 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlia: A Human-Inspired AI for Automated Systems Design and Optimization
Oct 31, 2025Can an AI autonomously design mechanisms for computer systems on par with the creativity and reasoning of human experts? We present Glia, an AI architecture for networked systems design that uses large language models (LLMs) in a human-inspired, multi-agent workflow. Each agent specializes in reasoning, experimentation, and analysis, collaborating through an evaluation framework that grounds abstract reasoning in empirical feedback. Unlike prior ML-for-systems methods that optimize black-box policies, Glia generates interpretable designs and exposes its reasoning process. When applied to a distributed GPU cluster for LLM inference, it produces new algorithms for request routing, scheduling, and auto-scaling that perform at human-expert levels in significantly less time, while yielding novel insights into workload behavior. Our results suggest that by combining reasoning LLMs with structured experimentation, an AI can produce creative and understandable designs for complex systems problems.
Concorde: Fast and Accurate CPU Performance Modeling with Compositional Analytical-ML Fusion
Mar 29, 2025Cycle-level simulators such as gem5 are widely used in microarchitecture design, but they are prohibitively slow for large-scale design space explorations. We present Concorde, a new methodology for learning fast and accurate performance models of microarchitectures. Unlike existing simulators and learning approaches that emulate each instruction, Concorde predicts the behavior of a program based on compact performance distributions that capture the impact of different microarchitectural components. It derives these performance distributions using simple analytical models that estimate bounds on performance induced by each microarchitectural component, providing a simple yet rich representation of a program's performance characteristics across a large space of microarchitectural parameters. Experiments show that Concorde is more than five orders of magnitude faster than a reference cycle-level simulator, with about 2% average Cycles-Per-Instruction (CPI) prediction error across a range of SPEC, open-source, and proprietary benchmarks. This enables rapid design-space exploration and performance sensitivity analyses that are currently infeasible, e.g., in about an hour, we conducted a first-of-its-kind fine-grained performance attribution to different microarchitectural components across a diverse set of programs, requiring nearly 150 million CPI evaluations.
m4: A Learned Flow-level Network Simulator
Mar 03, 2025



Flow-level simulation is widely used to model large-scale data center networks due to its scalability. Unlike packet-level simulators that model individual packets, flow-level simulators abstract traffic as continuous flows with dynamically assigned transmission rates. While this abstraction enables orders-of-magnitude speedup, it is inaccurate by omitting critical packet-level effects such as queuing, congestion control, and retransmissions. We present m4, an accurate and scalable flow-level simulator that uses machine learning to learn the dynamics of the network of interest. At the core of m4 lies a novel ML architecture that decomposes state transition computations into distinct spatial and temporal components, each represented by a suitable neural network. To efficiently learn the underlying flow-level dynamics, m4 adds dense supervision signals by predicting intermediate network metrics such as remaining flow size and queue length during training. m4 achieves a speedup of up to 104$\times$ over packet-level simulation. Relative to a traditional flow-level simulation, m4 reduces per-flow estimation errors by 45.3% (mean) and 53.0% (p90). For closed-loop applications, m4 accurately predicts network throughput under various congestion control schemes and workloads.
Direct Alignment with Heterogeneous Preferences
Feb 22, 2025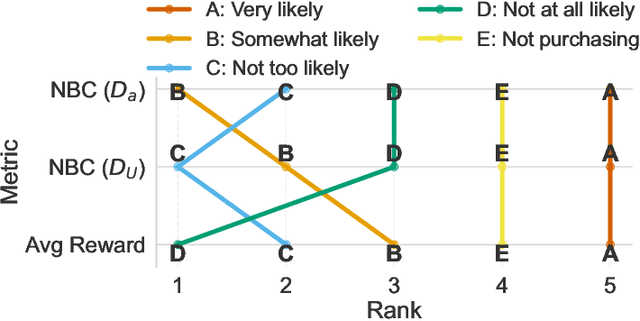

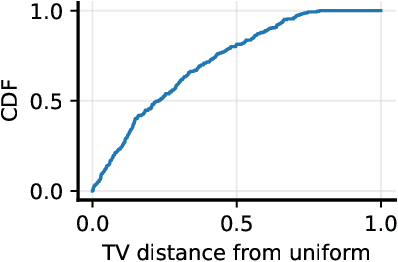
Alignment with human preferences is commonly framed using a universal reward function, even though human preferences are inherently heterogeneous. We formalize this heterogeneity by introducing user types and examine the limits of the homogeneity assumption. We show that aligning to heterogeneous preferences with a single policy is best achieved using the average reward across user types. However, this requires additional information about annotators. We examine improvements under different information settings, focusing on direct alignment methods. We find that minimal information can yield first-order improvements, while full feedback from each user type leads to consistent learning of the optimal policy. Surprisingly, however, no sample-efficient consistent direct loss exists in this latter setting. These results reveal a fundamental tension between consistency and sample efficiency in direct policy alignment.
Counterfactual Identifiability of Bijective Causal Models
Feb 04, 2023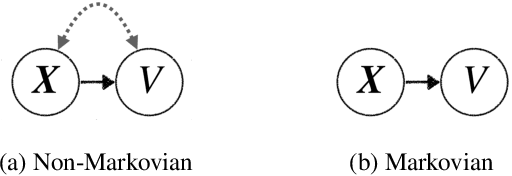

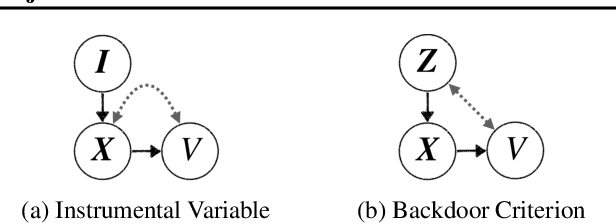

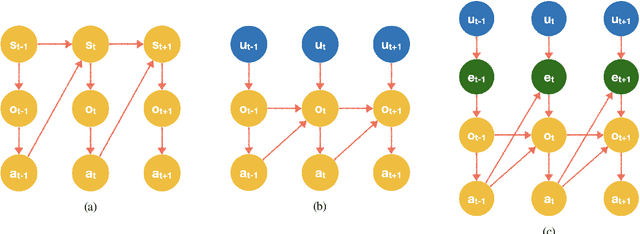
We study counterfactual identifiability in causal models with bijective generation mechanisms (BGM), a class that generalizes several widely-used causal models in the literature. We establish their counterfactual identifiability for three common causal structures with unobserved confounding, and propose a practical learning method that casts learning a BGM as structured generative modeling. Learned BGMs enable efficient counterfactual estimation and can be obtained using a variety of deep conditional generative models. We evaluate our techniques in a visual task and demonstrate its application in a real-world video streaming simulation task.
Locally Constrained Policy Optimization for Online Reinforcement Learning in Non-Stationary Input-Driven Environments
Feb 04, 2023



We study online Reinforcement Learning (RL) in non-stationary input-driven environments, where a time-varying exogenous input process affects the environment dynamics. Online RL is challenging in such environments due to catastrophic forgetting (CF). The agent tends to forget prior knowledge as it trains on new experiences. Prior approaches to mitigate this issue assume task labels (which are often not available in practice) or use off-policy methods that can suffer from instability and poor performance. We present Locally Constrained Policy Optimization (LCPO), an on-policy RL approach that combats CF by anchoring policy outputs on old experiences while optimizing the return on current experiences. To perform this anchoring, LCPO locally constrains policy optimization using samples from experiences that lie outside of the current input distribution. We evaluate LCPO in two gym and computer systems environments with a variety of synthetic and real input traces, and find that it outperforms state-of-the-art on-policy and off-policy RL methods in the online setting, while achieving results on-par with an offline agent pre-trained on the whole input trace.
Counterfactual (Non-)identifiability of Learned Structural Causal Models
Jan 22, 2023Recent advances in probabilistic generative modeling have motivated learning Structural Causal Models (SCM) from observational datasets using deep conditional generative models, also known as Deep Structural Causal Models (DSCM). If successful, DSCMs can be utilized for causal estimation tasks, e.g., for answering counterfactual queries. In this work, we warn practitioners about non-identifiability of counterfactual inference from observational data, even in the absence of unobserved confounding and assuming known causal structure. We prove counterfactual identifiability of monotonic generation mechanisms with single dimensional exogenous variables. For general generation mechanisms with multi-dimensional exogenous variables, we provide an impossibility result for counterfactual identifiability, motivating the need for parametric assumptions. As a practical approach, we propose a method for estimating worst-case errors of learned DSCMs' counterfactual predictions. The size of this error can be an essential metric for deciding whether or not DSCMs are a viable approach for counterfactual inference in a specific problem setting. In evaluation, our method confirms negligible counterfactual errors for an identifiable SCM from prior work, and also provides informative error bounds on counterfactual errors for a non-identifiable synthetic SCM.
CausalSim: Toward a Causal Data-Driven Simulator for Network Protocols
Jan 05, 2022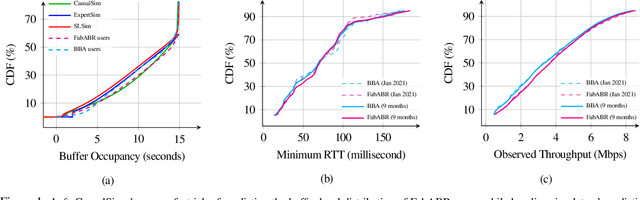
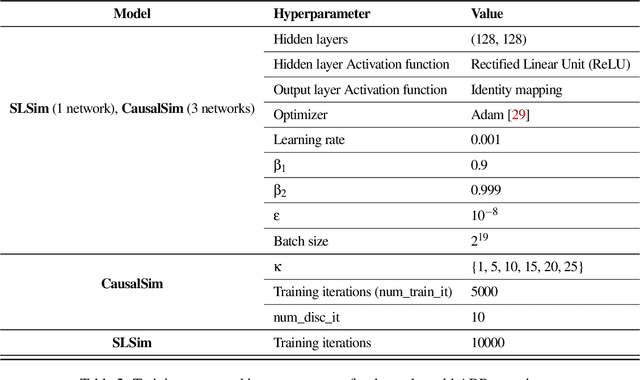
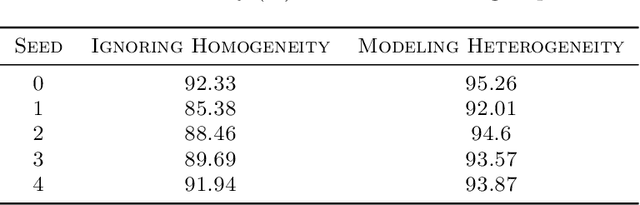
Evaluating the real-world performance of network protocols is challenging. Randomized control trials (RCT) are expensive and inaccessible to most researchers, while expert-designed simulators fail to capture complex behaviors in real networks. We present CausalSim, a data-driven simulator for network protocols that addresses this challenge. Learning network behavior from observational data is complicated due to the bias introduced by the protocols used during data collection. CausalSim uses traces from an initial RCT under a set of protocols to learn a causal network model, effectively removing the biases present in the data. Using this model, CausalSim can then simulate any protocol over the same traces (i.e., for counterfactual predictions). Key to CausalSim is the novel use of adversarial neural network training that exploits distributional invariances that are present due to the training data coming from an RCT. Our extensive evaluation of CausalSim on both real and synthetic datasets and two use cases, including more than nine months of real data from the Puffer video streaming system, shows that it provides accurate counterfactual predictions, reducing prediction error by 44% and 53% on average compared to expert-designed and standard supervised learning baselines.
Real-Time Video Inference on Edge Devices via Adaptive Model Streaming
Jun 11, 2020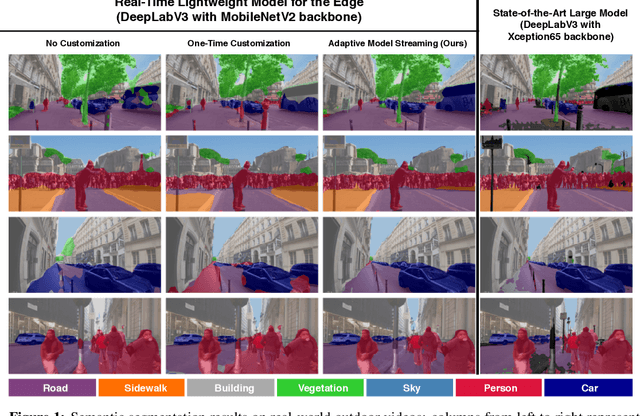

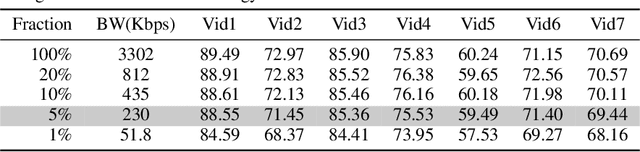
Real-time video inference on compute-limited edge devices like mobile phones and drones is challenging due to the high computation cost of Deep Neural Network models. In this paper we propose Adaptive Model Streaming (AMS), a cloud-assisted approach to real-time video inference on edge devices. The key idea in AMS is to use online learning to continually adapt a lightweight model running on an edge device to boost its performance on the video scenes in real-time. The model is trained in a cloud server and is periodically sent to the edge device. We discuss the challenges of online learning for video and present a practical design that takes into account the edge device, cloud server, and network bandwidth resource limitations. On the task of video semantic segmentation, our experimental results show 5.1--17.0 percent mean Intersection-over-Union improvement compared to a pre-trained model on several real-world videos. Our prototype can perform video segmentation at 30 frames-per-second with 40 milliseconds camera-to-label latency on a Samsung Galaxy S10+ mobile phone, using less than 400Kbps uplink and downlink bandwidth on the device.