 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplat and Replace: 3D Reconstruction with Repetitive Elements
Jun 06, 2025We leverage repetitive elements in 3D scenes to improve novel view synthesis. Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) have greatly improved novel view synthesis but renderings of unseen and occluded parts remain low-quality if the training views are not exhaustive enough. Our key observation is that our environment is often full of repetitive elements. We propose to leverage those repetitions to improve the reconstruction of low-quality parts of the scene due to poor coverage and occlusions. We propose a method that segments each repeated instance in a 3DGS reconstruction, registers them together, and allows information to be shared among instances. Our method improves the geometry while also accounting for appearance variations across instances. We demonstrate our method on a variety of synthetic and real scenes with typical repetitive elements, leading to a substantial improvement in the quality of novel view synthesis.
Diffusion with Forward Models: Solving Stochastic Inverse Problems Without Direct Supervision
Jun 20, 2023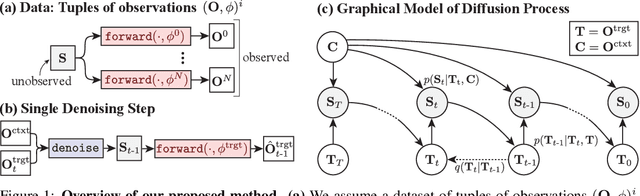


Denoising diffusion models are a powerful type of generative models used to capture complex distributions of real-world signals. However, their applicability is limited to scenarios where training samples are readily available, which is not always the case in real-world applications. For example, in inverse graphics, the goal is to generate samples from a distribution of 3D scenes that align with a given image, but ground-truth 3D scenes are unavailable and only 2D images are accessible. To address this limitation, we propose a novel class of denoising diffusion probabilistic models that learn to sample from distributions of signals that are never directly observed. Instead, these signals are measured indirectly through a known differentiable forward model, which produces partial observations of the unknown signal. Our approach involves integrating the forward model directly into the denoising process. This integration effectively connects the generative modeling of observations with the generative modeling of the underlying signals, allowing for end-to-end training of a conditional generative model over signals. During inference, our approach enables sampling from the distribution of underlying signals that are consistent with a given partial observation. We demonstrate the effectiveness of our method on three challenging computer vision tasks. For instance, in the context of inverse graphics, our model enables direct sampling from the distribution of 3D scenes that align with a single 2D input image.
FastComposer: Tuning-Free Multi-Subject Image Generation with Localized Attention
May 21, 2023
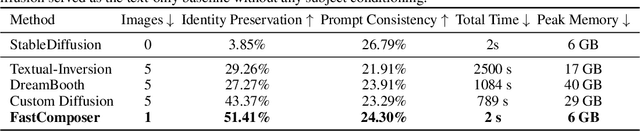


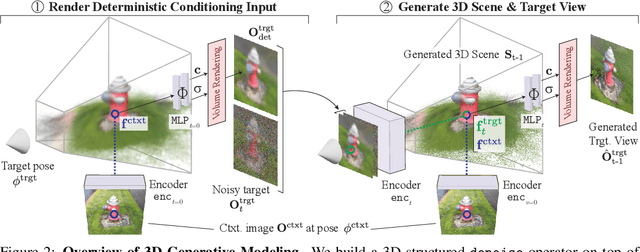
Diffusion models excel at text-to-image generation, especially in subject-driven generation for personalized images. However, existing methods are inefficient due to the subject-specific fine-tuning, which is computationally intensive and hampers efficient deployment. Moreover, existing methods struggle with multi-subject generation as they often blend features among subjects. We present FastComposer which enables efficient, personalized, multi-subject text-to-image generation without fine-tuning. FastComposer uses subject embeddings extracted by an image encoder to augment the generic text conditioning in diffusion models, enabling personalized image generation based on subject images and textual instructions with only forward passes. To address the identity blending problem in the multi-subject generation, FastComposer proposes cross-attention localization supervision during training, enforcing the attention of reference subjects localized to the correct regions in the target images. Naively conditioning on subject embeddings results in subject overfitting. FastComposer proposes delayed subject conditioning in the denoising step to maintain both identity and editability in subject-driven image generation. FastComposer generates images of multiple unseen individuals with different styles, actions, and contexts. It achieves 300$\times$-2500$\times$ speedup compared to fine-tuning-based methods and requires zero extra storage for new subjects. FastComposer paves the way for efficient, personalized, and high-quality multi-subject image creation. Code, model, and dataset are available at https://github.com/mit-han-lab/fastcomposer.
Can Shadows Reveal Biometric Information?
Oct 04, 2022
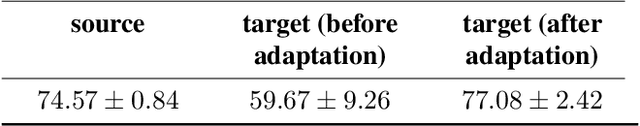


We study the problem of extracting biometric information of individuals by looking at shadows of objects cast on diffuse surfaces. We show that the biometric information leakage from shadows can be sufficient for reliable identity inference under representative scenarios via a maximum likelihood analysis. We then develop a learning-based method that demonstrates this phenomenon in real settings, exploiting the subtle cues in the shadows that are the source of the leakage without requiring any labeled real data. In particular, our approach relies on building synthetic scenes composed of 3D face models obtained from a single photograph of each identity. We transfer what we learn from the synthetic data to the real data using domain adaptation in a completely unsupervised way. Our model is able to generalize well to the real domain and is robust to several variations in the scenes. We report high classification accuracies in an identity classification task that takes place in a scene with unknown geometry and occluding objects.
Gemino: Practical and Robust Neural Compression for Video Conferencing
Sep 22, 2022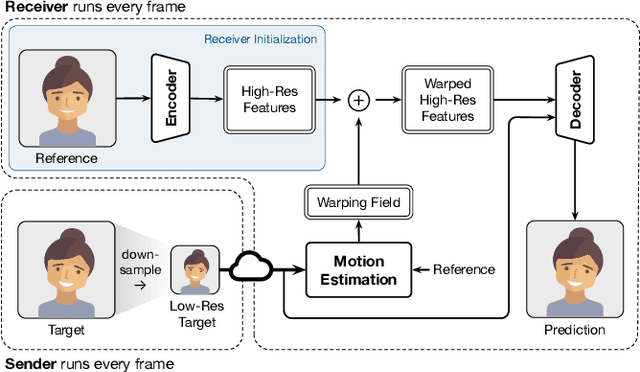
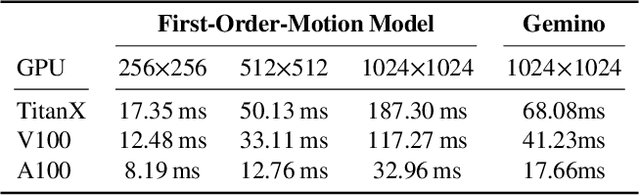


Video conferencing systems suffer from poor user experience when network conditions deteriorate because current video codecs simply cannot operate at extremely low bitrates. Recently, several neural alternatives have been proposed that reconstruct talking head videos at very low bitrates using sparse representations of each frame such as facial landmark information. However, these approaches produce poor reconstructions in scenarios with major movement or occlusions over the course of a call, and do not scale to higher resolutions. We design Gemino, a new neural compression system for video conferencing based on a novel high-frequency-conditional super-resolution pipeline. Gemino upsamples a very low-resolution version of each target frame while enhancing high-frequency details (e.g., skin texture, hair, etc.) based on information extracted from a single high-resolution reference image. We use a multi-scale architecture that runs different components of the model at different resolutions, allowing it to scale to resolutions comparable to 720p, and we personalize the model to learn specific details of each person, achieving much better fidelity at low bitrates. We implement Gemino atop aiortc, an open-source Python implementation of WebRTC, and show that it operates on 1024x1024 videos in real-time on a A100 GPU, and achieves 2.9x lower bitrate than traditional video codecs for the same perceptual quality.
Differentiable Rendering of Neural SDFs through Reparameterization
Jun 10, 2022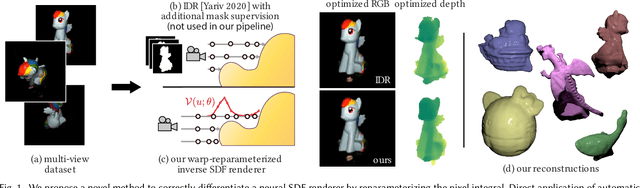

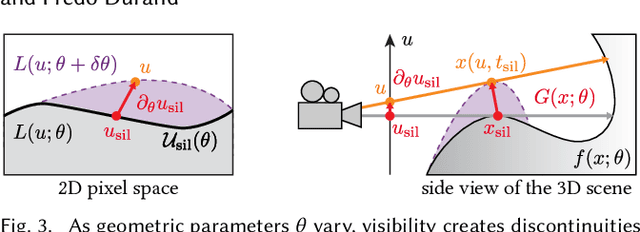
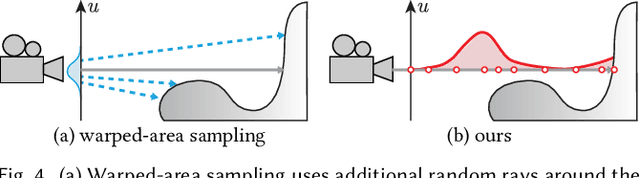
We present a method to automatically compute correct gradients with respect to geometric scene parameters in neural SDF renderers. Recent physically-based differentiable rendering techniques for meshes have used edge-sampling to handle discontinuities, particularly at object silhouettes, but SDFs do not have a simple parametric form amenable to sampling. Instead, our approach builds on area-sampling techniques and develops a continuous warping function for SDFs to account for these discontinuities. Our method leverages the distance to surface encoded in an SDF and uses quadrature on sphere tracer points to compute this warping function. We further show that this can be done by subsampling the points to make the method tractable for neural SDFs. Our differentiable renderer can be used to optimize neural shapes from multi-view images and produces comparable 3D reconstructions to recent SDF-based inverse rendering methods, without the need for 2D segmentation masks to guide the geometry optimization and no volumetric approximations to the geometry.
Plug-and-Play Algorithms for Video Snapshot Compressive Imaging
Jan 13, 2021
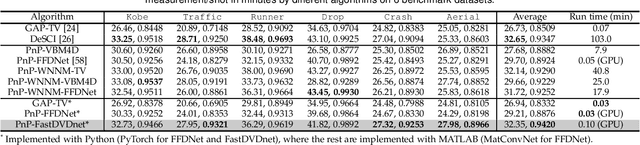


We consider the reconstruction problem of video snapshot compressive imaging (SCI), which captures high-speed videos using a low-speed 2D sensor (detector). The underlying principle of SCI is to modulate sequential high-speed frames with different masks and then these encoded frames are integrated into a snapshot on the sensor and thus the sensor can be of low-speed. On one hand, video SCI enjoys the advantages of low-bandwidth, low-power and low-cost. On the other hand, applying SCI to large-scale problems (HD or UHD videos) in our daily life is still challenging and one of the bottlenecks lies in the reconstruction algorithm. Exiting algorithms are either too slow (iterative optimization algorithms) or not flexible to the encoding process (deep learning based end-to-end networks). In this paper, we develop fast and flexible algorithms for SCI based on the plug-and-play (PnP) framework. In addition to the PnP-ADMM method, we further propose the PnP-GAP (generalized alternating projection) algorithm with a lower computational workload. We first employ the image deep denoising priors to show that PnP can recover a UHD color video with 30 frames from a snapshot measurement. Since videos have strong temporal correlation, by employing the video deep denoising priors, we achieve a significant improvement in the results. Furthermore, we extend the proposed PnP algorithms to the color SCI system using mosaic sensors, where each pixel only captures the red, green or blue channels. A joint reconstruction and demosaicing paradigm is developed for flexible and high quality reconstruction of color video SCI systems. Extensive results on both simulation and real datasets verify the superiority of our proposed algorithm.
AsyncTaichi: Whole-Program Optimizations for Megakernel Sparse Computation and Differentiable Programming
Dec 15, 2020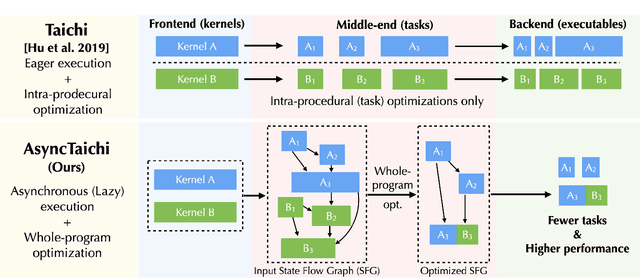
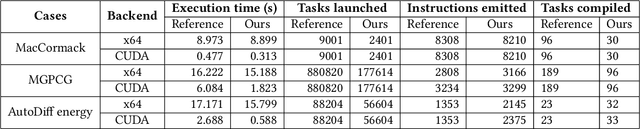

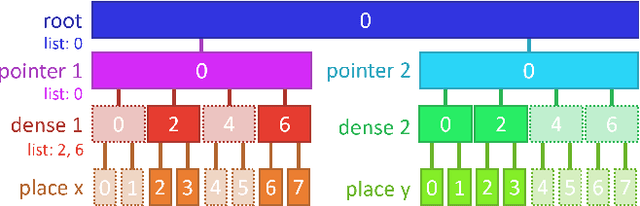
We present a whole-program optimization framework for the Taichi programming language. As an imperative language tailored for sparse and differentiable computation, Taichi's unique computational patterns lead to attractive optimization opportunities that do not present in other compiler or runtime systems. For example, to support iteration over sparse voxel grids, excessive list generation tasks are often inserted. By analyzing sparse computation programs at a higher level, our optimizer is able to remove the majority of unnecessary list generation tasks. To provide maximum programming flexibility, our optimization system conducts on-the-fly optimization of the whole computational graph consisting of Taichi kernels. The optimized Taichi kernels are then just-in-time compiled in parallel, and dispatched to parallel devices such as multithreaded CPU and massively parallel GPUs. Without any code modification on Taichi programs, our new system leads to $3.07 - 3.90\times$ fewer kernel launches and $1.73 - 2.76\times$ speed up on our benchmarks including sparse-grid physical simulation and differentiable programming.
On the Capability of Neural Networks to Generalize to Unseen Category-Pose Combinations
Jul 15, 2020
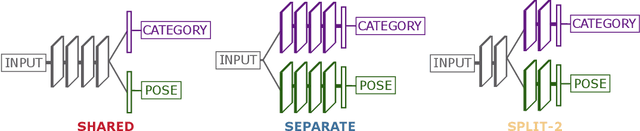
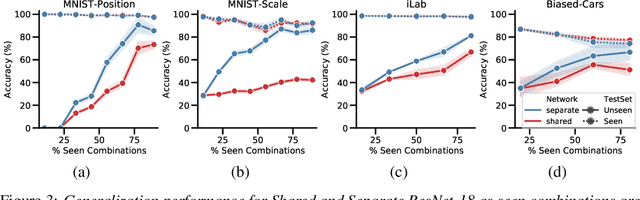
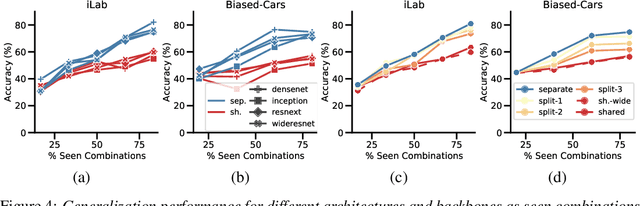
Recognizing an object's category and pose lies at the heart of visual understanding. Recent works suggest that deep neural networks (DNNs) often fail to generalize to category-pose combinations not seen during training. However, it is unclear when and how such generalization may be possible. Does the number of combinations seen during training impact generalization? Is it better to learn category and pose in separate networks, or in a single shared network? Furthermore, what are the neural mechanisms that drive the network's generalization? In this paper, we answer these questions by analyzing state-of-the-art DNNs trained to recognize both object category and pose (position, scale, and 3D viewpoint) with quantitative control over the number of category-pose combinations seen during training. We also investigate the emergence of two types of specialized neurons that can explain generalization to unseen combinations---neurons selective to category and invariant to pose, and vice versa. We perform experiments on MNIST extended with position or scale, the iLab dataset with vehicles at different viewpoints, and a challenging new dataset for car model recognition and viewpoint estimation that we introduce in this paper, the Biased-Cars dataset. Our results demonstrate that as the number of combinations seen during training increases, networks generalize better to unseen category-pose combinations, facilitated by an increase in the selectivity and invariance of individual neurons. We find that learning category and pose in separate networks compared to a shared one leads to an increase in such selectivity and invariance, as separate networks are not forced to preserve information about both category and pose. This enables separate networks to significantly outperform shared ones at predicting unseen category-pose combinations.
Painting Many Pasts: Synthesizing Time Lapse Videos of Paintings
Jan 04, 2020
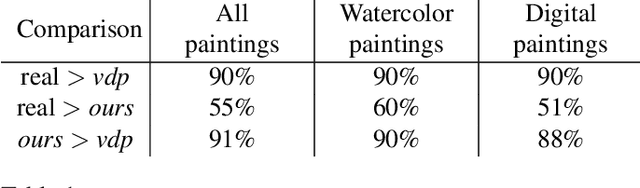
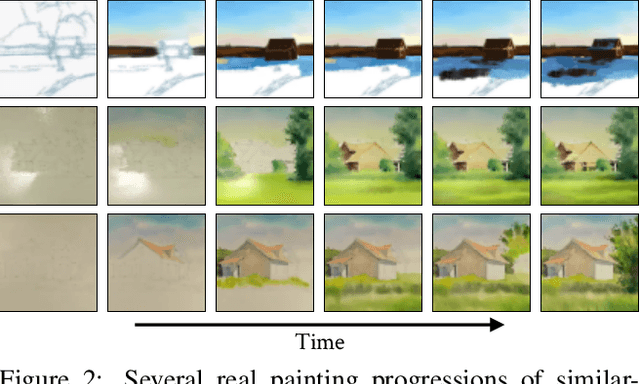
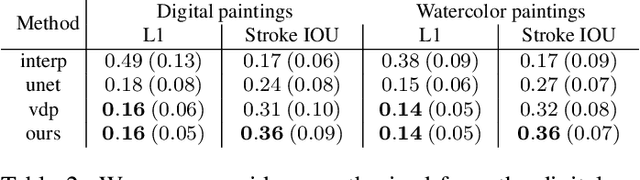
We introduce a new video synthesis task: synthesizing time lapse videos depicting how a given painting might have been created. Artists paint using unique combinations of brushes, strokes, colors, and layers. There are often many possible ways to create a given painting. Our goal is to learn to capture this rich range of possibilities. Creating distributions of long-term videos is a challenge for learning-based video synthesis methods. We present a probabilistic model that, given a single image of a completed painting, recurrently synthesizes steps of the painting process. We implement this model as a convolutional neural network, and introduce a training scheme to facilitate learning from a limited dataset of painting time lapses. We demonstrate that this model can be used to sample many time steps, enabling long-term stochastic video synthesis. We evaluate our method on digital and watercolor paintings collected from video websites, and show that human raters find our synthesized videos to be similar to time lapses produced by real artists.