 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning in Time-Varying Systems: an Empirical Study
Paper and Code
Jan 14, 2022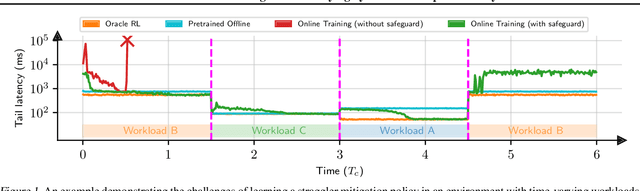

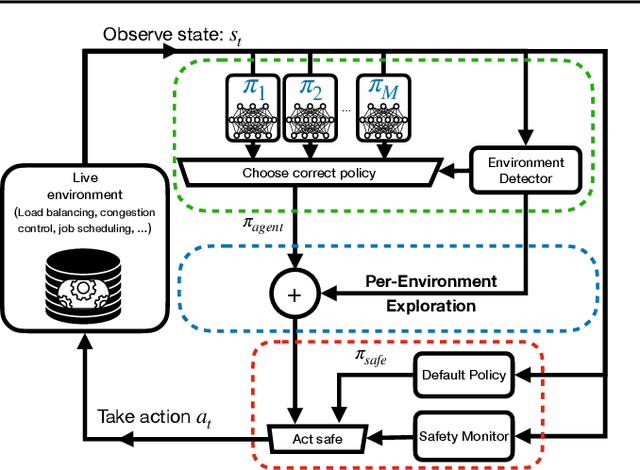
Recent research has turned to Reinforcement Learning (RL) to solve challenging decision problems, as an alternative to hand-tuned heuristics. RL can learn good policies without the need for modeling the environment's dynamics. Despite this promise, RL remains an impractical solution for many real-world systems problems. A particularly challenging case occurs when the environment changes over time, i.e. it exhibits non-stationarity. In this work, we characterize the challenges introduced by non-stationarity and develop a framework for addressing them to train RL agents in live systems. Such agents must explore and learn new environments, without hurting the system's performance, and remember them over time. To this end, our framework (1) identifies different environments encountered by the live system, (2) explores and trains a separate expert policy for each environment, and (3) employs safeguards to protect the system's performance. We apply our framework to two systems problems: straggler mitigation and adaptive video streaming, and evaluate it against a variety of alternative approaches using real-world and synthetic data. We show that each component of our framework is necessary to cope with non-stationarity.