 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemino: Practical and Robust Neural Compression for Video Conferencing
Sep 22, 2022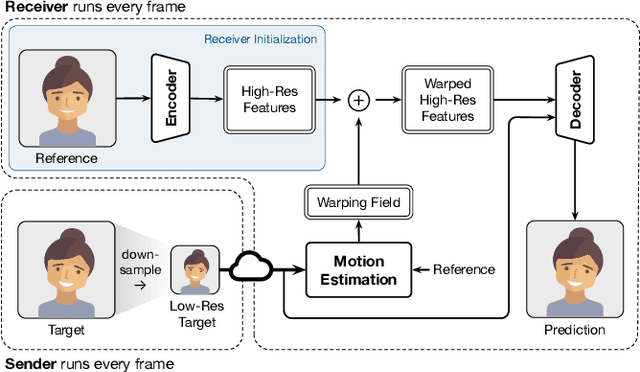
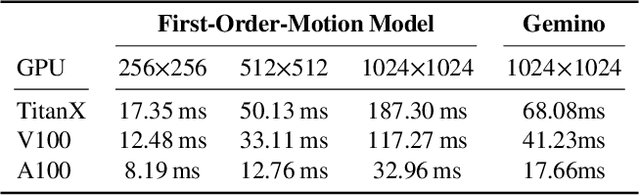


Video conferencing systems suffer from poor user experience when network conditions deteriorate because current video codecs simply cannot operate at extremely low bitrates. Recently, several neural alternatives have been proposed that reconstruct talking head videos at very low bitrates using sparse representations of each frame such as facial landmark information. However, these approaches produce poor reconstructions in scenarios with major movement or occlusions over the course of a call, and do not scale to higher resolutions. We design Gemino, a new neural compression system for video conferencing based on a novel high-frequency-conditional super-resolution pipeline. Gemino upsamples a very low-resolution version of each target frame while enhancing high-frequency details (e.g., skin texture, hair, etc.) based on information extracted from a single high-resolution reference image. We use a multi-scale architecture that runs different components of the model at different resolutions, allowing it to scale to resolutions comparable to 720p, and we personalize the model to learn specific details of each person, achieving much better fidelity at low bitrates. We implement Gemino atop aiortc, an open-source Python implementation of WebRTC, and show that it operates on 1024x1024 videos in real-time on a A100 GPU, and achieves 2.9x lower bitrate than traditional video codecs for the same perceptual quality.
Efficient Video Compression via Content-Adaptive Super-Resolution
Apr 06, 2021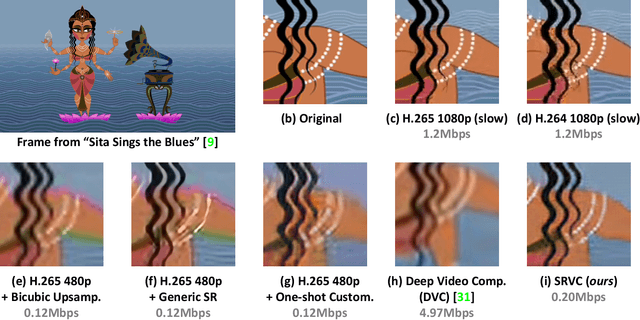
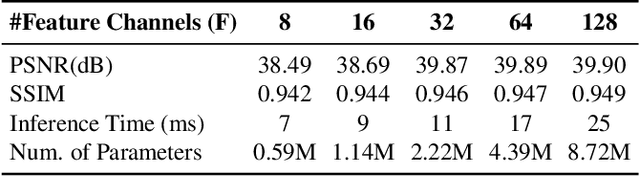
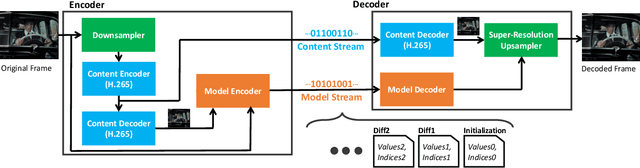
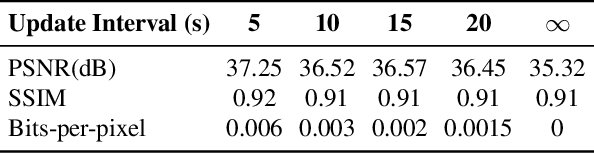
Video compression is a critical component of Internet video delivery. Recent work has shown that deep learning techniques can rival or outperform human-designed algorithms, but these methods are significantly less compute and power-efficient than existing codecs. This paper presents a new approach that augments existing codecs with a small, content-adaptive super-resolution model that significantly boosts video quality. Our method, SRVC, encodes video into two bitstreams: (i) a content stream, produced by compressing downsampled low-resolution video with the existing codec, (ii) a model stream, which encodes periodic updates to a lightweight super-resolution neural network customized for short segments of the video. SRVC decodes the video by passing the decompressed low-resolution video frames through the (time-varying) super-resolution model to reconstruct high-resolution video frames. Our results show that to achieve the same PSNR, SRVC requires 16% of the bits-per-pixel of H.265 in slow mode, and 2% of the bits-per-pixel of DVC, a recent deep learning-based video compression scheme. SRVC runs at 90 frames per second on a NVIDIA V100 GPU.
Real-Time Video Inference on Edge Devices via Adaptive Model Streaming
Jun 11, 2020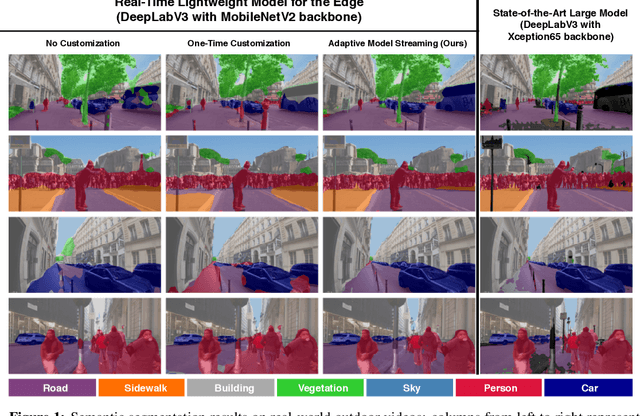

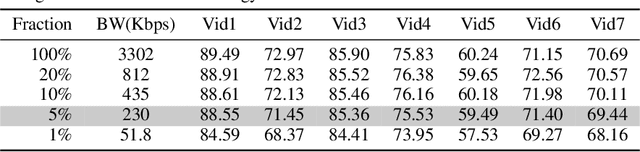
Real-time video inference on compute-limited edge devices like mobile phones and drones is challenging due to the high computation cost of Deep Neural Network models. In this paper we propose Adaptive Model Streaming (AMS), a cloud-assisted approach to real-time video inference on edge devices. The key idea in AMS is to use online learning to continually adapt a lightweight model running on an edge device to boost its performance on the video scenes in real-time. The model is trained in a cloud server and is periodically sent to the edge device. We discuss the challenges of online learning for video and present a practical design that takes into account the edge device, cloud server, and network bandwidth resource limitations. On the task of video semantic segmentation, our experimental results show 5.1--17.0 percent mean Intersection-over-Union improvement compared to a pre-trained model on several real-world videos. Our prototype can perform video segmentation at 30 frames-per-second with 40 milliseconds camera-to-label latency on a Samsung Galaxy S10+ mobile phone, using less than 400Kbps uplink and downlink bandwidth on the device.
Adaptive Neural Signal Detection for Massive MIMO
Jun 11, 2019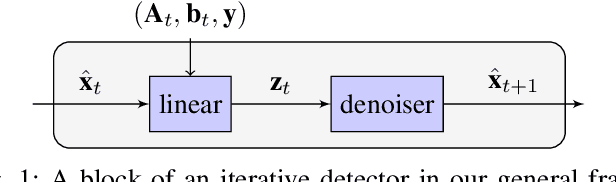
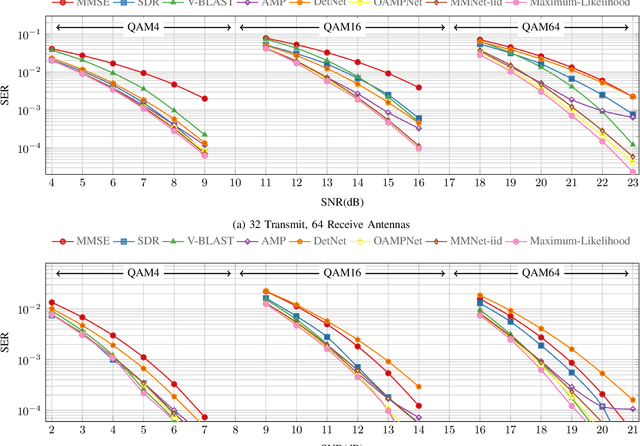
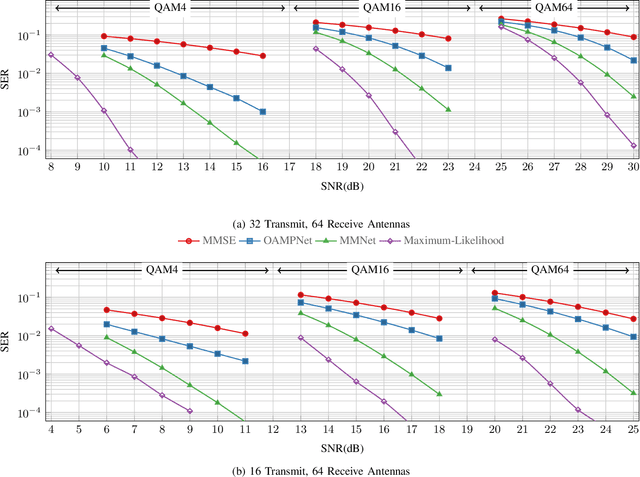
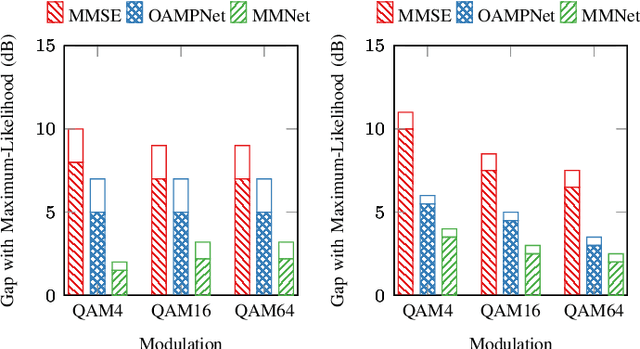
Symbol detection for Massive Multiple-Input Multiple-Output (MIMO) is a challenging problem for which traditional algorithms are either impractical or suffer from performance limitations. Several recently proposed learning-based approaches achieve promising results on simple channel models (e.g., i.i.d. Gaussian). However, their performance degrades significantly on real-world channels with spatial correlation. We propose MMNet, a deep learning MIMO detection scheme that significantly outperforms existing approaches on realistic channels with the same or lower computational complexity. MMNet's design builds on the theory of iterative soft-thresholding algorithms and uses a novel training algorithm that leverages temporal and spectral correlation to accelerate training. Together, these innovations allow MMNet to train online for every realization of the channel. On i.i.d. Gaussian channels, MMNet requires two orders of magnitude fewer operations than existing deep learning schemes but achieves near-optimal performance. On spatially-correlated channels, it achieves the same error rate as the next-best learning scheme (OAMPNet) at 2.5dB lower SNR and with at least 10x less computational complexity. MMNet is also 4--8dB better overall than a classic linear scheme like the minimum mean square error (MMSE) detector.