 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDENIAHL: In-Context Features Influence LLM Needle-In-A-Haystack Abilities
Nov 28, 2024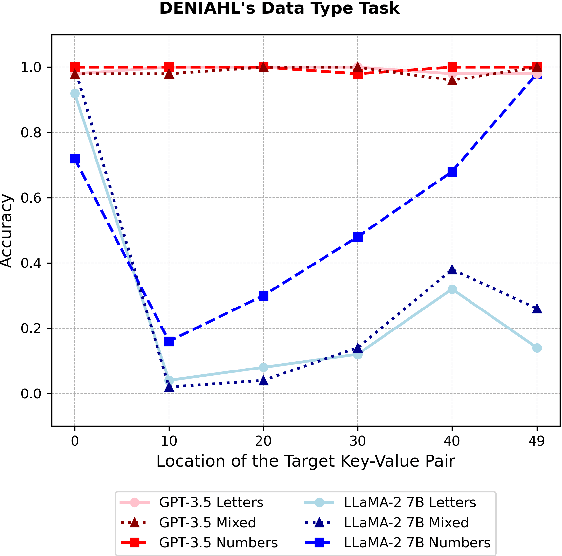

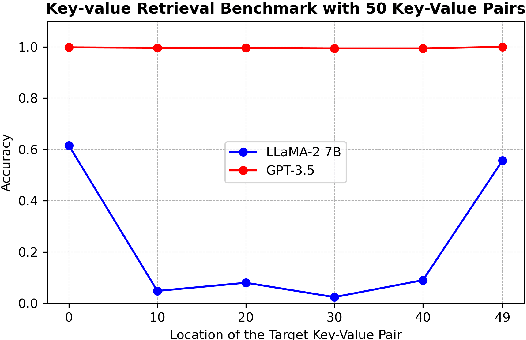

The Needle-in-a-haystack (NIAH) test is a general task used to assess language models' (LMs') abilities to recall particular information from long input context. This framework however does not provide a means of analyzing what factors, beyond context length, contribute to LMs' abilities or inabilities to separate and recall needles from their haystacks. To provide a systematic means of assessing what features contribute to LMs' NIAH capabilities, we developed a synthetic benchmark called DENIAHL (Data-oriented Evaluation of NIAH for LLM's). Our work expands on previous NIAH studies by ablating NIAH features beyond typical context length including data type, size, and patterns. We find stark differences between GPT-3.5 and LLaMA 2-7B's performance on DENIAHL, and drops in recall performance when features like item size are increased, and to some degree when data type is changed from numbers to letters. This has implications for increasingly large context models, demonstrating factors beyond item-number impact NIAH capabilities.
Honey, I Shrunk the Language: Language Model Behavior at Reduced Scale
May 30, 2023



In recent years, language models have drastically grown in size, and the abilities of these models have been shown to improve with scale. The majority of recent scaling laws studies focused on high-compute high-parameter count settings, leaving the question of when these abilities begin to emerge largely unanswered. In this paper, we investigate whether the effects of pre-training can be observed when the problem size is reduced, modeling a smaller, reduced-vocabulary language. We show the benefits of pre-training with masked language modeling (MLM) objective in models as small as 1.25M parameters, and establish a strong correlation between pre-training perplexity and downstream performance (GLUE benchmark). We examine downscaling effects, extending scaling laws to models as small as ~1M parameters. At this scale, we observe a break of the power law for compute-optimal models and show that the MLM loss does not scale smoothly with compute-cost (FLOPs) below $2.2 \times 10^{15}$ FLOPs. We also find that adding layers does not always benefit downstream performance.