 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlia: A Human-Inspired AI for Automated Systems Design and Optimization
Oct 31, 2025Can an AI autonomously design mechanisms for computer systems on par with the creativity and reasoning of human experts? We present Glia, an AI architecture for networked systems design that uses large language models (LLMs) in a human-inspired, multi-agent workflow. Each agent specializes in reasoning, experimentation, and analysis, collaborating through an evaluation framework that grounds abstract reasoning in empirical feedback. Unlike prior ML-for-systems methods that optimize black-box policies, Glia generates interpretable designs and exposes its reasoning process. When applied to a distributed GPU cluster for LLM inference, it produces new algorithms for request routing, scheduling, and auto-scaling that perform at human-expert levels in significantly less time, while yielding novel insights into workload behavior. Our results suggest that by combining reasoning LLMs with structured experimentation, an AI can produce creative and understandable designs for complex systems problems.
Glinthawk: A Two-Tiered Architecture for High-Throughput LLM Inference
Jan 20, 2025



Large Language Models (LLM) have revolutionized natural language processing, but their inference demands substantial resources, while under-utilizing high-end accelerators like GPUs. A major bottleneck arises from the attention mechanism, which requires storing large key-value caches, limiting the maximum achievable throughput way below the available computing resources. Current approaches attempt to mitigate this issue through memory-efficient attention and paging mechanisms, but remained constrained by the assumption that all operations must be performed on high-end accelerators. In this work, we propose Glinthawk, a two-tiered architecture that decouples the attention mechanism from the rest of the Transformer model. This approach allows the memory requirements for attention to scale independently, enabling larger batch sizes and more efficient use of the high-end accelerators. We prototype Glinthawk with NVIDIA T4 GPUs as one tier and standard CPU VMs as the other. Compared to a traditional single-tier setup, it improves throughput by $5.9\times$ and reduces cost of generation by $2.8\times$. For longer sequence lengths, it achieves $16.3\times$ throughput improvement at $2.4\times$ less cost. Our evaluation shows that this architecture can tolerate moderate network latency with minimal performance degradation, making it highly effective for latency-tolerant, throughput-oriented applications such as batch processing. We shared our prototype publicly at \url{https://github.com/microsoft/glinthawk}.
Locally Constrained Policy Optimization for Online Reinforcement Learning in Non-Stationary Input-Driven Environments
Feb 04, 2023



We study online Reinforcement Learning (RL) in non-stationary input-driven environments, where a time-varying exogenous input process affects the environment dynamics. Online RL is challenging in such environments due to catastrophic forgetting (CF). The agent tends to forget prior knowledge as it trains on new experiences. Prior approaches to mitigate this issue assume task labels (which are often not available in practice) or use off-policy methods that can suffer from instability and poor performance. We present Locally Constrained Policy Optimization (LCPO), an on-policy RL approach that combats CF by anchoring policy outputs on old experiences while optimizing the return on current experiences. To perform this anchoring, LCPO locally constrains policy optimization using samples from experiences that lie outside of the current input distribution. We evaluate LCPO in two gym and computer systems environments with a variety of synthetic and real input traces, and find that it outperforms state-of-the-art on-policy and off-policy RL methods in the online setting, while achieving results on-par with an offline agent pre-trained on the whole input trace.
Reinforcement Learning in Time-Varying Systems: an Empirical Study
Jan 14, 2022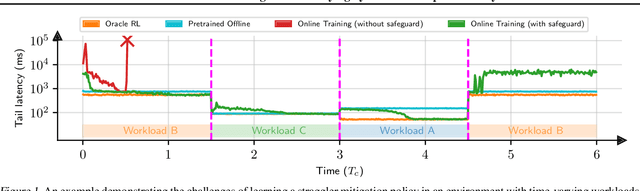

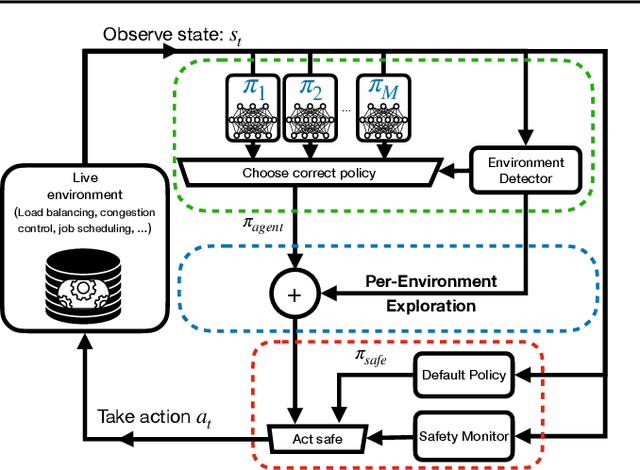
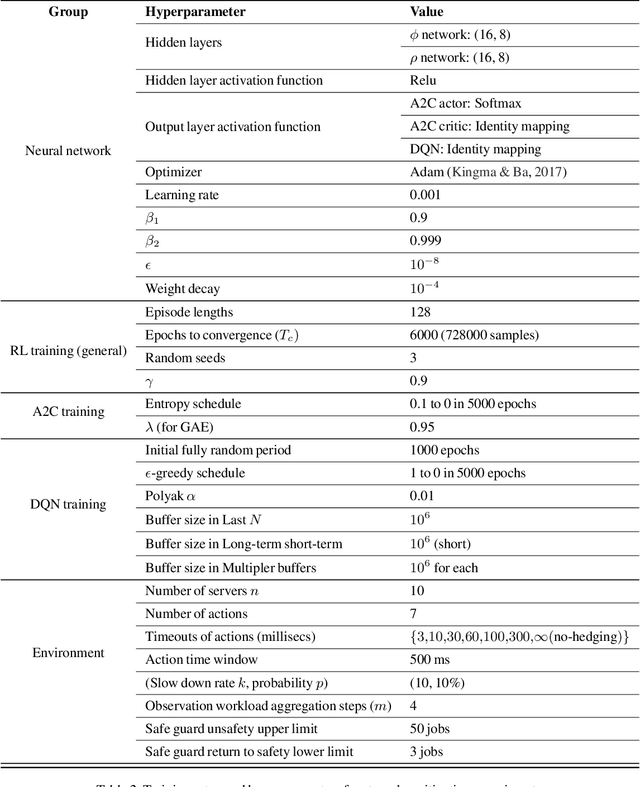
Recent research has turned to Reinforcement Learning (RL) to solve challenging decision problems, as an alternative to hand-tuned heuristics. RL can learn good policies without the need for modeling the environment's dynamics. Despite this promise, RL remains an impractical solution for many real-world systems problems. A particularly challenging case occurs when the environment changes over time, i.e. it exhibits non-stationarity. In this work, we characterize the challenges introduced by non-stationarity and develop a framework for addressing them to train RL agents in live systems. Such agents must explore and learn new environments, without hurting the system's performance, and remember them over time. To this end, our framework (1) identifies different environments encountered by the live system, (2) explores and trains a separate expert policy for each environment, and (3) employs safeguards to protect the system's performance. We apply our framework to two systems problems: straggler mitigation and adaptive video streaming, and evaluate it against a variety of alternative approaches using real-world and synthetic data. We show that each component of our framework is necessary to cope with non-stationarity.
CausalSim: Toward a Causal Data-Driven Simulator for Network Protocols
Jan 05, 2022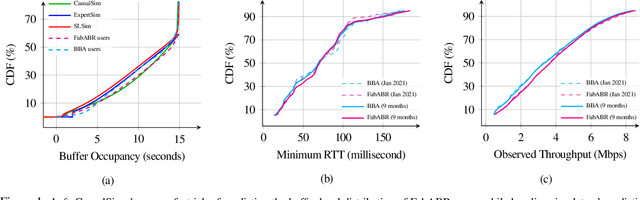
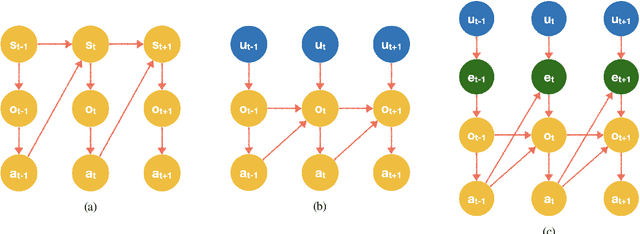
Evaluating the real-world performance of network protocols is challenging. Randomized control trials (RCT) are expensive and inaccessible to most researchers, while expert-designed simulators fail to capture complex behaviors in real networks. We present CausalSim, a data-driven simulator for network protocols that addresses this challenge. Learning network behavior from observational data is complicated due to the bias introduced by the protocols used during data collection. CausalSim uses traces from an initial RCT under a set of protocols to learn a causal network model, effectively removing the biases present in the data. Using this model, CausalSim can then simulate any protocol over the same traces (i.e., for counterfactual predictions). Key to CausalSim is the novel use of adversarial neural network training that exploits distributional invariances that are present due to the training data coming from an RCT. Our extensive evaluation of CausalSim on both real and synthetic datasets and two use cases, including more than nine months of real data from the Puffer video streaming system, shows that it provides accurate counterfactual predictions, reducing prediction error by 44% and 53% on average compared to expert-designed and standard supervised learning baselines.
Real-Time Video Inference on Edge Devices via Adaptive Model Streaming
Jun 11, 2020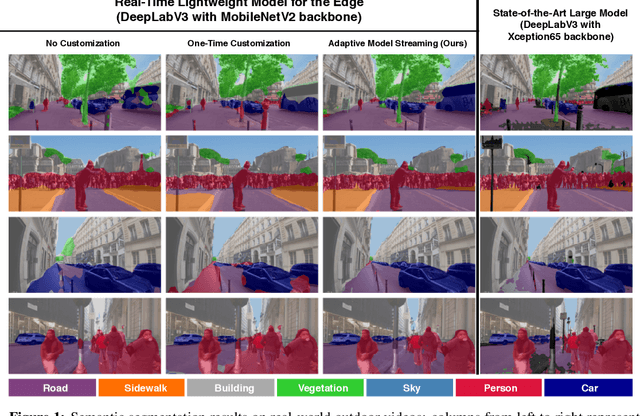

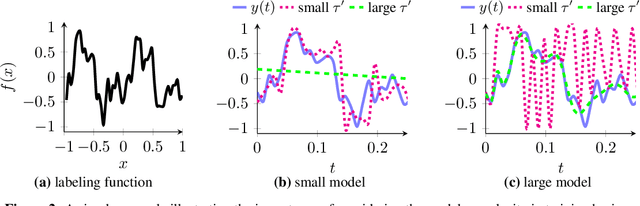
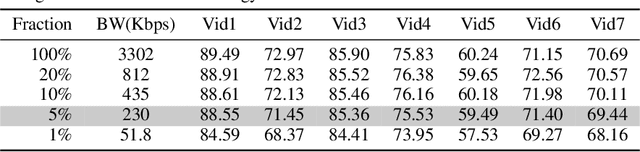
Real-time video inference on compute-limited edge devices like mobile phones and drones is challenging due to the high computation cost of Deep Neural Network models. In this paper we propose Adaptive Model Streaming (AMS), a cloud-assisted approach to real-time video inference on edge devices. The key idea in AMS is to use online learning to continually adapt a lightweight model running on an edge device to boost its performance on the video scenes in real-time. The model is trained in a cloud server and is periodically sent to the edge device. We discuss the challenges of online learning for video and present a practical design that takes into account the edge device, cloud server, and network bandwidth resource limitations. On the task of video semantic segmentation, our experimental results show 5.1--17.0 percent mean Intersection-over-Union improvement compared to a pre-trained model on several real-world videos. Our prototype can perform video segmentation at 30 frames-per-second with 40 milliseconds camera-to-label latency on a Samsung Galaxy S10+ mobile phone, using less than 400Kbps uplink and downlink bandwidth on the device.