 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePancakes: Consistent Multi-Protocol Image Segmentation Across Biomedical Domains
Dec 15, 2025A single biomedical image can be meaningfully segmented in multiple ways, depending on the desired application. For instance, a brain MRI can be segmented according to tissue types, vascular territories, broad anatomical regions, fine-grained anatomy, or pathology, etc. Existing automatic segmentation models typically either (1) support only a single protocol, the one they were trained on, or (2) require labor-intensive manual prompting to specify the desired segmentation. We introduce Pancakes, a framework that, given a new image from a previously unseen domain, automatically generates multi-label segmentation maps for multiple plausible protocols, while maintaining semantic consistency across related images. Pancakes introduces a new problem formulation that is not currently attainable by existing foundation models. In a series of experiments on seven held-out datasets, we demonstrate that our model can significantly outperform existing foundation models in producing several plausible whole-image segmentations, that are semantically coherent across images.
AtlasMorph: Learning conditional deformable templates for brain MRI
Nov 17, 2025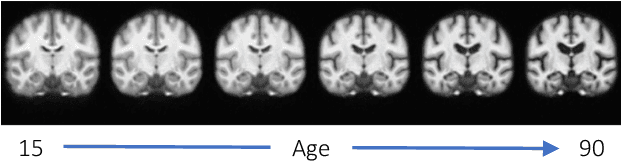
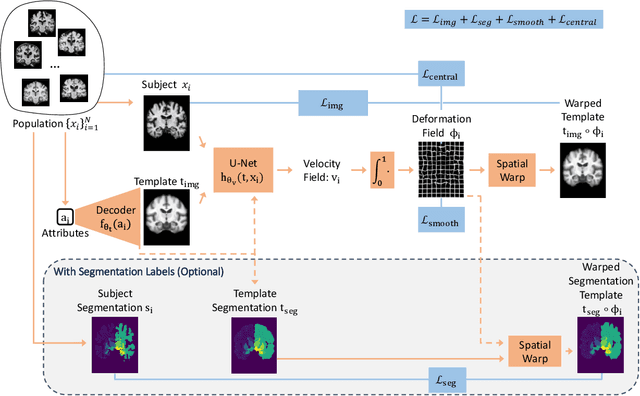
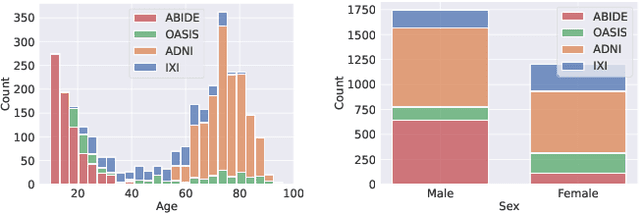
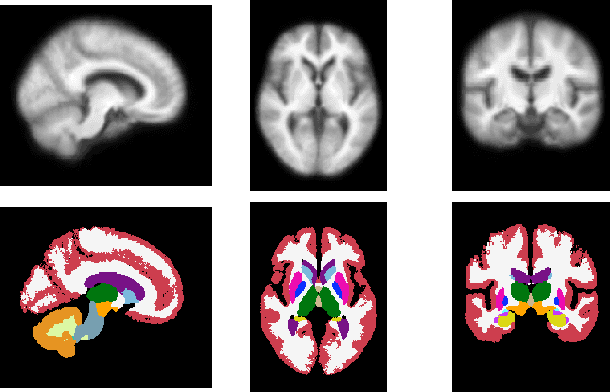
Deformable templates, or atlases, are images that represent a prototypical anatomy for a population, and are often enhanced with probabilistic anatomical label maps. They are commonly used in medical image analysis for population studies and computational anatomy tasks such as registration and segmentation. Because developing a template is a computationally expensive process, relatively few templates are available. As a result, analysis is often conducted with sub-optimal templates that are not truly representative of the study population, especially when there are large variations within this population. We propose a machine learning framework that uses convolutional registration neural networks to efficiently learn a function that outputs templates conditioned on subject-specific attributes, such as age and sex. We also leverage segmentations, when available, to produce anatomical segmentation maps for the resulting templates. The learned network can also be used to register subject images to the templates. We demonstrate our method on a compilation of 3D brain MRI datasets, and show that it can learn high-quality templates that are representative of populations. We find that annotated conditional templates enable better registration than their unlabeled unconditional counterparts, and outperform other templates construction methods.
VoxelPrompt: A Vision-Language Agent for Grounded Medical Image Analysis
Oct 10, 2024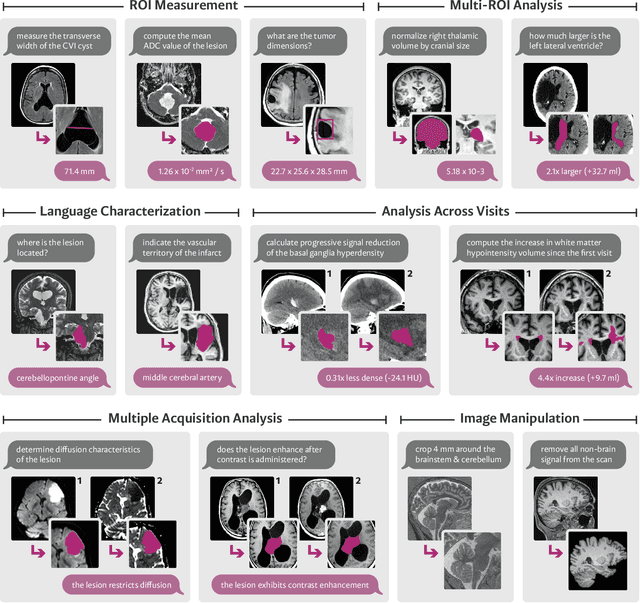
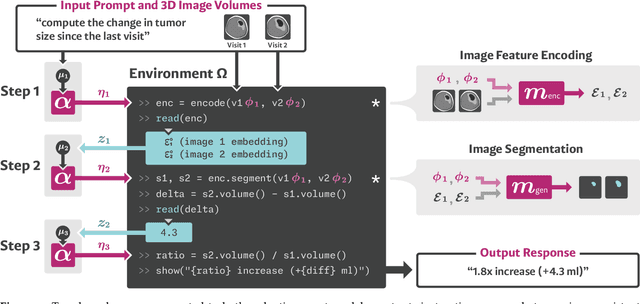
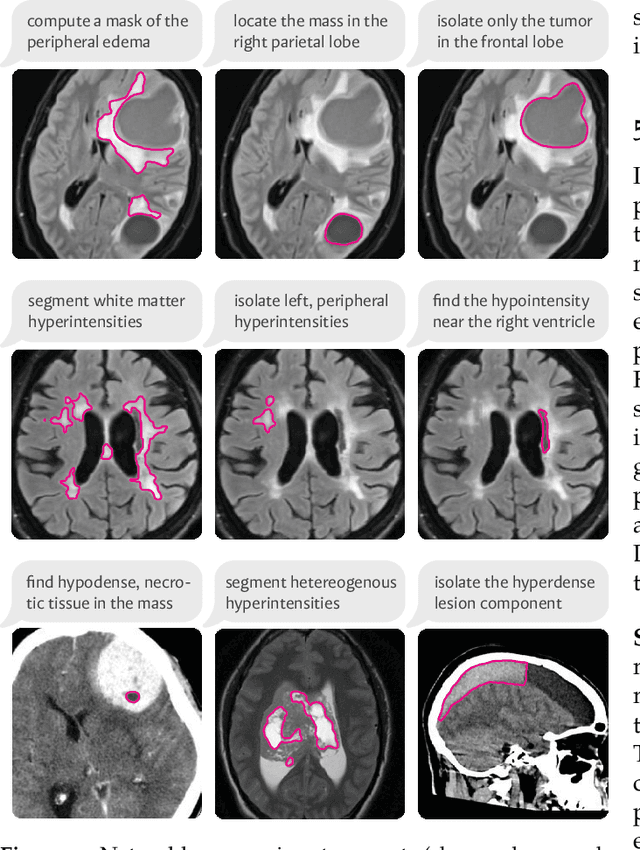
We present VoxelPrompt, an agent-driven vision-language framework that tackles diverse radiological tasks through joint modeling of natural language, image volumes, and analytical metrics. VoxelPrompt is multi-modal and versatile, leveraging the flexibility of language interaction while providing quantitatively grounded image analysis. Given a variable number of 3D medical volumes, such as MRI and CT scans, VoxelPrompt employs a language agent that iteratively predicts executable instructions to solve a task specified by an input prompt. These instructions communicate with a vision network to encode image features and generate volumetric outputs (e.g., segmentations). VoxelPrompt interprets the results of intermediate instructions and plans further actions to compute discrete measures (e.g., tumor growth across a series of scans) and present relevant outputs to the user. We evaluate this framework in a sandbox of diverse neuroimaging tasks, and we show that the single VoxelPrompt model can delineate hundreds of anatomical and pathological features, measure many complex morphological properties, and perform open-language analysis of lesion characteristics. VoxelPrompt carries out these objectives with accuracy similar to that of fine-tuned, single-task models for segmentation and visual question-answering, while facilitating a much larger range of tasks. Therefore, by supporting accurate image processing with language interaction, VoxelPrompt provides comprehensive utility for numerous imaging tasks that traditionally require specialized models to address.
Beyond Faithfulness: A Framework to Characterize and Compare Saliency Methods
Jun 07, 2022
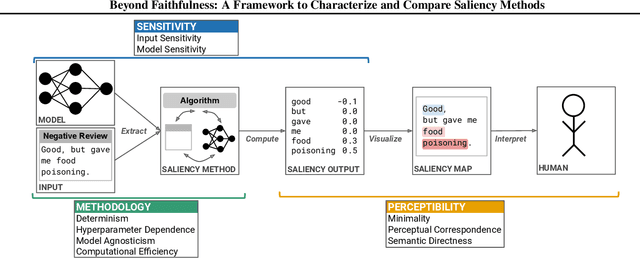
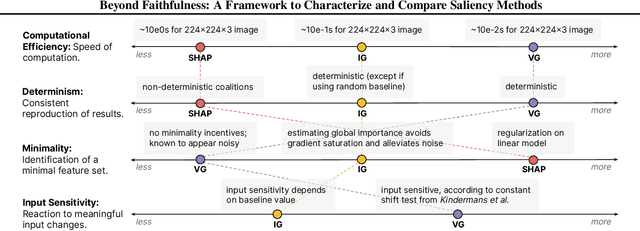

Saliency methods calculate how important each input feature is to a machine learning model's prediction, and are commonly used to understand model reasoning. "Faithfulness", or how fully and accurately the saliency output reflects the underlying model, is an oft-cited desideratum for these methods. However, explanation methods must necessarily sacrifice certain information in service of user-oriented goals such as simplicity. To that end, and akin to performance metrics, we frame saliency methods as abstractions: individual tools that provide insight into specific aspects of model behavior and entail tradeoffs. Using this framing, we describe a framework of nine dimensions to characterize and compare the properties of saliency methods. We group these dimensions into three categories that map to different phases of the interpretation process: methodology, or how the saliency is calculated; sensitivity, or relationships between the saliency result and the underlying model or input; and, perceptibility, or how a user interprets the result. As we show, these dimensions give us a granular vocabulary for describing and comparing saliency methods -- for instance, allowing us to develop "saliency cards" as a form of documentation, or helping downstream users understand tradeoffs and choose a method for a particular use case. Moreover, by situating existing saliency methods within this framework, we identify opportunities for future work, including filling gaps in the landscape and developing new evaluation metrics.
Intuitively Assessing ML Model Reliability through Example-Based Explanations and Editing Model Inputs
Feb 17, 2021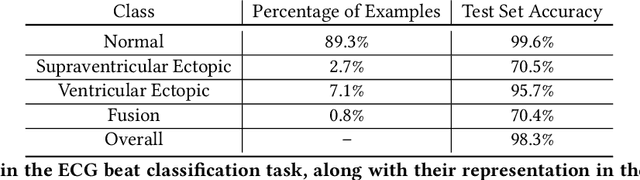
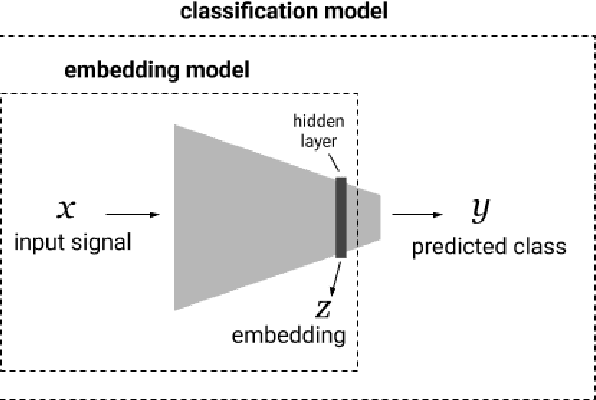
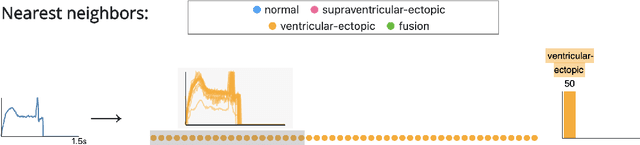
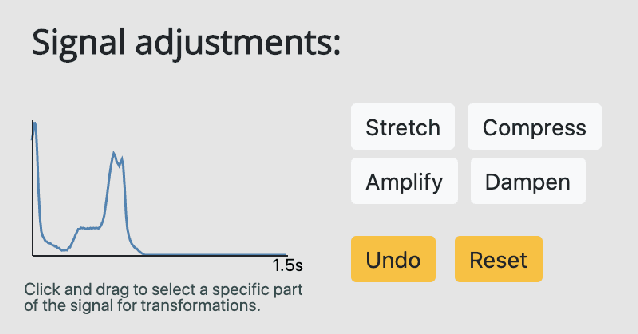
Interpretability methods aim to help users build trust in and understand the capabilities of machine learning models. However, existing approaches often rely on abstract, complex visualizations that poorly map to the task at hand or require non-trivial ML expertise to interpret. Here, we present two interface modules to facilitate a more intuitive assessment of model reliability. To help users better characterize and reason about a model's uncertainty, we visualize raw and aggregate information about a given input's nearest neighbors in the training dataset. Using an interactive editor, users can manipulate this input in semantically-meaningful ways, determine the effect on the output, and compare against their prior expectations. We evaluate our interface using an electrocardiogram beat classification case study. Compared to a baseline feature importance interface, we find that 9 physicians are better able to align the model's uncertainty with clinically relevant factors and build intuition about its capabilities and limitations.
Painting Many Pasts: Synthesizing Time Lapse Videos of Paintings
Jan 04, 2020
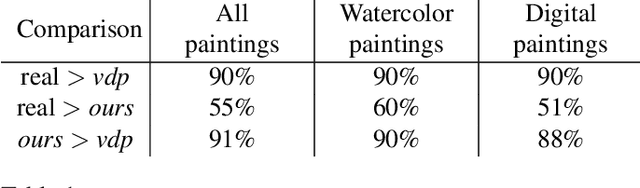
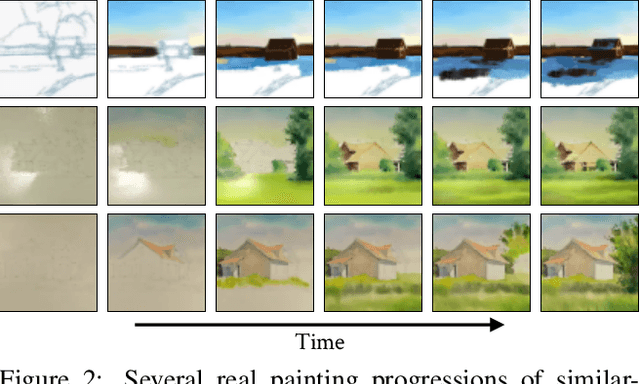
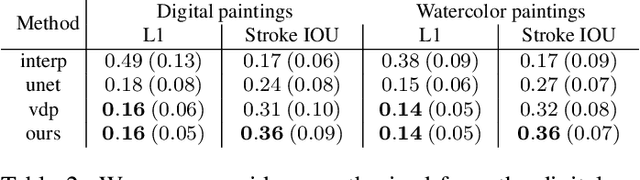
We introduce a new video synthesis task: synthesizing time lapse videos depicting how a given painting might have been created. Artists paint using unique combinations of brushes, strokes, colors, and layers. There are often many possible ways to create a given painting. Our goal is to learn to capture this rich range of possibilities. Creating distributions of long-term videos is a challenge for learning-based video synthesis methods. We present a probabilistic model that, given a single image of a completed painting, recurrently synthesizes steps of the painting process. We implement this model as a convolutional neural network, and introduce a training scheme to facilitate learning from a limited dataset of painting time lapses. We demonstrate that this model can be used to sample many time steps, enabling long-term stochastic video synthesis. We evaluate our method on digital and watercolor paintings collected from video websites, and show that human raters find our synthesized videos to be similar to time lapses produced by real artists.
Visual Deprojection: Probabilistic Recovery of Collapsed Dimensions
Sep 01, 2019
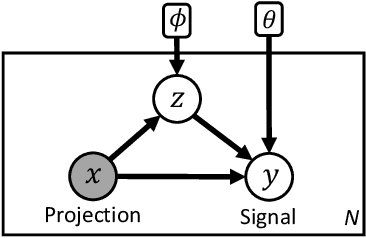
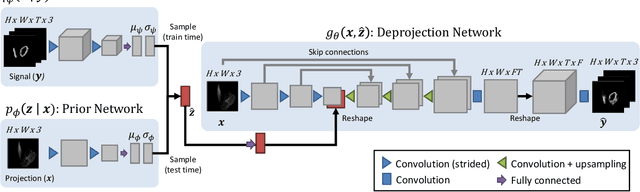

We introduce visual deprojection: the task of recovering an image or video that has been collapsed along a dimension. Projections arise in various contexts, such as long-exposure photography, where a dynamic scene is collapsed in time to produce a motion-blurred image, and corner cameras, where reflected light from a scene is collapsed along a spatial dimension because of an edge occluder to yield a 1D video. Deprojection is ill-posed-- often there are many plausible solutions for a given input. We first propose a probabilistic model capturing the ambiguity of the task. We then present a variational inference strategy using convolutional neural networks as functional approximators. Sampling from the inference network at test time yields plausible candidates from the distribution of original signals that are consistent with a given input projection. We evaluate the method on several datasets for both spatial and temporal deprojection tasks. We first demonstrate the method can recover human gait videos and face images from spatial projections, and then show that it can recover videos of moving digits from dramatically motion-blurred images obtained via temporal projection.
Data augmentation using learned transformations for one-shot medical image segmentation
Apr 06, 2019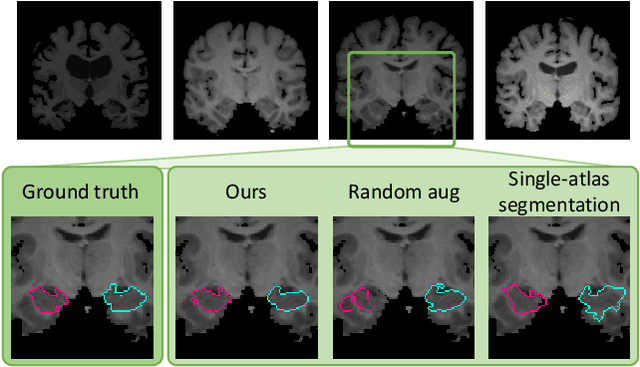
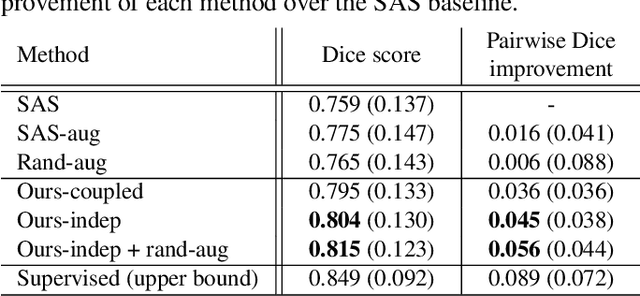
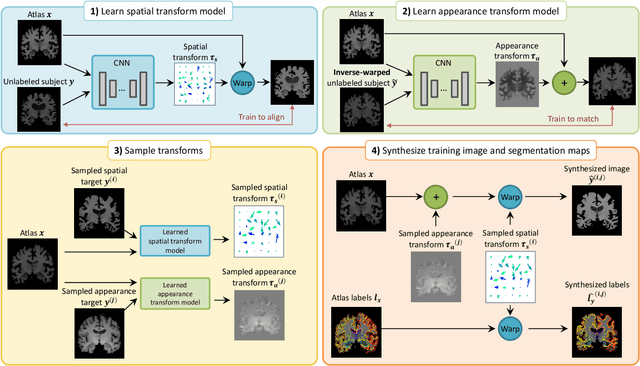
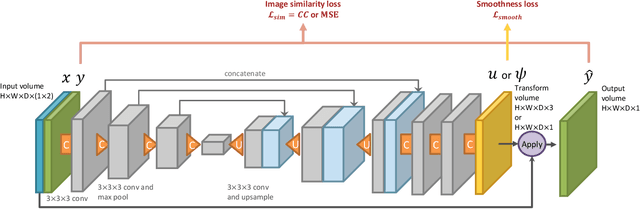
Image segmentation is an important task in many medical applications. Methods based on convolutional neural networks attain state-of-the-art accuracy; however, they typically rely on supervised training with large labeled datasets. Labeling medical images requires significant expertise and time, and typical hand-tuned approaches for data augmentation fail to capture the complex variations in such images. We present an automated data augmentation method for synthesizing labeled medical images. We demonstrate our method on the task of segmenting magnetic resonance imaging (MRI) brain scans. Our method requires only a single segmented scan, and leverages other unlabeled scans in a semi-supervised approach. We learn a model of transformations from the images, and use the model along with the labeled example to synthesize additional labeled examples. Each transformation is comprised of a spatial deformation field and an intensity change, enabling the synthesis of complex effects such as variations in anatomy and image acquisition procedures. We show that training a supervised segmenter with these new examples provides significant improvements over state-of-the-art methods for one-shot biomedical image segmentation. Our code is available at https://github.com/xamyzhao/brainstorm.
A Framework for Understanding Unintended Consequences of Machine Learning
Jan 28, 2019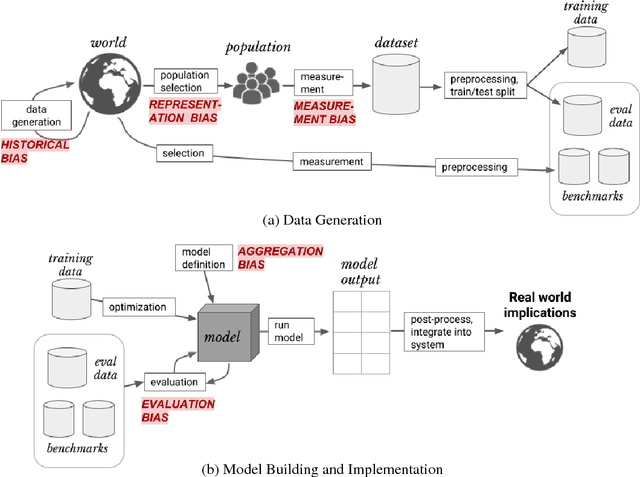
As machine learning increasingly affects people and society, it is important that we strive for a comprehensive and unified understanding of how and why unwanted consequences arise. For instance, downstream harms to particular groups are often blamed on "biased data," but this concept encompass too many issues to be useful in developing solutions. In this paper, we provide a framework that partitions sources of downstream harm in machine learning into five distinct categories spanning the data generation and machine learning pipeline. We describe how these issues arise, how they are relevant to particular applications, and how they motivate different solutions. In doing so, we aim to facilitate the development of solutions that stem from an understanding of application-specific populations and data generation processes, rather than relying on general claims about what may or may not be "fair."
EXTRACT: Strong Examples from Weakly-Labeled Sensor Data
Sep 29, 2016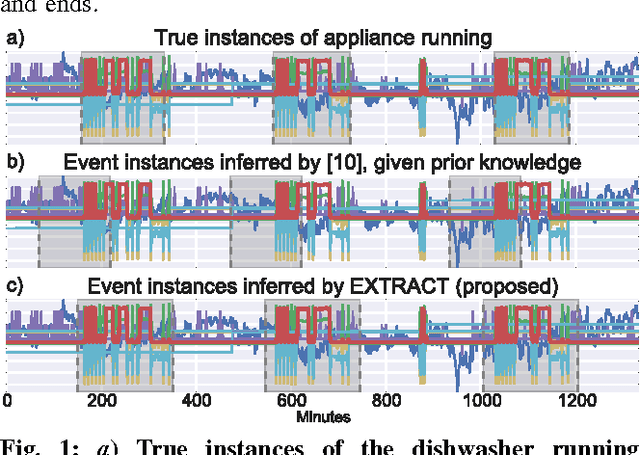
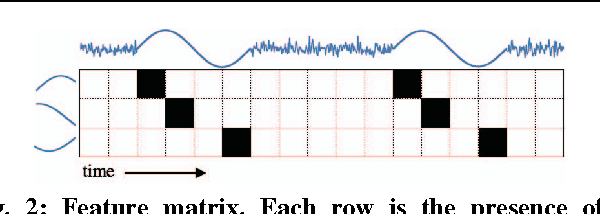
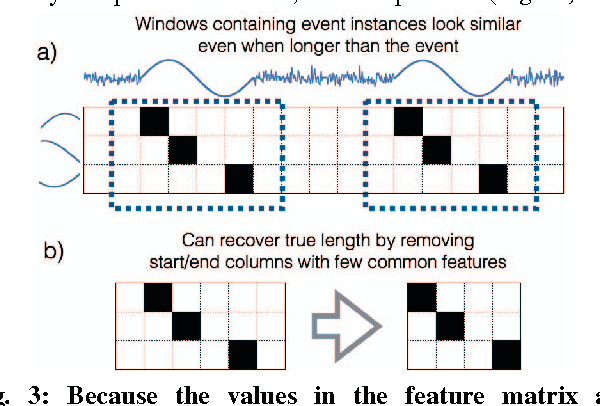
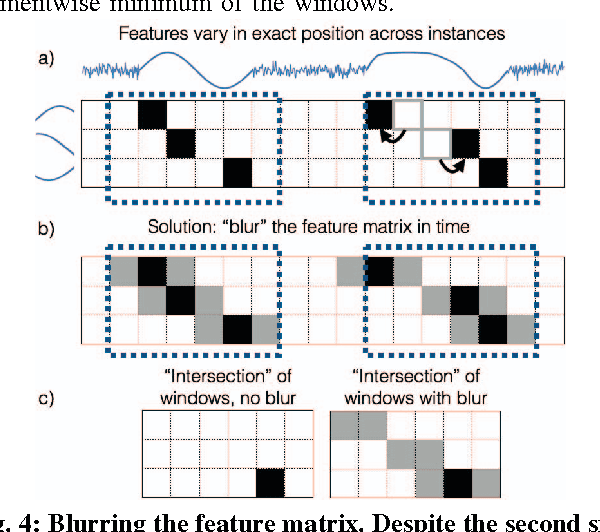
Thanks to the rise of wearable and connected devices, sensor-generated time series comprise a large and growing fraction of the world's data. Unfortunately, extracting value from this data can be challenging, since sensors report low-level signals (e.g., acceleration), not the high-level events that are typically of interest (e.g., gestures). We introduce a technique to bridge this gap by automatically extracting examples of real-world events in low-level data, given only a rough estimate of when these events have taken place. By identifying sets of features that repeat in the same temporal arrangement, we isolate examples of such diverse events as human actions, power consumption patterns, and spoken words with up to 96% precision and recall. Our method is fast enough to run in real time and assumes only minimal knowledge of which variables are relevant or the lengths of events. Our evaluation uses numerous publicly available datasets and over 1 million samples of manually labeled sensor data.