 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning Circuits: Few-shot Multihop Question Generation with Structured Rationales
Nov 15, 2022



Multi-hop Question Generation is the task of generating questions which require the reader to reason over and combine information spread across multiple passages using several reasoning steps. Chain-of-thought rationale generation has been shown to improve performance on multi-step reasoning tasks and make model predictions more interpretable. However, few-shot performance gains from including rationales have been largely observed only in +100B language models, and otherwise require large scale manual rationale annotation. In this work, we introduce a new framework for applying chain-of-thought inspired structured rationale generation to multi-hop question generation under a very low supervision regime (8- to 128-shot). We propose to annotate a small number of examples following our proposed multi-step rationale schema, treating each reasoning step as a separate task to be performed by a generative language model. We show that our framework leads to improved control over the difficulty of the generated questions and better performance compared to baselines trained without rationales, both on automatic evaluation metrics and in human evaluation. Importantly, we show that this is achievable with a modest model size.
Down and Across: Introducing Crossword-Solving as a New NLP Benchmark
May 20, 2022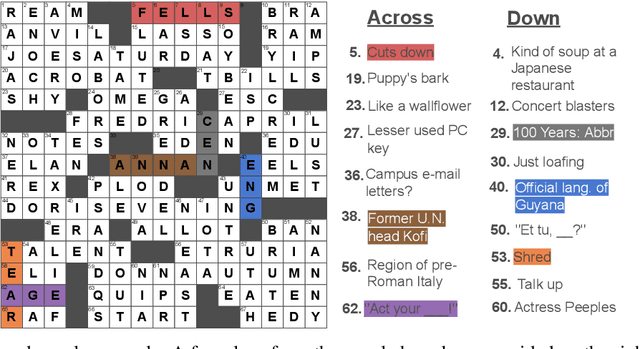
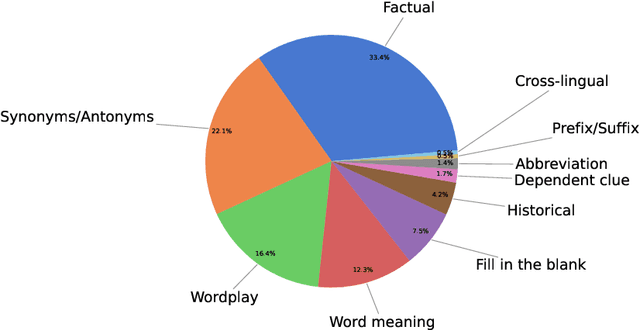

Solving crossword puzzles requires diverse reasoning capabilities, access to a vast amount of knowledge about language and the world, and the ability to satisfy the constraints imposed by the structure of the puzzle. In this work, we introduce solving crossword puzzles as a new natural language understanding task. We release the specification of a corpus of crossword puzzles collected from the New York Times daily crossword spanning 25 years and comprised of a total of around nine thousand puzzles. These puzzles include a diverse set of clues: historic, factual, word meaning, synonyms/antonyms, fill-in-the-blank, abbreviations, prefixes/suffixes, wordplay, and cross-lingual, as well as clues that depend on the answers to other clues. We separately release the clue-answer pairs from these puzzles as an open-domain question answering dataset containing over half a million unique clue-answer pairs. For the question answering task, our baselines include several sequence-to-sequence and retrieval-based generative models. We also introduce a non-parametric constraint satisfaction baseline for solving the entire crossword puzzle. Finally, we propose an evaluation framework which consists of several complementary performance metrics.
BERT Busters: Outlier Dimensions that Disrupt Transformers
Jun 02, 2021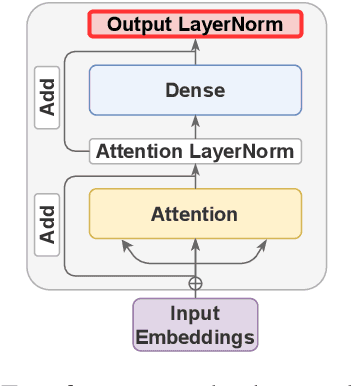

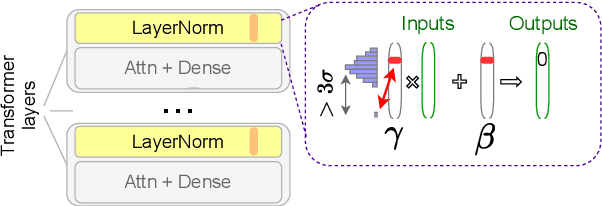
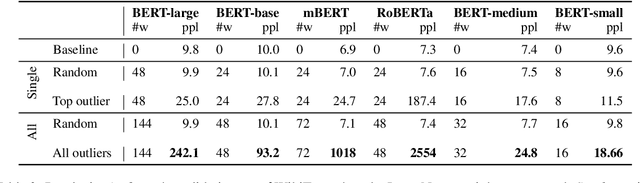
Multiple studies have shown that Transformers are remarkably robust to pruning. Contrary to this received wisdom, we demonstrate that pre-trained Transformer encoders are surprisingly fragile to the removal of a very small number of features in the layer outputs (<0.0001% of model weights). In case of BERT and other pre-trained encoder Transformers, the affected component is the scaling factors and biases in the LayerNorm. The outliers are high-magnitude normalization parameters that emerge early in pre-training and show up consistently in the same dimensional position throughout the model. We show that disabling them significantly degrades both the MLM loss and the downstream task performance. This effect is observed across several BERT-family models and other popular pre-trained Transformer architectures, including BART, XLNet and ELECTRA; we also show a similar effect in GPT-2.
Cross-lingual Alignment Methods for Multilingual BERT: A Comparative Study
Sep 29, 2020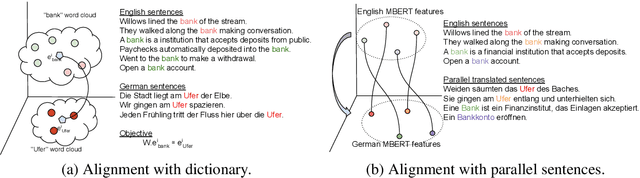


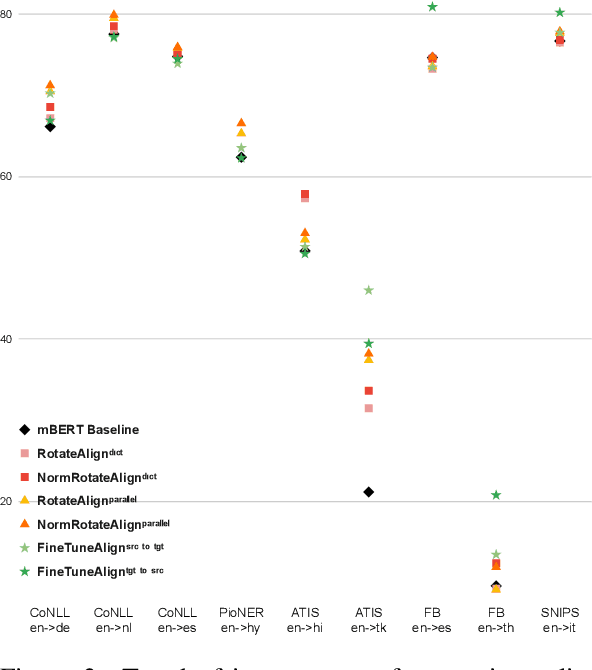
Multilingual BERT (mBERT) has shown reasonable capability for zero-shot cross-lingual transfer when fine-tuned on downstream tasks. Since mBERT is not pre-trained with explicit cross-lingual supervision, transfer performance can further be improved by aligning mBERT with cross-lingual signal. Prior work proposes several approaches to align contextualised embeddings. In this paper we analyse how different forms of cross-lingual supervision and various alignment methods influence the transfer capability of mBERT in zero-shot setting. Specifically, we compare parallel corpora vs. dictionary-based supervision and rotational vs. fine-tuning based alignment methods. We evaluate the performance of different alignment methodologies across eight languages on two tasks: Name Entity Recognition and Semantic Slot Filling. In addition, we propose a novel normalisation method which consistently improves the performance of rotation-based alignment including a notable 3% F1 improvement for distant and typologically dissimilar languages. Importantly we identify the biases of the alignment methods to the type of task and proximity to the transfer language. We also find that supervision from parallel corpus is generally superior to dictionary alignments.
CliNER 2.0: Accessible and Accurate Clinical Concept Extraction
Mar 06, 2018
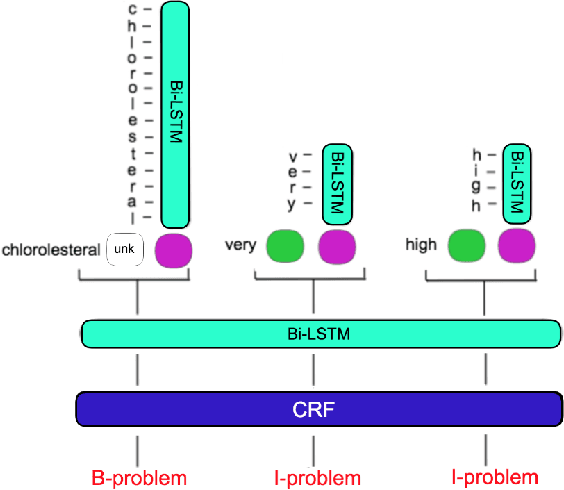

Clinical notes often describe important aspects of a patient's stay and are therefore critical to medical research. Clinical concept extraction (CCE) of named entities - such as problems, tests, and treatments - aids in forming an understanding of notes and provides a foundation for many downstream clinical decision-making tasks. Historically, this task has been posed as a standard named entity recognition (NER) sequence tagging problem, and solved with feature-based methods using handengineered domain knowledge. Recent advances, however, have demonstrated the efficacy of LSTM-based models for NER tasks, including CCE. This work presents CliNER 2.0, a simple-to-install, open-source tool for extracting concepts from clinical text. CliNER 2.0 uses a word- and character- level LSTM model, and achieves state-of-the-art performance. For ease of use, the tool also includes pre-trained models available for public use.