 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic and Compressive Adaptation of Transformers From Images to Videos
Paper and Code
Aug 14, 2024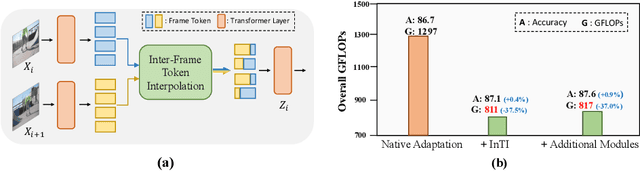
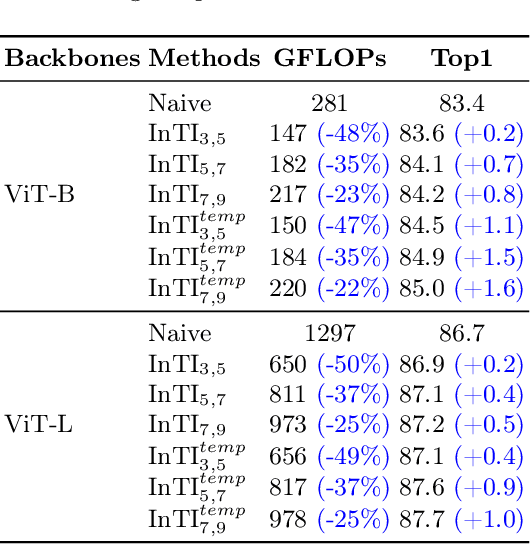
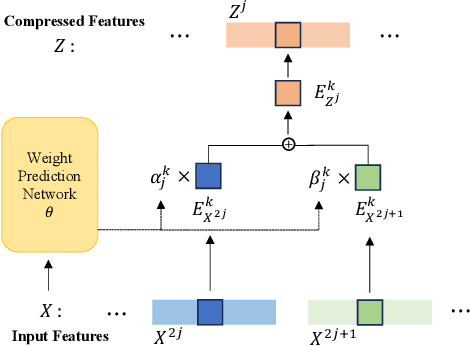
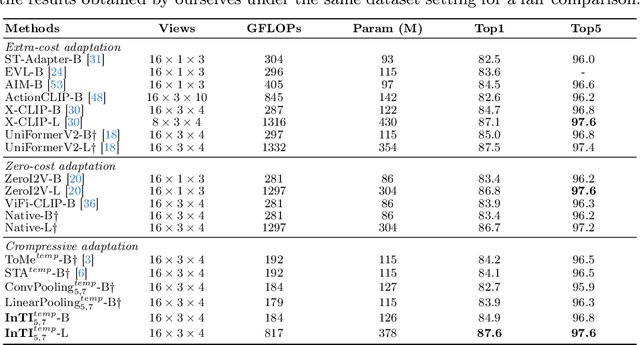
Recently, the remarkable success of pre-trained Vision Transformers (ViTs) from image-text matching has sparked an interest in image-to-video adaptation. However, most current approaches retain the full forward pass for each frame, leading to a high computation overhead for processing entire videos. In this paper, we present InTI, a novel approach for compressive image-to-video adaptation using dynamic Inter-frame Token Interpolation. InTI aims to softly preserve the informative tokens without disrupting their coherent spatiotemporal structure. Specifically, each token pair at identical positions within neighbor frames is linearly aggregated into a new token, where the aggregation weights are generated by a multi-scale context-aware network. In this way, the information of neighbor frames can be adaptively compressed in a point-by-point manner, thereby effectively reducing the number of processed frames by half each time. Importantly, InTI can be seamlessly integrated with existing adaptation methods, achieving strong performance without extra-complex design. On Kinetics-400, InTI reaches a top-1 accuracy of 87.1 with a remarkable 37.5% reduction in GFLOPs compared to naive adaptation. When combined with additional temporal modules, InTI achieves a top-1 accuracy of 87.6 with a 37% reduction in GFLOPs. Similar conclusions have been verified in other common datasets.