 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiverse, not Short: A Length-Controlled Self-Learning Framework for Improving Response Diversity of Language Models
May 22, 2025
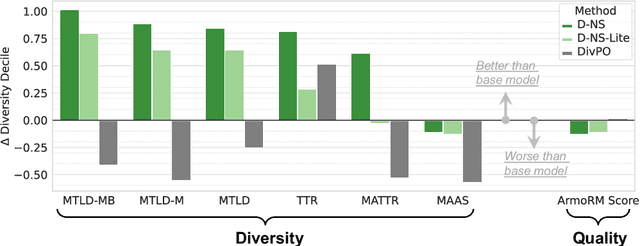
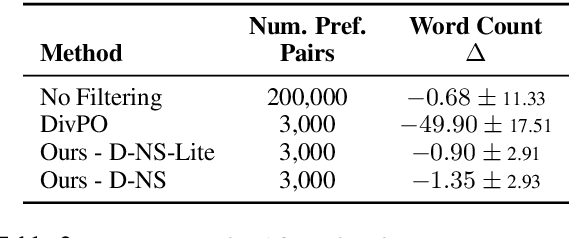
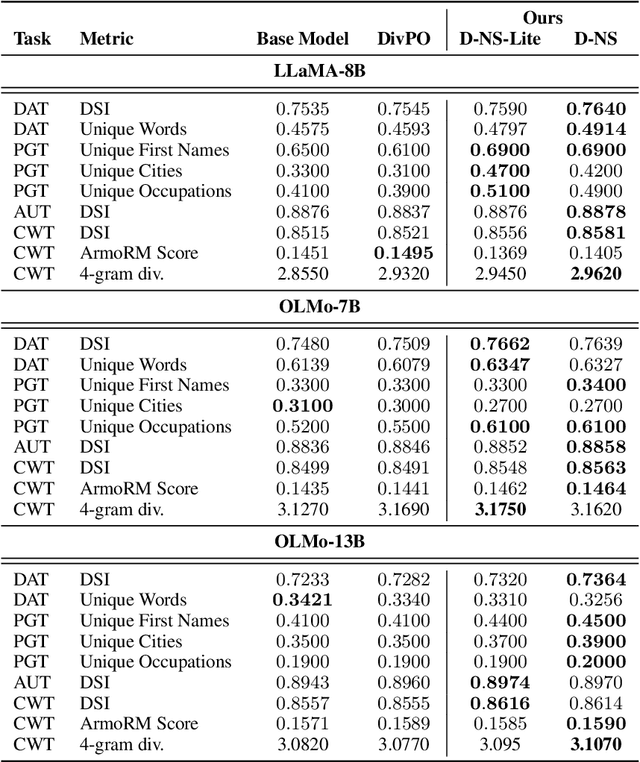
Diverse language model responses are crucial for creative generation, open-ended tasks, and self-improvement training. We show that common diversity metrics, and even reward models used for preference optimization, systematically bias models toward shorter outputs, limiting expressiveness. To address this, we introduce Diverse, not Short (Diverse-NS), a length-controlled self-learning framework that improves response diversity while maintaining length parity. By generating and filtering preference data that balances diversity, quality, and length, Diverse-NS enables effective training using only 3,000 preference pairs. Applied to LLaMA-3.1-8B and the Olmo-2 family, Diverse-NS substantially enhances lexical and semantic diversity. We show consistent improvement in diversity with minor reduction or gains in response quality on four creative generation tasks: Divergent Associations, Persona Generation, Alternate Uses, and Creative Writing. Surprisingly, experiments with the Olmo-2 model family (7B, and 13B) show that smaller models like Olmo-2-7B can serve as effective "diversity teachers" for larger models. By explicitly addressing length bias, our method efficiently pushes models toward more diverse and expressive outputs.
Emergent Abilities in Reduced-Scale Generative Language Models
Apr 02, 2024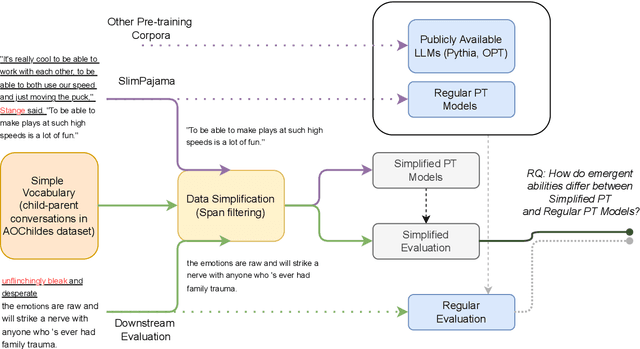
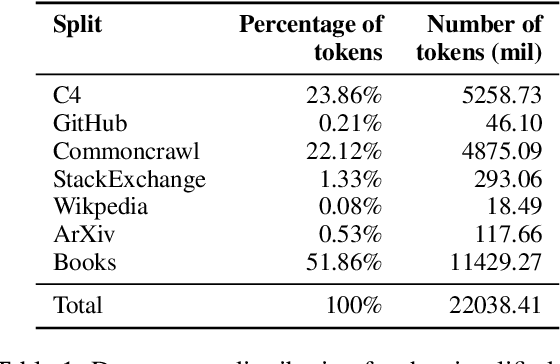
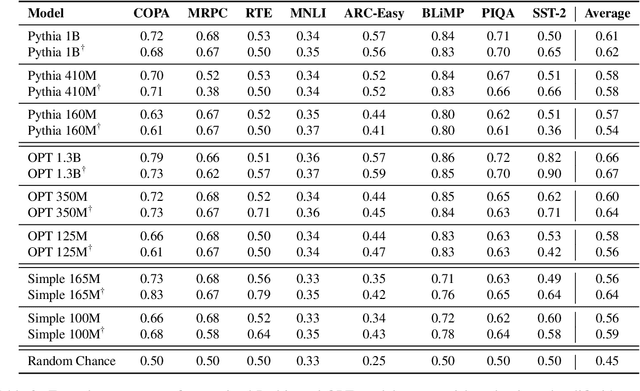
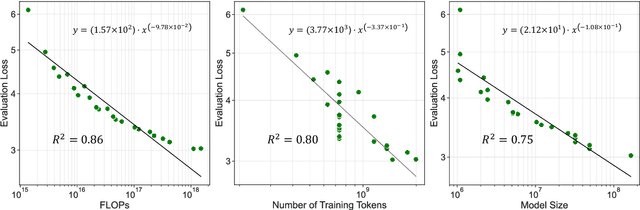
Large language models can solve new tasks without task-specific fine-tuning. This ability, also known as in-context learning (ICL), is considered an emergent ability and is primarily seen in large language models with billions of parameters. This study investigates if such emergent properties are strictly tied to model size or can be demonstrated by smaller models trained on reduced-scale data. To explore this, we simplify pre-training data and pre-train 36 causal language models with parameters varying from 1 million to 165 million parameters. We show that models trained on this simplified pre-training data demonstrate enhanced zero-shot capabilities across various tasks in simplified language, achieving performance comparable to that of pre-trained models six times larger on unrestricted language. This suggests that downscaling the language allows zero-shot learning capabilities to emerge in models with limited size. Additionally, we find that these smaller models pre-trained on simplified data demonstrate a power law relationship between the evaluation loss and the three scaling factors: compute, dataset size, and model size.
LocalTweets to LocalHealth: A Mental Health Surveillance Framework Based on Twitter Data
Feb 21, 2024Prior research on Twitter (now X) data has provided positive evidence of its utility in developing supplementary health surveillance systems. In this study, we present a new framework to surveil public health, focusing on mental health (MH) outcomes. We hypothesize that locally posted tweets are indicative of local MH outcomes and collect tweets posted from 765 neighborhoods (census block groups) in the USA. We pair these tweets from each neighborhood with the corresponding MH outcome reported by the Center for Disease Control (CDC) to create a benchmark dataset, LocalTweets. With LocalTweets, we present the first population-level evaluation task for Twitter-based MH surveillance systems. We then develop an efficient and effective method, LocalHealth, for predicting MH outcomes based on LocalTweets. When used with GPT3.5, LocalHealth achieves the highest F1-score and accuracy of 0.7429 and 79.78\%, respectively, a 59\% improvement in F1-score over the GPT3.5 in zero-shot setting. We also utilize LocalHealth to extrapolate CDC's estimates to proxy unreported neighborhoods, achieving an F1-score of 0.7291. Our work suggests that Twitter data can be effectively leveraged to simulate neighborhood-level MH outcomes.
Honey, I Shrunk the Language: Language Model Behavior at Reduced Scale
May 30, 2023In recent years, language models have drastically grown in size, and the abilities of these models have been shown to improve with scale. The majority of recent scaling laws studies focused on high-compute high-parameter count settings, leaving the question of when these abilities begin to emerge largely unanswered. In this paper, we investigate whether the effects of pre-training can be observed when the problem size is reduced, modeling a smaller, reduced-vocabulary language. We show the benefits of pre-training with masked language modeling (MLM) objective in models as small as 1.25M parameters, and establish a strong correlation between pre-training perplexity and downstream performance (GLUE benchmark). We examine downscaling effects, extending scaling laws to models as small as ~1M parameters. At this scale, we observe a break of the power law for compute-optimal models and show that the MLM loss does not scale smoothly with compute-cost (FLOPs) below $2.2 \times 10^{15}$ FLOPs. We also find that adding layers does not always benefit downstream performance.
Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning
Mar 28, 2023
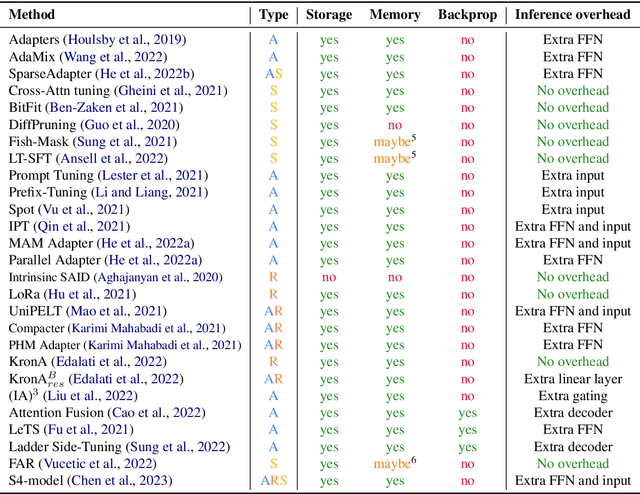

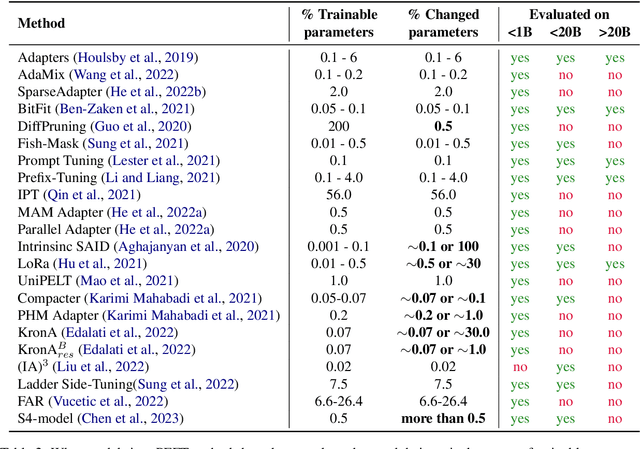
This paper presents a systematic overview and comparison of parameter-efficient fine-tuning methods covering over 40 papers published between February 2019 and February 2023. These methods aim to resolve the infeasibility and impracticality of fine-tuning large language models by only training a small set of parameters. We provide a taxonomy that covers a broad range of methods and present a detailed method comparison with a specific focus on real-life efficiency and fine-tuning multibillion-scale language models.