 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboSignature: Robust Signature and Watermarking on Network Attacks
Dec 22, 2024Generative models have enabled easy creation and generation of images of all kinds given a single prompt. However, this has also raised ethical concerns about what is an actual piece of content created by humans or cameras compared to model-generated content like images or videos. Watermarking data generated by modern generative models is a popular method to provide information on the source of the content. The goal is for all generated images to conceal an invisible watermark, allowing for future detection or identification. The Stable Signature finetunes the decoder of Latent Diffusion Models such that a unique watermark is rooted in any image produced by the decoder. In this paper, we present a novel adversarial fine-tuning attack that disrupts the model's ability to embed the intended watermark, exposing a significant vulnerability in existing watermarking methods. To address this, we further propose a tamper-resistant fine-tuning algorithm inspired by methods developed for large language models, tailored to the specific requirements of watermarking in LDMs. Our findings emphasize the importance of anticipating and defending against potential vulnerabilities in generative systems.
DENIAHL: In-Context Features Influence LLM Needle-In-A-Haystack Abilities
Nov 28, 2024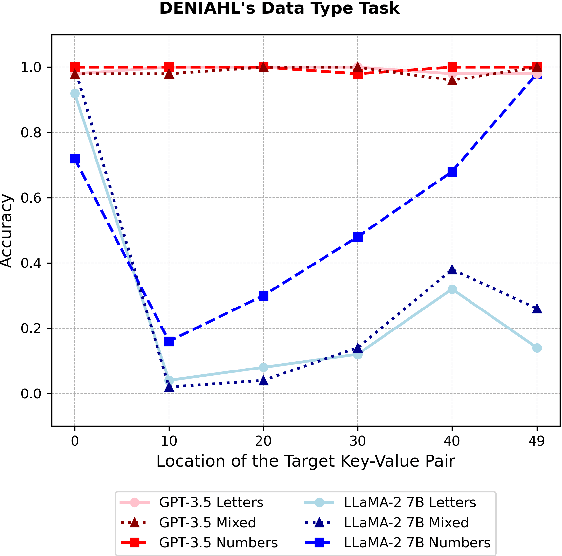

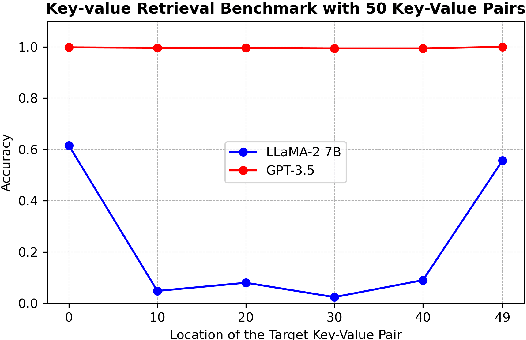

The Needle-in-a-haystack (NIAH) test is a general task used to assess language models' (LMs') abilities to recall particular information from long input context. This framework however does not provide a means of analyzing what factors, beyond context length, contribute to LMs' abilities or inabilities to separate and recall needles from their haystacks. To provide a systematic means of assessing what features contribute to LMs' NIAH capabilities, we developed a synthetic benchmark called DENIAHL (Data-oriented Evaluation of NIAH for LLM's). Our work expands on previous NIAH studies by ablating NIAH features beyond typical context length including data type, size, and patterns. We find stark differences between GPT-3.5 and LLaMA 2-7B's performance on DENIAHL, and drops in recall performance when features like item size are increased, and to some degree when data type is changed from numbers to letters. This has implications for increasingly large context models, demonstrating factors beyond item-number impact NIAH capabilities.