 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeconstructing In-Context Learning: Understanding Prompts via Corruption
Apr 02, 2024



The ability of large language models (LLMs) to "learn in context" based on the provided prompt has led to an explosive growth in their use, culminating in the proliferation of AI assistants such as ChatGPT, Claude, and Bard. These AI assistants are known to be robust to minor prompt modifications, mostly due to alignment techniques that use human feedback. In contrast, the underlying pre-trained LLMs they use as a backbone are known to be brittle in this respect. Building high-quality backbone models remains a core challenge, and a common approach to assessing their quality is to conduct few-shot evaluation. Such evaluation is notorious for being highly sensitive to minor prompt modifications, as well as the choice of specific in-context examples. Prior work has examined how modifying different elements of the prompt can affect model performance. However, these earlier studies tended to concentrate on a limited number of specific prompt attributes and often produced contradictory results. Additionally, previous research either focused on models with fewer than 15 billion parameters or exclusively examined black-box models like GPT-3 or PaLM, making replication challenging. In the present study, we decompose the entire prompt into four components: task description, demonstration inputs, labels, and inline instructions provided for each demonstration. We investigate the effects of structural and semantic corruptions of these elements on model performance. We study models ranging from 1.5B to 70B in size, using ten datasets covering classification and generation tasks. We find that repeating text within the prompt boosts model performance, and bigger models ($\geq$30B) are more sensitive to the semantics of the prompt. Finally, we observe that adding task and inline instructions to the demonstrations enhances model performance even when the instructions are semantically corrupted.
Stack More Layers Differently: High-Rank Training Through Low-Rank Updates
Jul 13, 2023



Despite the dominance and effectiveness of scaling, resulting in large networks with hundreds of billions of parameters, the necessity to train overparametrized models remains poorly understood, and alternative approaches do not necessarily make it cheaper to train high-performance models. In this paper, we explore low-rank training techniques as an alternative approach to training large neural networks. We introduce a novel method called ReLoRA, which utilizes low-rank updates to train high-rank networks. We apply ReLoRA to pre-training transformer language models with up to 350M parameters and demonstrate comparable performance to regular neural network training. Furthermore, we observe that the efficiency of ReLoRA increases with model size, making it a promising approach for training multi-billion-parameter networks efficiently. Our findings shed light on the potential of low-rank training techniques and their implications for scaling laws.
Larger Probes Tell a Different Story: Extending Psycholinguistic Datasets Via In-Context Learning
Mar 29, 2023

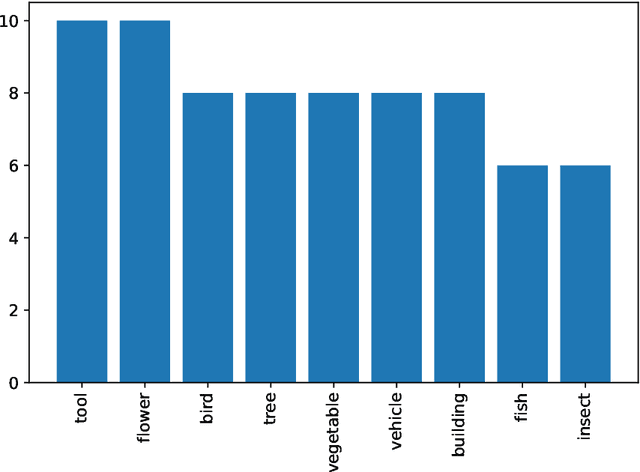
Language model probing is often used to test specific capabilities of these models. However, conclusions from such studies may be limited when the probing benchmarks are small and lack statistical power. In this work, we introduce new, larger datasets for negation (NEG-1500-SIMP) and role reversal (ROLE-1500) inspired by psycholinguistic studies. We dramatically extend existing NEG-136 and ROLE-88 benchmarks using GPT3, increasing their size from 18 and 44 sentence pairs to 750 each. We also create another version of extended negation dataset (NEG-1500-SIMP-TEMP), created using template-based generation. It consists of 770 sentence pairs. We evaluate 22 models on the extended datasets, seeing model performance dip 20-57% compared to the original smaller benchmarks. We observe high levels of negation sensitivity in models like BERT and ALBERT demonstrating that previous findings might have been skewed due to smaller test sets. Finally, we observe that while GPT3 has generated all the examples in ROLE-1500 is only able to solve 24.6% of them during probing.
Life after BERT: What do Other Muppets Understand about Language?
May 21, 2022
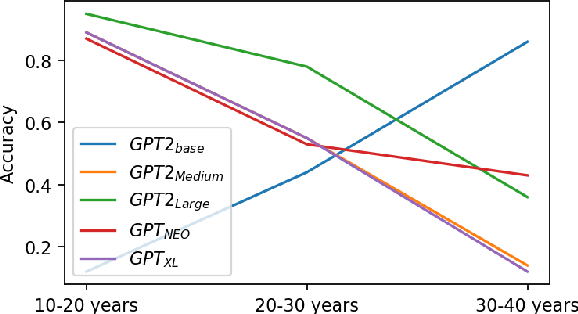

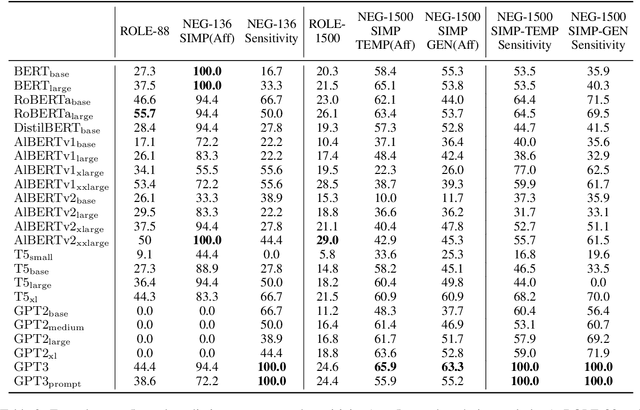
Existing pre-trained transformer analysis works usually focus only on one or two model families at a time, overlooking the variability of the architecture and pre-training objectives. In our work, we utilize the oLMpics benchmark and psycholinguistic probing datasets for a diverse set of 29 models including T5, BART, and ALBERT. Additionally, we adapt the oLMpics zero-shot setup for autoregressive models and evaluate GPT networks of different sizes. Our findings show that none of these models can resolve compositional questions in a zero-shot fashion, suggesting that this skill is not learnable using existing pre-training objectives. Furthermore, we find that global model decisions such as architecture, directionality, size of the dataset, and pre-training objective are not predictive of a model's linguistic capabilities.
Down and Across: Introducing Crossword-Solving as a New NLP Benchmark
May 20, 2022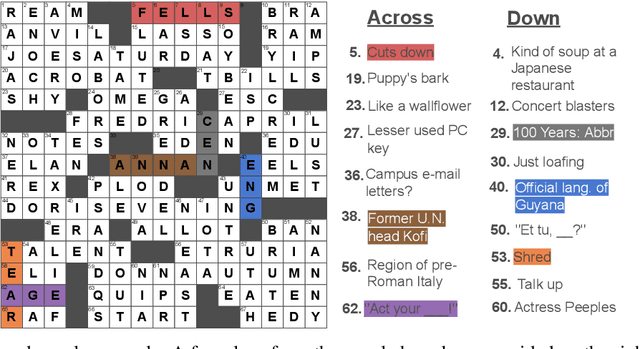
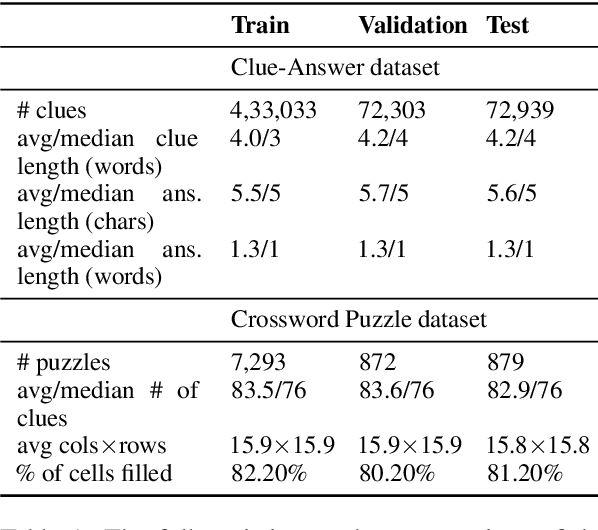
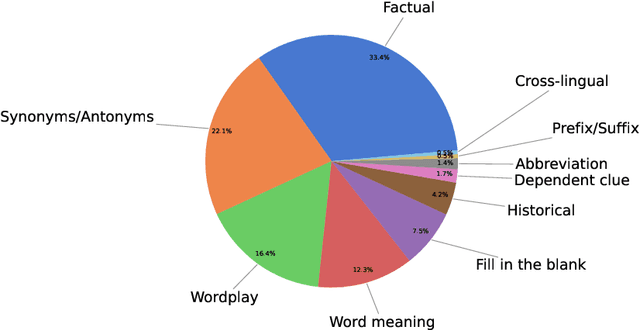

Solving crossword puzzles requires diverse reasoning capabilities, access to a vast amount of knowledge about language and the world, and the ability to satisfy the constraints imposed by the structure of the puzzle. In this work, we introduce solving crossword puzzles as a new natural language understanding task. We release the specification of a corpus of crossword puzzles collected from the New York Times daily crossword spanning 25 years and comprised of a total of around nine thousand puzzles. These puzzles include a diverse set of clues: historic, factual, word meaning, synonyms/antonyms, fill-in-the-blank, abbreviations, prefixes/suffixes, wordplay, and cross-lingual, as well as clues that depend on the answers to other clues. We separately release the clue-answer pairs from these puzzles as an open-domain question answering dataset containing over half a million unique clue-answer pairs. For the question answering task, our baselines include several sequence-to-sequence and retrieval-based generative models. We also introduce a non-parametric constraint satisfaction baseline for solving the entire crossword puzzle. Finally, we propose an evaluation framework which consists of several complementary performance metrics.