 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic and Compressive Adaptation of Transformers From Images to Videos
Aug 14, 2024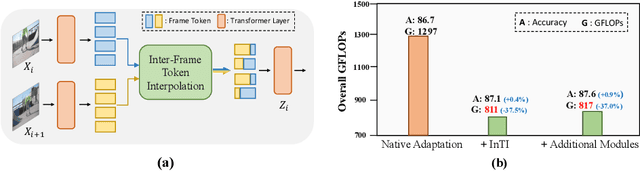
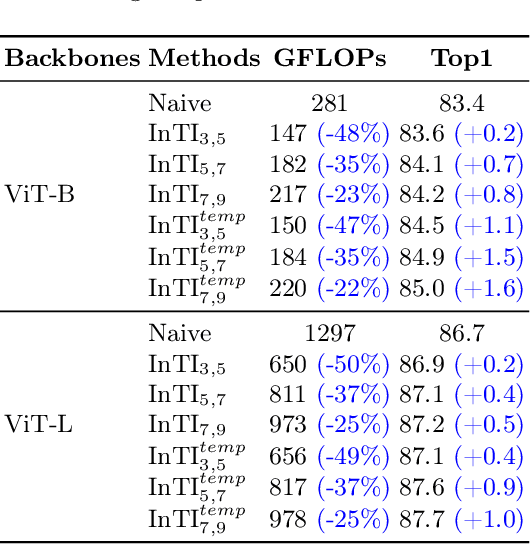
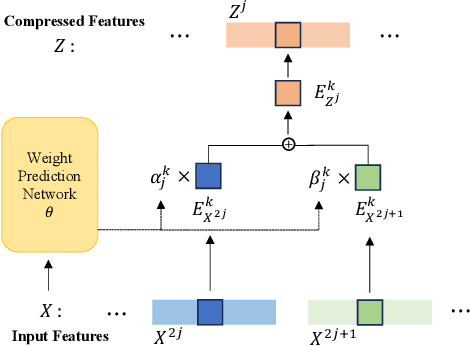
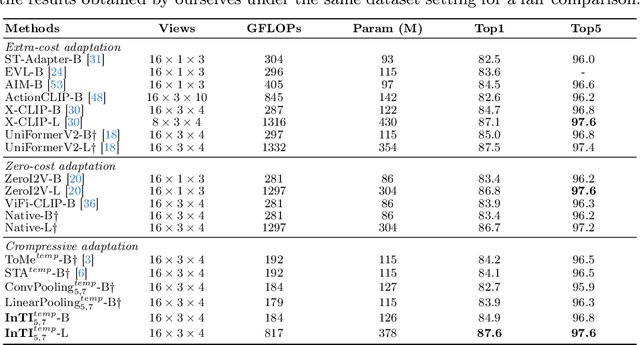
Recently, the remarkable success of pre-trained Vision Transformers (ViTs) from image-text matching has sparked an interest in image-to-video adaptation. However, most current approaches retain the full forward pass for each frame, leading to a high computation overhead for processing entire videos. In this paper, we present InTI, a novel approach for compressive image-to-video adaptation using dynamic Inter-frame Token Interpolation. InTI aims to softly preserve the informative tokens without disrupting their coherent spatiotemporal structure. Specifically, each token pair at identical positions within neighbor frames is linearly aggregated into a new token, where the aggregation weights are generated by a multi-scale context-aware network. In this way, the information of neighbor frames can be adaptively compressed in a point-by-point manner, thereby effectively reducing the number of processed frames by half each time. Importantly, InTI can be seamlessly integrated with existing adaptation methods, achieving strong performance without extra-complex design. On Kinetics-400, InTI reaches a top-1 accuracy of 87.1 with a remarkable 37.5% reduction in GFLOPs compared to naive adaptation. When combined with additional temporal modules, InTI achieves a top-1 accuracy of 87.6 with a 37% reduction in GFLOPs. Similar conclusions have been verified in other common datasets.
StableDrag: Stable Dragging for Point-based Image Editing
Mar 07, 2024



Point-based image editing has attracted remarkable attention since the emergence of DragGAN. Recently, DragDiffusion further pushes forward the generative quality via adapting this dragging technique to diffusion models. Despite these great success, this dragging scheme exhibits two major drawbacks, namely inaccurate point tracking and incomplete motion supervision, which may result in unsatisfactory dragging outcomes. To tackle these issues, we build a stable and precise drag-based editing framework, coined as StableDrag, by designing a discirminative point tracking method and a confidence-based latent enhancement strategy for motion supervision. The former allows us to precisely locate the updated handle points, thereby boosting the stability of long-range manipulation, while the latter is responsible for guaranteeing the optimized latent as high-quality as possible across all the manipulation steps. Thanks to these unique designs, we instantiate two types of image editing models including StableDrag-GAN and StableDrag-Diff, which attains more stable dragging performance, through extensive qualitative experiments and quantitative assessment on DragBench.
TS2-Net: Token Shift and Selection Transformer for Text-Video Retrieval
Jul 16, 2022
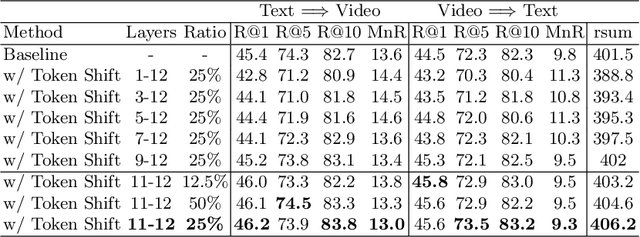
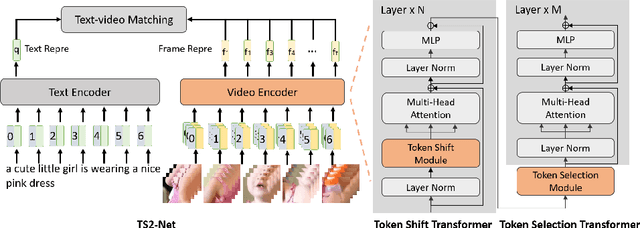
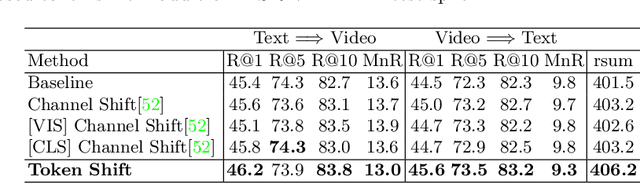
Text-Video retrieval is a task of great practical value and has received increasing attention, among which learning spatial-temporal video representation is one of the research hotspots. The video encoders in the state-of-the-art video retrieval models usually directly adopt the pre-trained vision backbones with the network structure fixed, they therefore can not be further improved to produce the fine-grained spatial-temporal video representation. In this paper, we propose Token Shift and Selection Network (TS2-Net), a novel token shift and selection transformer architecture, which dynamically adjusts the token sequence and selects informative tokens in both temporal and spatial dimensions from input video samples. The token shift module temporally shifts the whole token features back-and-forth across adjacent frames, to preserve the complete token representation and capture subtle movements. Then the token selection module selects tokens that contribute most to local spatial semantics. Based on thorough experiments, the proposed TS2-Net achieves state-of-the-art performance on major text-video retrieval benchmarks, including new records on MSRVTT, VATEX, LSMDC, ActivityNet, and DiDeMo.