 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdMath: A Dataset of Crowdsourced Mathematical Research Discussions
Jun 02, 2026Large language models have made substantial progress on mathematical reasoning, but existing benchmarks typically evaluate well-specified problems with final answers, step-by-step solutions, or complete proofs. They do not capture collaborative open-problem solving: a setting in which participants propose partial arguments, identify gaps or errors in prior steps, repair flawed reasoning, and gradually synthesize incremental contributions into a proof. We introduce CrowdMath, a dataset of 164 expert-annotated progress chains from the MIT PRIMES--Art of Problem Solving (AoPS) CrowdMath program (2016-2025), a collaborative research initiative whose discussions have led to peer-reviewed publications. Each chain traces a multi-participant forum discussion from an open-problem statement to a completed proof. Posts are labeled by their functional roles in the evolving solution process, including partial progress, proof completion, erroneous reasoning, and error identification. We define evaluation tasks and benchmark six frontier models. Models achieve 83-88% accuracy on next-post prediction, suggesting that they can follow the local flow of mathematical discussion. However, they struggle to identify the functional significance of individual contributions with the best model achieving only 0.42 macro-F1 on post-role classification. CrowdMath exposes a gap between solving well-specified mathematical problems and understanding collaborative mathematical progress as it unfolds.
A Pre-Training Analogue of Grokking in Language Models: Tracing Delayed Grammatical Generalization
May 29, 2026Grokking, the phenomenon in which neural networks generalize long after fitting their training data, has been studied in supervised settings on many epochs. LLM pre-training instead involves next-token prediction over an unlabeled corpus, with limited data repetition and no explicit train/validation split. To address this, we propose an exposure-based framework that enables the study of grokking-like dynamics during LLM pre-training. We ground our evaluation in BLiMP minimal pairs, which provide controlled grammatical contrasts. For every BLiMP minimal pair, we identify a critical phrase, the smallest continuous span that captures the grammatical contrast and the phenomenon-relevant context. Examples whose critical phrase appears in the pre-training window are assigned to the proxy-train split; the remaining examples are assigned to the proxy-validation split. Across five grammatical phenomena, we observe delayed generalization. Analyzing pre-training checkpoints before and after generalization shows that grammatical concept vectors become more predictive of grammatical acceptability and occupy a higher-dimensional subspace after generalization. We also find that attention from the critical token to the relevant context token is concentrated in a small number of heads.
Playing with Words, Improving with Rewards: Training Language Models for Creative Association
May 27, 2026Large Language Models (LLMs) are being applied to increasingly difficult problems and use cases. To navigate their vast solution spaces effectively, LLMs need to be creative. Yet the subjective nature of creativity and the limits of human judgment make training LLMs for creativity especially challenging. As a solution, we train LLMs on Codenames, a word-association game that exercises the two central axes of creativity, divergent and convergent thinking, while yielding objectively verifiable outcomes. This verifiability lets us bypass human judgment and train with Reinforcement Learning with Verifiable Rewards (RLVR). We train Qwen3-1.7B, 4B, and 8B models and evaluate them on ten creativity and four reasoning benchmarks. We find that the precision-diversity trade-off is scale-dependent: the 8B model prioritizes creativity over precision, while the 1.7B and 4B models gain reasoning precision at the cost of creativity. Concretely, the 8B model shows modest but consistent creativity gains (8 of 10 benchmarks) with only minor reasoning degradation, whereas the smaller models achieve substantial gains on reasoning tasks. Our study presents a scalable and effective solution to train LLMs for creativity.
Beyond Perplexity: A Geometric and Spectral Study of Low-Rank Pre-Training
May 13, 2026Pre-training large language models is dominated by the memory cost of storing full-rank weights, gradients, and optimizer states. Low-rank pre-training has emerged to address this, and the space of methods has grown rapidly. A central question remains open: do low-rank methods produce models that generalize comparably to full-rank training, or does the rank constraint fundamentally alter the solutions reached? Existing comparisons rely almost entirely on validation perplexity from single-seed runs, often carried forward from prior literature. Yet perplexity is a poor proxy for solution quality; two methods can match on perplexity while converging to different loss landscape regions and internal representations. We close this gap by characterizing the solutions found by five low-rank pre-training methods, GaLore and Fira (memory-efficient optimizers), CoLA and SLTrain (architecture reparameterizations), and ReLoRA (adapter-style updates with periodic resets), against full-rank training at three model scales (60M, 130M, 350M). We evaluate each along 16 metrics across four dimensions: 1-D loss landscape along random/top-K PCA directions, 1-D interpolation between checkpoints, spectral structure of the weights and learned updates, and activation similarity to full-rank training. We show that low-rank methods are not equivalent to full-rank training, nor to one another, even when validation perplexity is close. Full-rank training settles into a sharper basin than low-rank methods along random directions, while the reverse holds for the top-1 PCA direction. Each method converges to a geometrically distinct basin. Low-rank activations diverge from full-rank in later layers as training progresses, with GaLore tracking full-rank most closely. Further, validation perplexity does not translate to downstream performance at every scale. Adding geometric and spectral metrics improves the prediction.
Emergent Abilities in Reduced-Scale Generative Language Models
Apr 02, 2024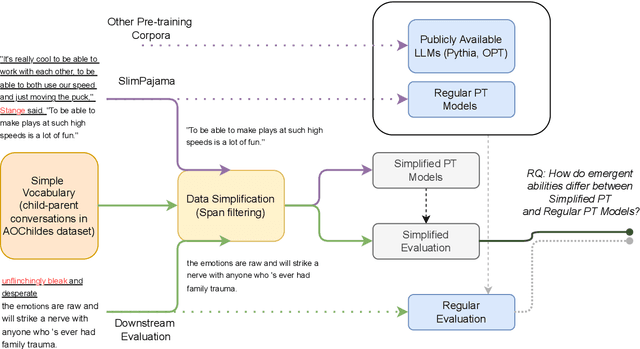
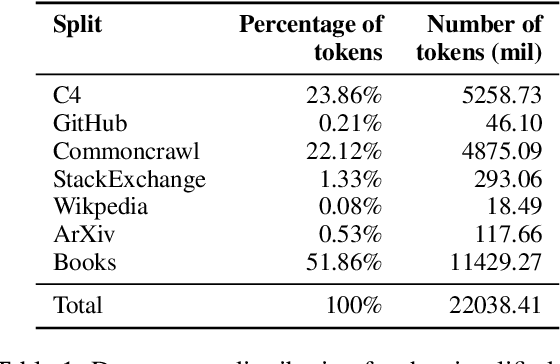
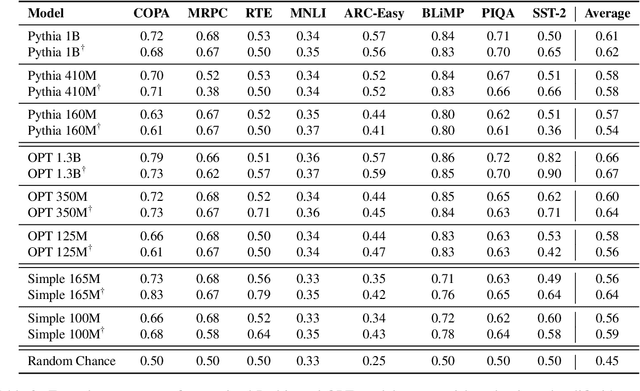
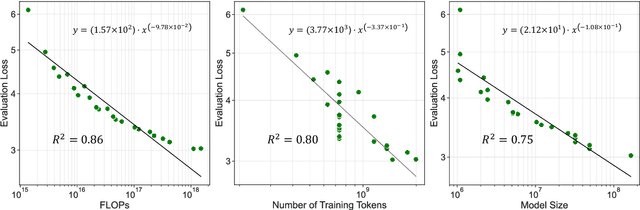
Large language models can solve new tasks without task-specific fine-tuning. This ability, also known as in-context learning (ICL), is considered an emergent ability and is primarily seen in large language models with billions of parameters. This study investigates if such emergent properties are strictly tied to model size or can be demonstrated by smaller models trained on reduced-scale data. To explore this, we simplify pre-training data and pre-train 36 causal language models with parameters varying from 1 million to 165 million parameters. We show that models trained on this simplified pre-training data demonstrate enhanced zero-shot capabilities across various tasks in simplified language, achieving performance comparable to that of pre-trained models six times larger on unrestricted language. This suggests that downscaling the language allows zero-shot learning capabilities to emerge in models with limited size. Additionally, we find that these smaller models pre-trained on simplified data demonstrate a power law relationship between the evaluation loss and the three scaling factors: compute, dataset size, and model size.
Deconstructing In-Context Learning: Understanding Prompts via Corruption
Apr 02, 2024



The ability of large language models (LLMs) to "learn in context" based on the provided prompt has led to an explosive growth in their use, culminating in the proliferation of AI assistants such as ChatGPT, Claude, and Bard. These AI assistants are known to be robust to minor prompt modifications, mostly due to alignment techniques that use human feedback. In contrast, the underlying pre-trained LLMs they use as a backbone are known to be brittle in this respect. Building high-quality backbone models remains a core challenge, and a common approach to assessing their quality is to conduct few-shot evaluation. Such evaluation is notorious for being highly sensitive to minor prompt modifications, as well as the choice of specific in-context examples. Prior work has examined how modifying different elements of the prompt can affect model performance. However, these earlier studies tended to concentrate on a limited number of specific prompt attributes and often produced contradictory results. Additionally, previous research either focused on models with fewer than 15 billion parameters or exclusively examined black-box models like GPT-3 or PaLM, making replication challenging. In the present study, we decompose the entire prompt into four components: task description, demonstration inputs, labels, and inline instructions provided for each demonstration. We investigate the effects of structural and semantic corruptions of these elements on model performance. We study models ranging from 1.5B to 70B in size, using ten datasets covering classification and generation tasks. We find that repeating text within the prompt boosts model performance, and bigger models ($\geq$30B) are more sensitive to the semantics of the prompt. Finally, we observe that adding task and inline instructions to the demonstrations enhances model performance even when the instructions are semantically corrupted.
Let's Reinforce Step by Step
Nov 10, 2023

While recent advances have boosted LM proficiency in linguistic benchmarks, LMs consistently struggle to reason correctly on complex tasks like mathematics. We turn to Reinforcement Learning from Human Feedback (RLHF) as a method with which to shape model reasoning processes. In particular, we explore two reward schemes, outcome-supervised reward models (ORMs) and process-supervised reward models (PRMs), to optimize for logical reasoning. Our results show that the fine-grained reward provided by PRM-based methods enhances accuracy on simple mathematical reasoning (GSM8K) while, unexpectedly, reducing performance in complex tasks (MATH). Furthermore, we show the critical role reward aggregation functions play in model performance. Providing promising avenues for future research, our study underscores the need for further exploration into fine-grained reward modeling for more reliable language models.
Stack More Layers Differently: High-Rank Training Through Low-Rank Updates
Jul 13, 2023



Despite the dominance and effectiveness of scaling, resulting in large networks with hundreds of billions of parameters, the necessity to train overparametrized models remains poorly understood, and alternative approaches do not necessarily make it cheaper to train high-performance models. In this paper, we explore low-rank training techniques as an alternative approach to training large neural networks. We introduce a novel method called ReLoRA, which utilizes low-rank updates to train high-rank networks. We apply ReLoRA to pre-training transformer language models with up to 350M parameters and demonstrate comparable performance to regular neural network training. Furthermore, we observe that the efficiency of ReLoRA increases with model size, making it a promising approach for training multi-billion-parameter networks efficiently. Our findings shed light on the potential of low-rank training techniques and their implications for scaling laws.
Properties Of Winning Tickets On Skin Lesion Classification
Aug 25, 2020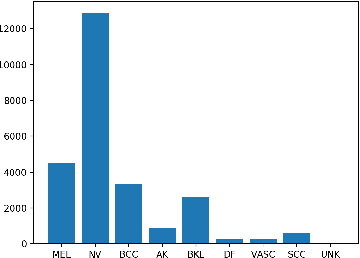
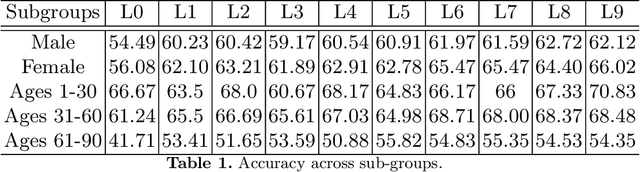
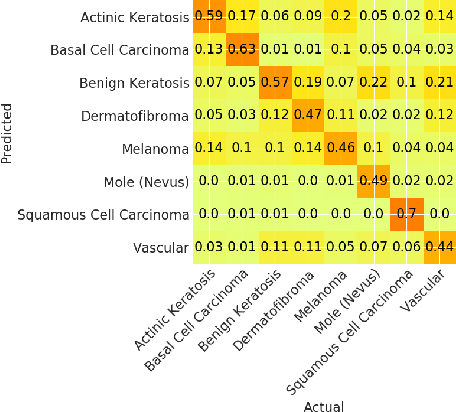
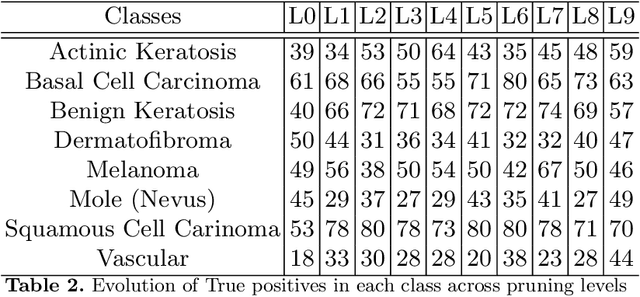
Skin cancer affects a large population every year -- automated skin cancer detection algorithms can thus greatly help clinicians. Prior efforts involving deep learning models have high detection accuracy. However, most of the models have a large number of parameters, with some works even using an ensemble of models to achieve good accuracy. In this paper, we investigate a recently proposed pruning technique called Lottery Ticket Hypothesis. We find that iterative pruning of the network resulted in improved accuracy, compared to that of the unpruned network, implying that -- the lottery ticket hypothesis can be applied to the problem of skin cancer detection and this hypothesis can result in a smaller network for inference. We also examine the accuracy across sub-groups -- created by gender and age -- and it was found that some sub-groups show a larger increase in accuracy than others.