated by a multi-scale context-aware network. In this way, the information of neighbor frames can be adaptively compressed in a point-by-point manner, thereby effectively reducing the number of processed frames by half each time. Importantly, InTI can be seamlessly integrated with existing adaptation methods, achieving strong performance without extra-complex design. On Kinetics-400, InTI reaches a top-1 accuracy of 87.1 with a remarkable 37.5% reduction in GFLOPs compared to naive adaptation. When combined with additional temporal modules, InTI achieves a top-1 accuracy of 87.6 with a 37% reduction in GFLOPs. Similar conclusions have been verified in other common datasets.
Omni-Recon: Towards General-Purpose Neural Radiance Fields for Versatile 3D Applications
Mar 17, 2024Recent breakthroughs in Neural Radiance Fields (NeRFs) have sparked significant demand for their integration into real-world 3D applications. However, the varied functionalities required by different 3D applications often necessitate diverse NeRF models with various pipelines, leading to tedious NeRF training for each target task and cumbersome trial-and-error experiments. Drawing inspiration from the generalization capability and adaptability of emerging foundation models, our work aims to develop one general-purpose NeRF for handling diverse 3D tasks. We achieve this by proposing a framework called Omni-Recon, which is capable of (1) generalizable 3D reconstruction and zero-shot multitask scene understanding, and (2) adaptability to diverse downstream 3D applications such as real-time rendering and scene editing. Our key insight is that an image-based rendering pipeline, with accurate geometry and appearance estimation, can lift 2D image features into their 3D counterparts, thus extending widely explored 2D tasks to the 3D world in a generalizable manner. Specifically, our Omni-Recon features a general-purpose NeRF model using image-based rendering with two decoupled branches: one complex transformer-based branch that progressively fuses geometry and appearance features for accurate geometry estimation, and one lightweight branch for predicting blending weights of source views. This design achieves state-of-the-art (SOTA) generalizable 3D surface reconstruction quality with blending weights reusable across diverse tasks for zero-shot multitask scene understanding. In addition, it can enable real-time rendering after baking the complex geometry branch into meshes, swift adaptation to achieve SOTA generalizable 3D understanding performance, and seamless integration with 2D diffusion models for text-guided 3D editing.
Life after BERT: What do Other Muppets Understand about Language?
May 21, 2022
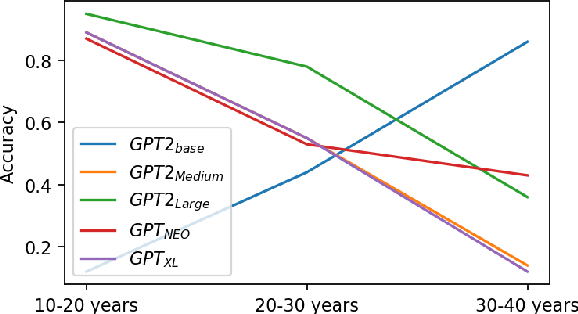

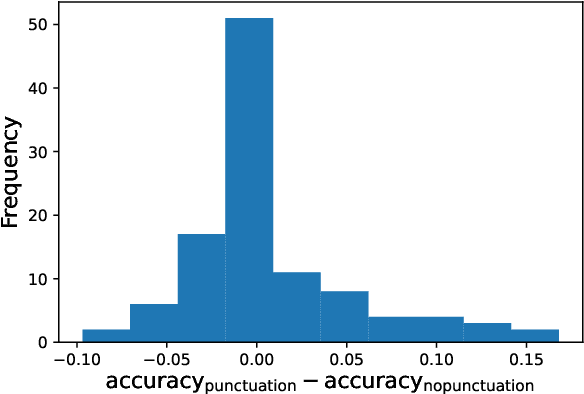
Existing pre-trained transformer analysis works usually focus only on one or two model families at a time, overlooking the variability of the architecture and pre-training objectives. In our work, we utilize the oLMpics benchmark and psycholinguistic probing datasets for a diverse set of 29 models including T5, BART, and ALBERT. Additionally, we adapt the oLMpics zero-shot setup for autoregressive models and evaluate GPT networks of different sizes. Our findings show that none of these models can resolve compositional questions in a zero-shot fashion, suggesting that this skill is not learnable using existing pre-training objectives. Furthermore, we find that global model decisions such as architecture, directionality, size of the dataset, and pre-training objective are not predictive of a model's linguistic capabilities.
Roomsemble: Progressive web application for intuitive property search
Feb 15, 2022



A successful real estate search process involves locating a property that meets a user's search criteria subject to an allocated budget and time constraints. Many studies have investigated modeling housing prices over time. However, little is known about how a user's tastes influence their real estate search and purchase decisions. It is unknown what house a user would choose taking into account an individual's personal tastes, behaviors, and constraints, and, therefore, creating an algorithm that finds the perfect match. In this paper, we investigate the first step in understanding a user's tastes by building a system to capture personal preferences. We concentrated our research on real estate photos, being inspired by house aesthetics, which often motivates prospective buyers into considering a property as a candidate for purchase. We designed a system that takes a user-provided photo representing that person's personal taste and recommends properties similar to the photo available on the market. The user can additionally filter the recommendations by budget and location when conducting a property search. The paper describes the application's overall layout including frontend design and backend processes for locating a desired property. The proposed model, which serves as the application's core, was tested with 25 users, and the study's findings, as well as some key conclusions, are detailed in this paper.
Natural Adversarial Examples
Jul 18, 2019



We introduce natural adversarial examples -- real-world, unmodified, and naturally occurring examples that cause classifier accuracy to significantly degrade. We curate 7,500 natural adversarial examples and release them in an ImageNet classifier test set that we call ImageNet-A. This dataset serves as a new way to measure classifier robustness. Like l_p adversarial examples, ImageNet-A examples successfully transfer to unseen or black-box classifiers. For example, on ImageNet-A a DenseNet-121 obtains around 2% accuracy, an accuracy drop of approximately 90%. Recovering this accuracy is not simple because ImageNet-A examples exploit deep flaws in current classifiers including their over-reliance on color, texture, and background cues. We observe that popular training techniques for improving robustness have little effect, but we show that some architectural changes can enhance robustness to natural adversarial examples. Future research is required to enable robust generalization to this hard ImageNet test set.