 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Detection of Patient Deterioration from Real-Time Wearable Monitoring System
May 02, 2025Early detection of patient deterioration is crucial for reducing mortality rates. Heart rate data has shown promise in assessing patient health, and wearable devices offer a cost-effective solution for real-time monitoring. However, extracting meaningful insights from diverse heart rate data and handling missing values in wearable device data remain key challenges. To address these challenges, we propose TARL, an innovative approach that models the structural relationships of representative subsequences, known as shapelets, in heart rate time series. TARL creates a shapelet-transition knowledge graph to model shapelet dynamics in heart rate time series, indicating illness progression and potential future changes. We further introduce a transition-aware knowledge embedding to reinforce relationships among shapelets and quantify the impact of missing values, enabling the formulation of comprehensive heart rate representations. These representations capture explanatory structures and predict future heart rate trends, aiding early illness detection. We collaborate with physicians and nurses to gather ICU patient heart rate data from wearables and diagnostic metrics assessing illness severity for evaluating deterioration. Experiments on real-world ICU data demonstrate that TARL achieves both high reliability and early detection. A case study further showcases TARL's explainable detection process, highlighting its potential as an AI-driven tool to assist clinicians in recognizing early signs of patient deterioration.
DeCo: Defect-Aware Modeling with Contrasting Matching for Optimizing Task Assignment in Online IC Testing
May 01, 2025In the semiconductor industry, integrated circuit (IC) processes play a vital role, as the rising complexity and market expectations necessitate improvements in yield. Identifying IC defects and assigning IC testing tasks to the right engineers improves efficiency and reduces losses. While current studies emphasize fault localization or defect classification, they overlook the integration of defect characteristics, historical failures, and the insights from engineer expertise, which restrains their effectiveness in improving IC handling. To leverage AI for these challenges, we propose DeCo, an innovative approach for optimizing task assignment in IC testing. DeCo constructs a novel defect-aware graph from IC testing reports, capturing co-failure relationships to enhance defect differentiation, even with scarce defect data. Additionally, it formulates defect-aware representations for engineers and tasks, reinforced by local and global structure modeling on the defect-aware graph. Finally, a contrasting-based assignment mechanism pairs testing tasks with QA engineers by considering their skill level and current workload, thus promoting an equitable and efficient job dispatch. Experiments on a real-world dataset demonstrate that DeCo achieves the highest task-handling success rates in different scenarios, exceeding 80\%, while also maintaining balanced workloads on both scarce or expanded defect data. Moreover, case studies reveal that DeCo can assign tasks to potentially capable engineers, even for their unfamiliar defects, highlighting its potential as an AI-driven solution for the real-world IC failure analysis and task handling.
Uncertainty-Aware Critic Augmentation for Hierarchical Multi-Agent EV Charging Control
Dec 23, 2024The advanced bidirectional EV charging and discharging technology, aimed at supporting grid stability and emergency operations, has driven a growing interest in workplace applications. It not only effectively reduces electricity expenses but also enhances the resilience of handling practical issues, such as peak power limitation, fluctuating energy prices, and unpredictable EV departures. However, existing EV charging strategies have yet to fully consider these factors in a way that benefits both office buildings and EV users simultaneously. To address these issues, we propose HUCA, a novel real-time charging control for regulating energy demands for both the building and electric vehicles. HUCA employs hierarchical actor-critic networks to dynamically reduce electricity costs in buildings, accounting for the needs of EV charging in the dynamic pricing scenario. To tackle the uncertain EV departures, a new critic augmentation is introduced to account for departure uncertainties in evaluating the charging decisions, while maintaining the robustness of the charging control. Experiments on real-world electricity datasets under both simulated certain and uncertain departure scenarios demonstrate that HUCA outperforms baselines in terms of total electricity costs while maintaining competitive performance in fulfilling EV charging requirements. A case study also manifests that HUCA effectively balances energy supply between the building and EVs based on real-time information.
Transferring Knowledge from Text to Predict Disease Onset
Aug 06, 2016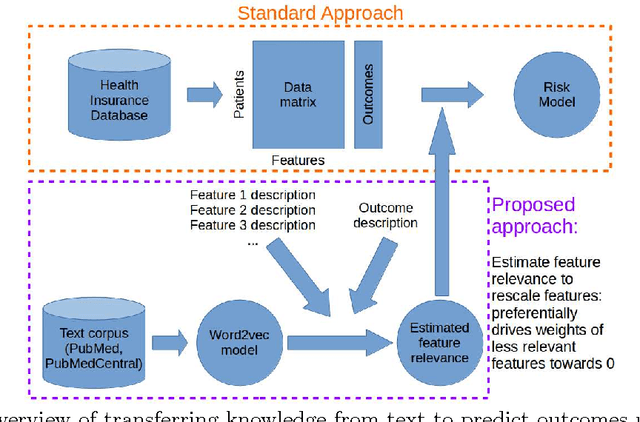
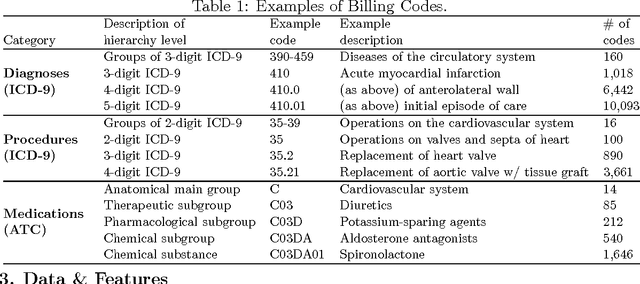
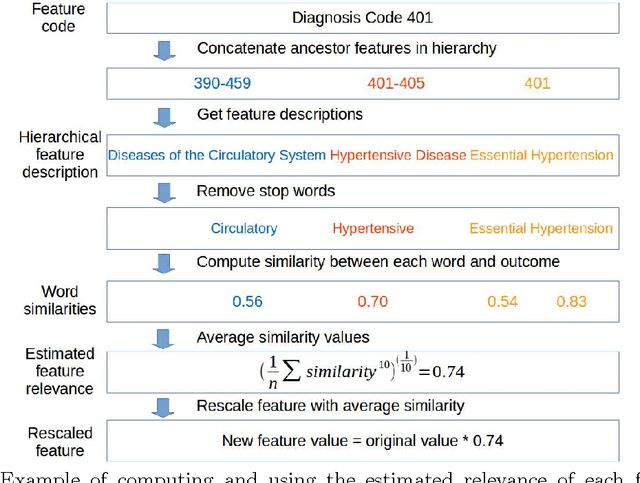
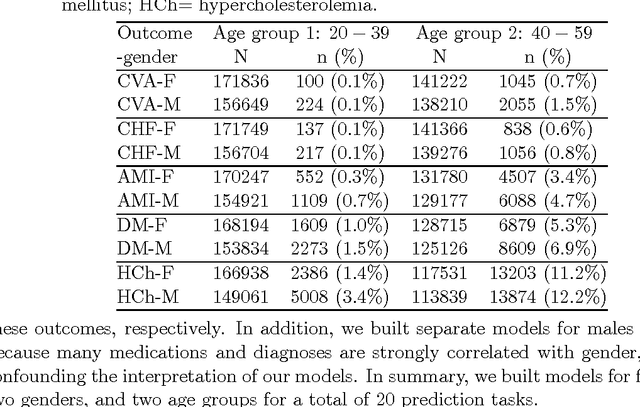
In many domains such as medicine, training data is in short supply. In such cases, external knowledge is often helpful in building predictive models. We propose a novel method to incorporate publicly available domain expertise to build accurate models. Specifically, we use word2vec models trained on a domain-specific corpus to estimate the relevance of each feature's text description to the prediction problem. We use these relevance estimates to rescale the features, causing more important features to experience weaker regularization. We apply our method to predict the onset of five chronic diseases in the next five years in two genders and two age groups. Our rescaling approach improves the accuracy of the model, particularly when there are few positive examples. Furthermore, our method selects 60% fewer features, easing interpretation by physicians. Our method is applicable to other domains where feature and outcome descriptions are available.