 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslation-Enhanced Multilingual Text-to-Image Generation
May 30, 2023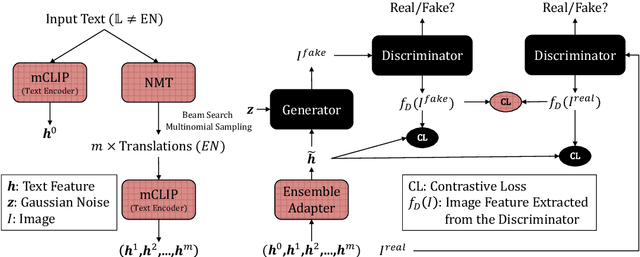
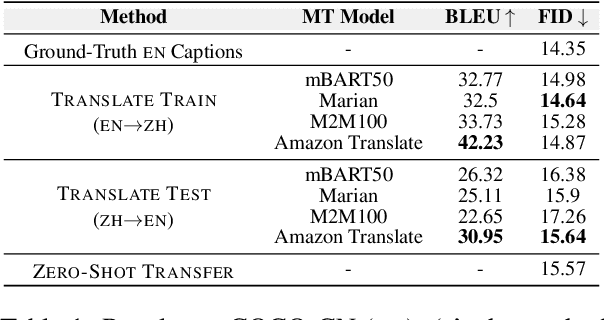
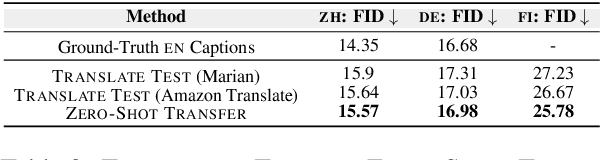

Research on text-to-image generation (TTI) still predominantly focuses on the English language due to the lack of annotated image-caption data in other languages; in the long run, this might widen inequitable access to TTI technology. In this work, we thus investigate multilingual TTI (termed mTTI) and the current potential of neural machine translation (NMT) to bootstrap mTTI systems. We provide two key contributions. 1) Relying on a multilingual multi-modal encoder, we provide a systematic empirical study of standard methods used in cross-lingual NLP when applied to mTTI: Translate Train, Translate Test, and Zero-Shot Transfer. 2) We propose Ensemble Adapter (EnsAd), a novel parameter-efficient approach that learns to weigh and consolidate the multilingual text knowledge within the mTTI framework, mitigating the language gap and thus improving mTTI performance. Our evaluations on standard mTTI datasets COCO-CN, Multi30K Task2, and LAION-5B demonstrate the potential of translation-enhanced mTTI systems and also validate the benefits of the proposed EnsAd which derives consistent gains across all datasets. Further investigations on model variants, ablation studies, and qualitative analyses provide additional insights on the inner workings of the proposed mTTI approaches.
Cross-lingual Alignment Methods for Multilingual BERT: A Comparative Study
Sep 29, 2020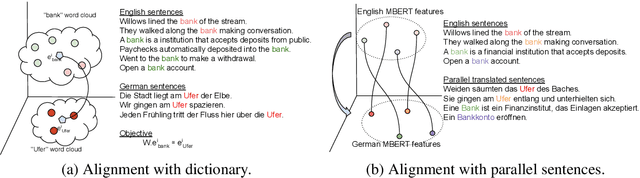


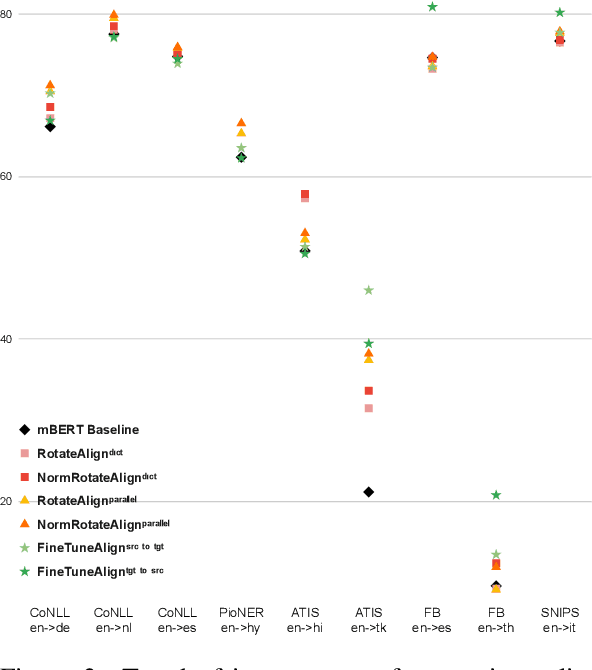
Multilingual BERT (mBERT) has shown reasonable capability for zero-shot cross-lingual transfer when fine-tuned on downstream tasks. Since mBERT is not pre-trained with explicit cross-lingual supervision, transfer performance can further be improved by aligning mBERT with cross-lingual signal. Prior work proposes several approaches to align contextualised embeddings. In this paper we analyse how different forms of cross-lingual supervision and various alignment methods influence the transfer capability of mBERT in zero-shot setting. Specifically, we compare parallel corpora vs. dictionary-based supervision and rotational vs. fine-tuning based alignment methods. We evaluate the performance of different alignment methodologies across eight languages on two tasks: Name Entity Recognition and Semantic Slot Filling. In addition, we propose a novel normalisation method which consistently improves the performance of rotation-based alignment including a notable 3% F1 improvement for distant and typologically dissimilar languages. Importantly we identify the biases of the alignment methods to the type of task and proximity to the transfer language. We also find that supervision from parallel corpus is generally superior to dictionary alignments.