 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVocal Prognostic Digital Biomarkers in Monitoring Chronic Heart Failure: A Longitudinal Observational Study
Mar 31, 2026Objective: This study aimed to evaluate which voice features can predict health deterioration in patients with chronic HF. Background: Heart failure (HF) is a chronic condition with progressive deterioration and acute decompensations, often requiring hospitalization and imposing substantial healthcare and economic burdens. Current standard-of-care (SoC) home monitoring, such as weight tracking, lacks predictive accuracy and requires high patient engagement. Voice is a promising non-invasive biomarker, though prior studies have mainly focused on acute HF stages. Methods: In a 2-month longitudinal study, 32 patients with HF collected daily voice recordings and SoC measures of weight and blood pressure at home, with biweekly questionnaires for health status. Acoustic analysis generated detailed vowel and speech features. Time-series features were extracted from aggregated lookback windows (e.g., 7 days) to predict next-day health status. Explainable machine learning with nested cross-validation identified top vocal biomarkers, and a case study illustrated model application. Results: A total of 21,863 recordings were analyzed. Acoustic vowel features showed strong correlations with health status. Time-series voice features within the lookback window outperformed corresponding standard care measures, achieving peak sensitivity and specificity of 0.826 and 0.782 versus 0.783 and 0.567 for SoC metrics. Key prognostic voice features identifying deterioration included delayed energy shift, low energy variability, and higher shimmer variability in vowels, along with reduced speaking and articulation rate, lower phonation ratio, decreased voice quality, and increased formant variability in speech. Conclusion: Voice-based monitoring offers a non-invasive approach to detect early health changes in chronic HF, supporting proactive and personalized care.
Classifying Phonotrauma Severity from Vocal Fold Images with Soft Ordinal Regression
Nov 12, 2025



Phonotrauma refers to vocal fold tissue damage resulting from exposure to forces during voicing. It occurs on a continuum from mild to severe, and treatment options can vary based on severity. Assessment of severity involves a clinician's expert judgment, which is costly and can vary widely in reliability. In this work, we present the first method for automatically classifying phonotrauma severity from vocal fold images. To account for the ordinal nature of the labels, we adopt a widely used ordinal regression framework. To account for label uncertainty, we propose a novel modification to ordinal regression loss functions that enables them to operate on soft labels reflecting annotator rating distributions. Our proposed soft ordinal regression method achieves predictive performance approaching that of clinical experts, while producing well-calibrated uncertainty estimates. By providing an automated tool for phonotrauma severity assessment, our work can enable large-scale studies of phonotrauma, ultimately leading to improved clinical understanding and patient care.
Effects of Recording Condition and Number of Monitored Days on Discriminative Power of the Daily Phonotrauma Index
Sep 04, 2024


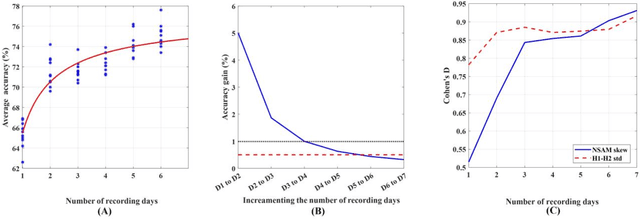
Objective: The Daily Phonotrauma Index (DPI) can quantify pathophysiological mechanisms associated with daily voice use in individuals with phonotraumatic vocal hyperfunction (PVH). Since DPI was developed based on week-long ambulatory voice monitoring, this study investigated if DPI can achieve comparable performance using (1) short laboratory speech tasks and (2) fewer than seven days of ambulatory data. Method: An ambulatory voice monitoring system recorded the vocal function/behavior of 134 females with PVH and vocally healthy matched controls in two different conditions. In the lab, the participants read the first paragraph of the Rainbow Passage and produced spontaneous speech (in-lab data). They were then monitored for seven days (in-field data). Separate DPI models were trained from in-lab and in-field data using the standard deviation of the difference between the magnitude of the first two harmonics (H1-H2) and the skewness of neck-surface acceleration magnitude. First, 10-fold cross-validation evaluated classification performance of in-lab and in-field DPIs. Second, the effect of the number of ambulatory monitoring days on the accuracy of in-field DPI classification was quantified. Results: The average in-lab DPI accuracy computed from the Rainbow passage and spontaneous speech were, respectively, 57.9% and 48.9%, which are close to chance performance. The average classification accuracy of in-field DPI was significantly higher with a very large effect size (73.4%, Cohens D = 1.8). Second, the average in-field DPI accuracy increased from 66.5% for one day to 75.0% for seven days, with the gain of including an additional day on accuracy dropping below 1 percentage point after 4 days.
Toward Generalizable Machine Learning Models in Speech, Language, and Hearing Sciences: Sample Size Estimation and Reducing Overfitting
Aug 30, 2023This study's first purpose is to provide quantitative evidence that would incentivize researchers to instead use the more robust method of nested cross-validation. The second purpose is to present methods and MATLAB codes for doing power analysis for ML-based analysis during the design of a study. Monte Carlo simulations were used to quantify the interactions between the employed cross-validation method, the discriminative power of features, the dimensionality of the feature space, and the dimensionality of the model. Four different cross-validations (single holdout, 10-fold, train-validation-test, and nested 10-fold) were compared based on the statistical power and statistical confidence of the ML models. Distributions of the null and alternative hypotheses were used to determine the minimum required sample size for obtaining a statistically significant outcome ({\alpha}=0.05, 1-\b{eta}=0.8). Statistical confidence of the model was defined as the probability of correct features being selected and hence being included in the final model. Our analysis showed that the model generated based on the single holdout method had very low statistical power and statistical confidence and that it significantly overestimated the accuracy. Conversely, the nested 10-fold cross-validation resulted in the highest statistical confidence and the highest statistical power, while providing an unbiased estimate of the accuracy. The required sample size with a single holdout could be 50% higher than what would be needed if nested cross-validation were used. Confidence in the model based on nested cross-validation was as much as four times higher than the confidence in the single holdout-based model. A computational model, MATLAB codes, and lookup tables are provided to assist researchers with estimating the sample size during the design of their future studies.
Longitudinal Acoustic Speech Tracking Following Pediatric Traumatic Brain Injury
Sep 09, 2022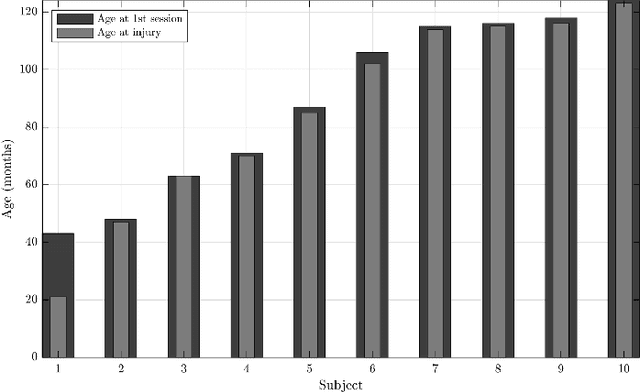
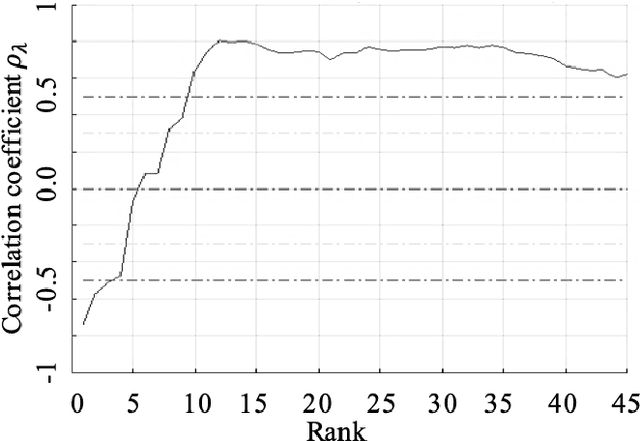
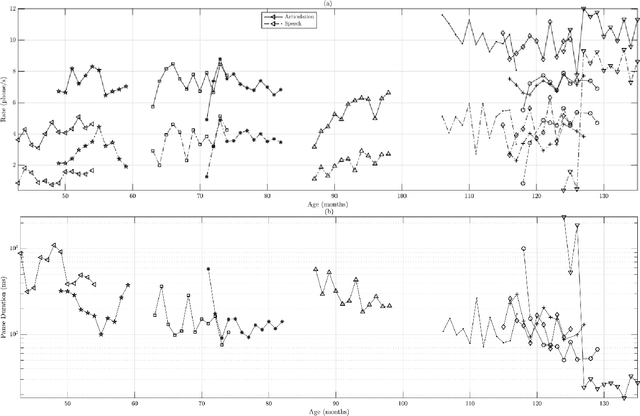
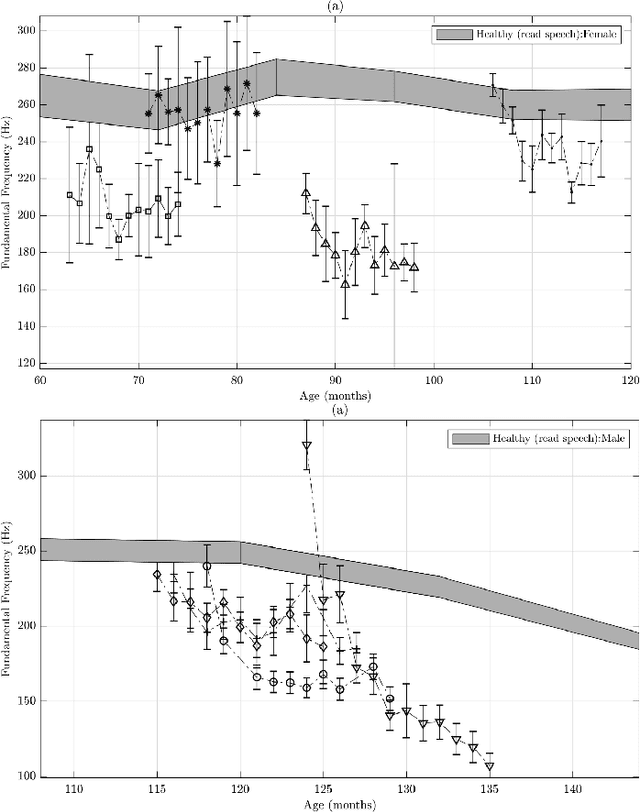
Recommendations for common outcome measures following pediatric traumatic brain injury (TBI) support the integration of instrumental measurements alongside perceptual assessment in recovery and treatment plans. A comprehensive set of sensitive, robust and non-invasive measurements is therefore essential in assessing variations in speech characteristics over time following pediatric TBI. In this article, we study the changes in the acoustic speech patterns of a pediatric cohort of ten subjects diagnosed with severe TBI. We extract a diverse set of both well-known and novel acoustic features from child speech recorded throughout the year after the child produced intelligible words. These features are analyzed individually and by speech subsystem, within-subject and across the cohort. As a group, older children exhibit highly significant (p<0.01) increases in pitch variation and phoneme diversity, shortened pause length, and steadying articulation rate variability. Younger children exhibit similar steadied rate variability alongside an increase in formant-based articulation complexity. Correlation analysis of the feature set with age and comparisons to normative developmental data confirm that age at injury plays a significant role in framing the recovery trajectory. Nearly all speech features significantly change (p<0.05) for the cohort as a whole, confirming that acoustic measures supplementing perceptual assessment are needed to identify efficacious treatment targets for speech therapy following TBI.
Uncovering Voice Misuse Using Symbolic Mismatch
Aug 08, 2016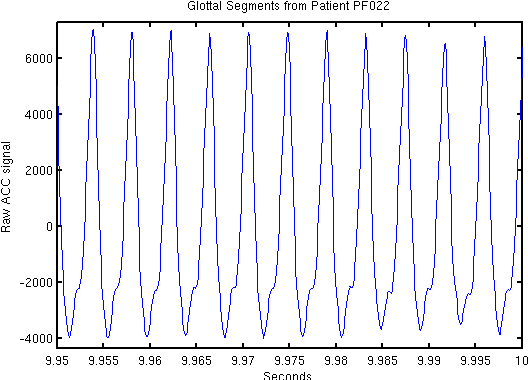
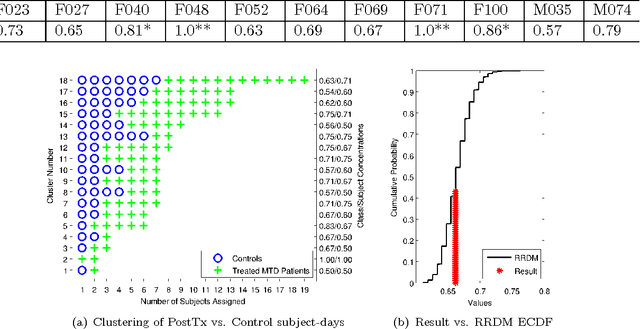

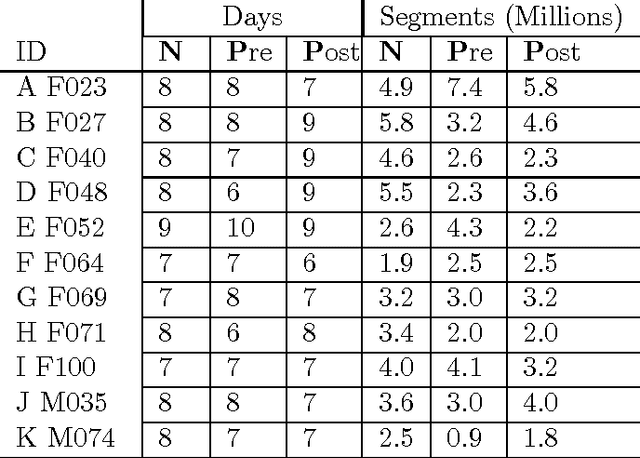
Voice disorders affect an estimated 14 million working-aged Americans, and many more worldwide. We present the first large scale study of vocal misuse based on long-term ambulatory data collected by an accelerometer placed on the neck. We investigate an unsupervised data mining approach to uncovering latent information about voice misuse. We segment signals from over 253 days of data from 22 subjects into over a hundred million single glottal pulses (closures of the vocal folds), cluster segments into symbols, and use symbolic mismatch to uncover differences between patients and matched controls, and between patients pre- and post-treatment. Our results show significant behavioral differences between patients and controls, as well as between some pre- and post-treatment patients. Our proposed approach provides an objective basis for helping diagnose behavioral voice disorders, and is a first step towards a more data-driven understanding of the impact of voice therapy.