 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergent Abilities in Reduced-Scale Generative Language Models
Paper and Code
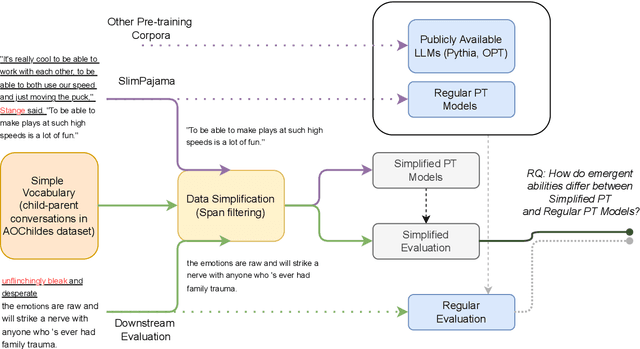
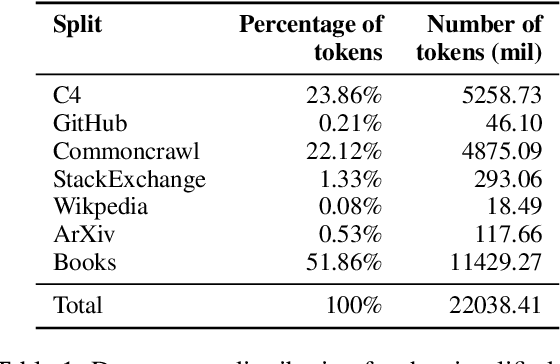
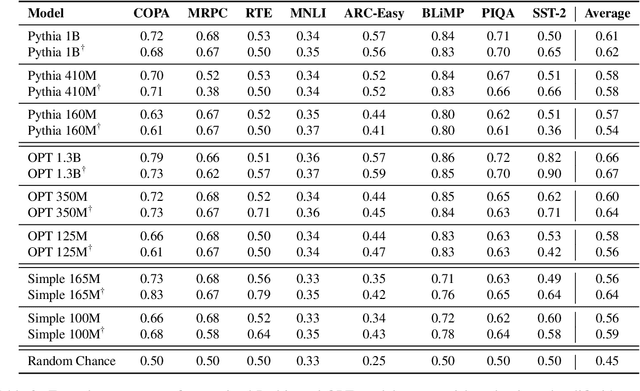
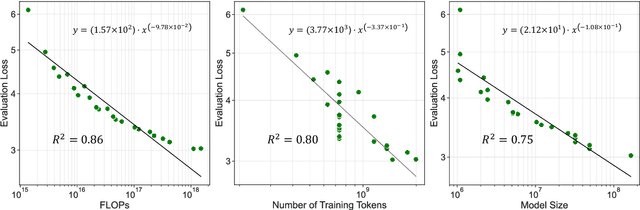
Large language models can solve new tasks without task-specific fine-tuning. This ability, also known as in-context learning (ICL), is considered an emergent ability and is primarily seen in large language models with billions of parameters. This study investigates if such emergent properties are strictly tied to model size or can be demonstrated by smaller models trained on reduced-scale data. To explore this, we simplify pre-training data and pre-train 36 causal language models with parameters varying from 1 million to 165 million parameters. We show that models trained on this simplified pre-training data demonstrate enhanced zero-shot capabilities across various tasks in simplified language, achieving performance comparable to that of pre-trained models six times larger on unrestricted language. This suggests that downscaling the language allows zero-shot learning capabilities to emerge in models with limited size. Additionally, we find that these smaller models pre-trained on simplified data demonstrate a power law relationship between the evaluation loss and the three scaling factors: compute, dataset size, and model size.