 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning LLMs with Human Uncertainty: A Beta-Bernoulli Calibrator for LLM Forecasting
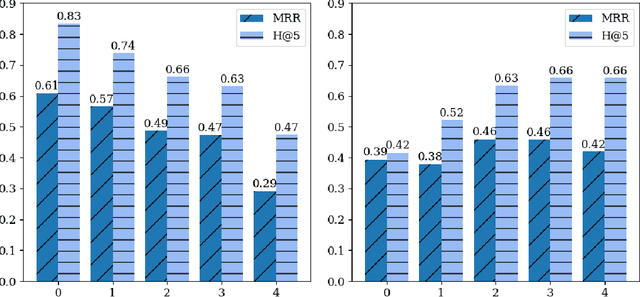
May 26, 2026Probabilistic forecasting estimates the likelihood of uncertain future events. To improve LLM forecasting, existing methods typically learn from binary outcomes to output verbalized forecasts. However, while aggregated human forecasts contain rich information in both the crowd probability estimate and the degree of agreement among forecasters, how to utilize these signals remains underexplored. To address this, we propose the Beta-Bernoulli Calibrator (BBC), which converts an initial point estimate forecast from any model into a distribution over event likelihood, using supervision from both binary outcomes and human forecasts. BBC models event likelihood $p \sim \text{Beta}(α, β)$ and outcome $y \sim \text{Bernoulli}(p)$, with the mean as the calibrated point forecast and the variance as the epistemic uncertainty. Our results show that BBC generally provides better calibrated and more accurate forecasts than both traditional post-hoc calibration methods and models fine-tuned specifically for forecasting, while remaining lightweight and having good generalization. We also show that the epistemic uncertainty captured by BBC is a more reliable predictor of forecasting error than verbalized confidence.
LeanCat: A Benchmark Suite for Formal Category Theory in Lean (Part I: 1-Categories)
Dec 31, 2025Large language models (LLMs) have made rapid progress in formal theorem proving, yet current benchmarks under-measure the kind of abstraction and library-mediated reasoning that organizes modern mathematics. In parallel with FATE's emphasis on frontier algebra, we introduce LeanCat, a Lean benchmark for category-theoretic formalization -- a unifying language for mathematical structure and a core layer of modern proof engineering -- serving as a stress test of structural, interface-level reasoning. Part I: 1-Categories contains 100 fully formalized statement-level tasks, curated into topic families and three difficulty tiers via an LLM-assisted + human grading process. The best model solves 8.25% of tasks at pass@1 (32.50%/4.17%/0.00% by Easy/Medium/High) and 12.00% at pass@4 (50.00%/4.76%/0.00%). We also evaluate LeanBridge which use LeanExplore to search Mathlib, and observe consistent gains over single-model baselines. LeanCat is intended as a compact, reusable checkpoint for tracking both AI and human progress toward reliable, research-level formalization in Lean.
DENIAHL: In-Context Features Influence LLM Needle-In-A-Haystack Abilities
Nov 28, 2024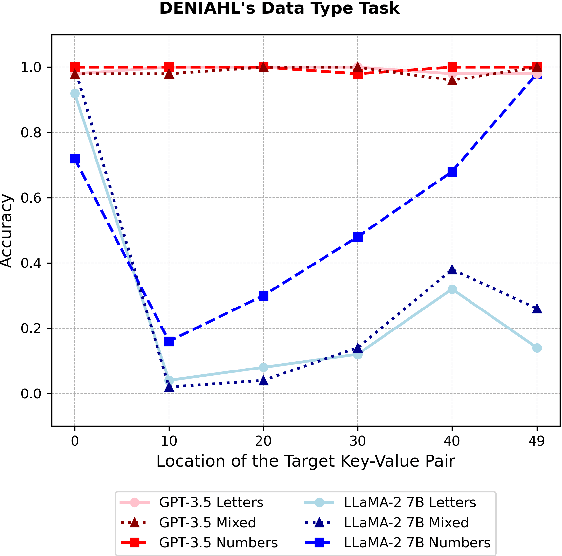

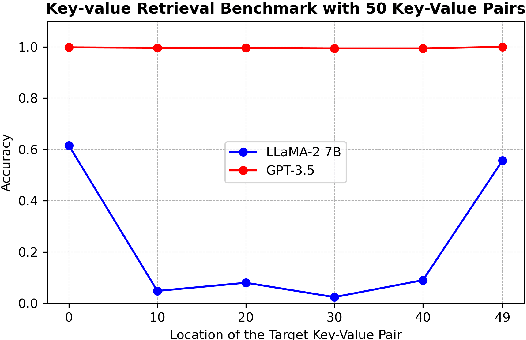

The Needle-in-a-haystack (NIAH) test is a general task used to assess language models' (LMs') abilities to recall particular information from long input context. This framework however does not provide a means of analyzing what factors, beyond context length, contribute to LMs' abilities or inabilities to separate and recall needles from their haystacks. To provide a systematic means of assessing what features contribute to LMs' NIAH capabilities, we developed a synthetic benchmark called DENIAHL (Data-oriented Evaluation of NIAH for LLM's). Our work expands on previous NIAH studies by ablating NIAH features beyond typical context length including data type, size, and patterns. We find stark differences between GPT-3.5 and LLaMA 2-7B's performance on DENIAHL, and drops in recall performance when features like item size are increased, and to some degree when data type is changed from numbers to letters. This has implications for increasingly large context models, demonstrating factors beyond item-number impact NIAH capabilities.
Are LLMs Prescient? A Continuous Evaluation using Daily News as the Oracle
Nov 13, 2024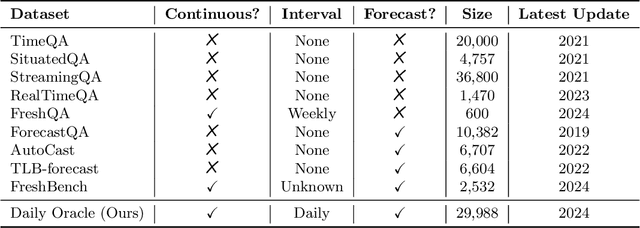
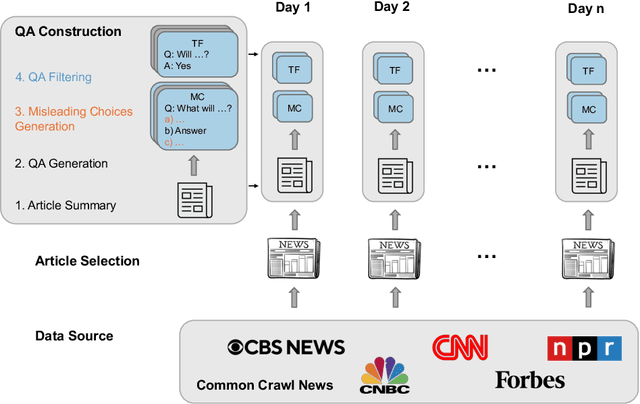
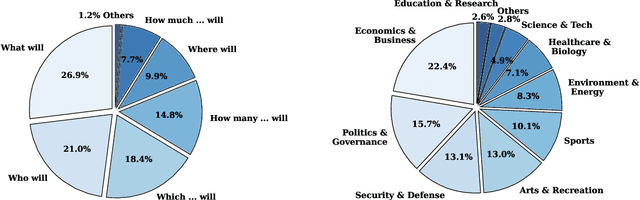
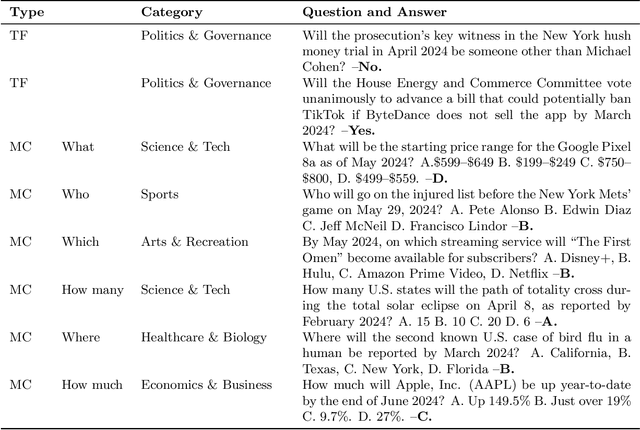
Many existing evaluation benchmarks for Large Language Models (LLMs) quickly become outdated due to the emergence of new models and training data. These benchmarks also fall short in assessing how LLM performance changes over time, as they consist of static questions without a temporal dimension. To address these limitations, we propose using future event prediction as a continuous evaluation method to assess LLMs' temporal generalization and forecasting abilities. Our benchmark, Daily Oracle, automatically generates question-answer (QA) pairs from daily news, challenging LLMs to predict "future" event outcomes. Our findings reveal that as pre-training data becomes outdated, LLM performance degrades over time. While Retrieval Augmented Generation (RAG) has the potential to enhance prediction accuracy, the performance degradation pattern persists, highlighting the need for continuous model updates.
CLIP: A Dataset for Extracting Action Items for Physicians from Hospital Discharge Notes
Jun 04, 2021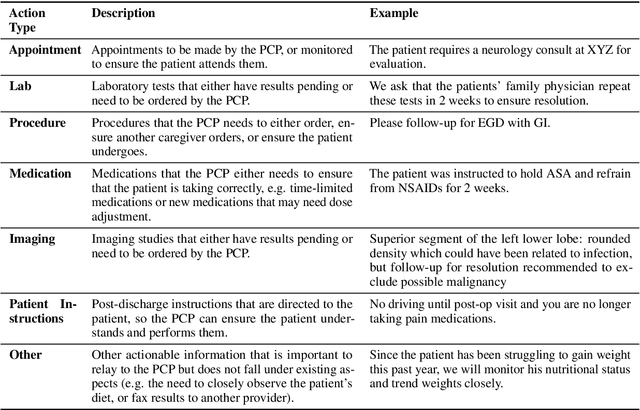
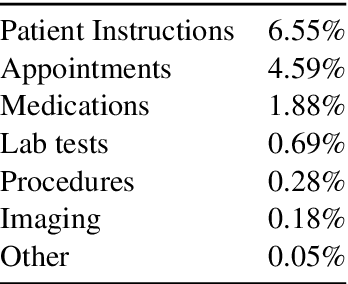
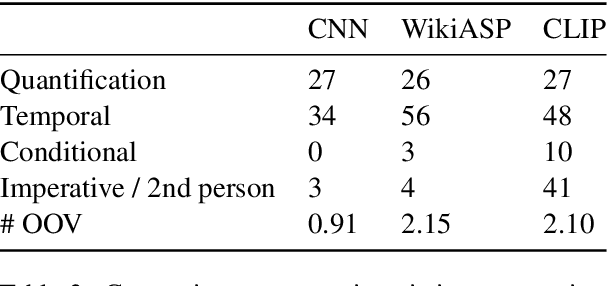
Continuity of care is crucial to ensuring positive health outcomes for patients discharged from an inpatient hospital setting, and improved information sharing can help. To share information, caregivers write discharge notes containing action items to share with patients and their future caregivers, but these action items are easily lost due to the lengthiness of the documents. In this work, we describe our creation of a dataset of clinical action items annotated over MIMIC-III, the largest publicly available dataset of real clinical notes. This dataset, which we call CLIP, is annotated by physicians and covers 718 documents representing 100K sentences. We describe the task of extracting the action items from these documents as multi-aspect extractive summarization, with each aspect representing a type of action to be taken. We evaluate several machine learning models on this task, and show that the best models exploit in-domain language model pre-training on 59K unannotated documents, and incorporate context from neighboring sentences. We also propose an approach to pre-training data selection that allows us to explore the trade-off between size and domain-specificity of pre-training datasets for this task.
Knowledge Base Completion for Constructing Problem-Oriented Medical Records
Apr 27, 2020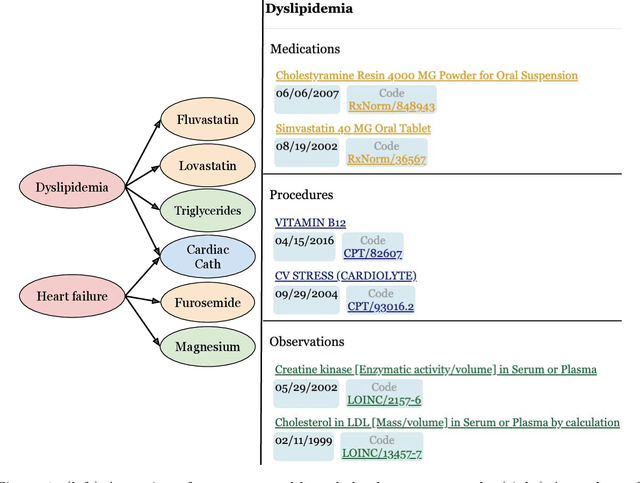

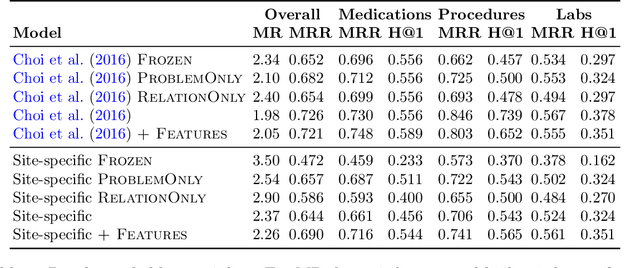
Both electronic health records and personal health records are typically organized by data type, with medical problems, medications, procedures, and laboratory results chronologically sorted in separate areas of the chart. As a result, it can be difficult to find all of the relevant information for answering a clinical question about a given medical problem. A promising alternative is to instead organize by problems, with related medications, procedures, and other pertinent information all grouped together. A recent effort by Buchanan (2017) manually defined, through expert consensus, 11 medical problems and the relevant labs and medications for each. We show how to use machine learning on electronic health records to instead automatically construct these problem-based groupings of relevant medications, procedures, and laboratory tests. We formulate the learning task as one of knowledge base completion, and annotate a dataset that expands the set of problems from 11 to 32. We develop a model architecture that exploits both pre-trained concept embeddings and usage data relating the concepts contained in a longitudinal dataset from a large health system. We evaluate our algorithms' ability to suggest relevant medications, procedures, and lab tests, and find that the approach provides feasible suggestions even for problems that are hidden during training.
Simple Recurrent Units for Highly Parallelizable Recurrence
Sep 07, 2018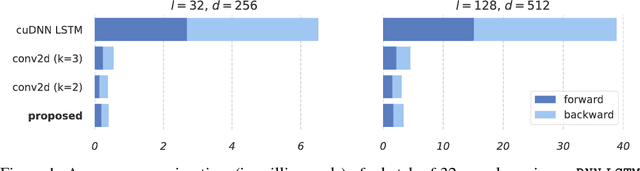


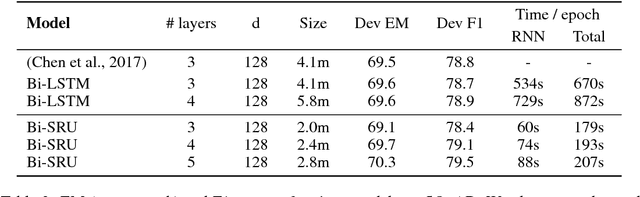
Common recurrent neural architectures scale poorly due to the intrinsic difficulty in parallelizing their state computations. In this work, we propose the Simple Recurrent Unit (SRU), a light recurrent unit that balances model capacity and scalability. SRU is designed to provide expressive recurrence, enable highly parallelized implementation, and comes with careful initialization to facilitate training of deep models. We demonstrate the effectiveness of SRU on multiple NLP tasks. SRU achieves 5--9x speed-up over cuDNN-optimized LSTM on classification and question answering datasets, and delivers stronger results than LSTM and convolutional models. We also obtain an average of 0.7 BLEU improvement over the Transformer model on translation by incorporating SRU into the architecture.