 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcoustically-Driven Phoneme Removal That Preserves Vocal Affect Cues
Oct 26, 2022


In this paper, we propose a method for removing linguistic information from speech for the purpose of isolating paralinguistic indicators of affect. The immediate utility of this method lies in clinical tests of sensitivity to vocal affect that are not confounded by language, which is impaired in a variety of clinical populations. The method is based on simultaneous recordings of speech audio and electroglottographic (EGG) signals. The speech audio signal is used to estimate the average vocal tract filter response and amplitude envelop. The EGG signal supplies a direct correlate of voice source activity that is mostly independent of phonetic articulation. These signals are used to create a third signal designed to capture as much paralinguistic information from the vocal production system as possible -- maximizing the retention of bioacoustic cues to affect -- while eliminating phonetic cues to verbal meaning. To evaluate the success of this method, we studied the perception of corresponding speech audio and transformed EGG signals in an affect rating experiment with online listeners. The results show a high degree of similarity in the perceived affect of matched signals, indicating that our method is effective.
Reconstructing the Dynamic Directivity of Unconstrained Speech
Sep 09, 2022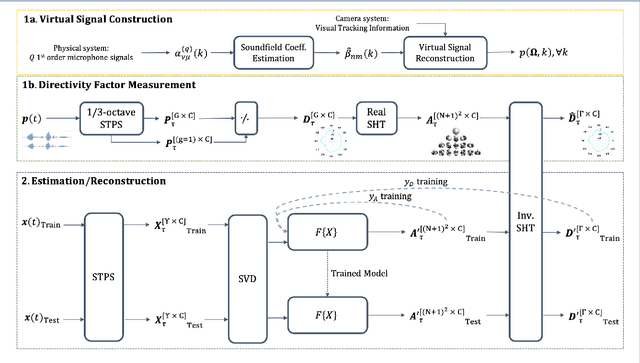
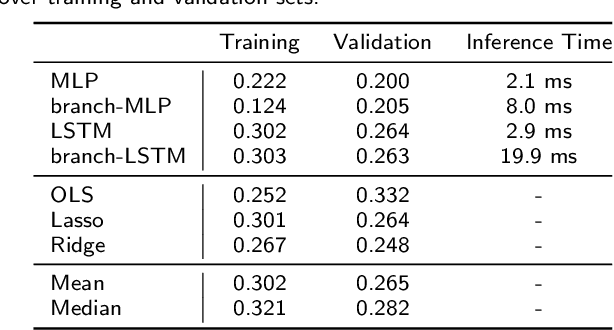

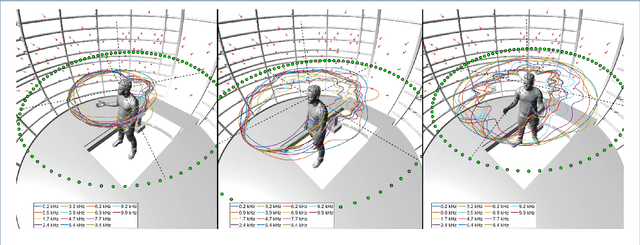
An accurate model of natural speech directivity is an important step toward achieving realistic vocal presence within a virtual communication setting. In this article, we propose a method to estimate and reconstruct the spatial energy distribution pattern of natural, unconstrained speech. We detail our method in two stages. Using recordings of speech captured by a real, static microphone array, we create a virtual array that tracks with the movement of the speaker over time. We use this egocentric virtual array to measure and encode the high-resolution directivity pattern of the speech signal as it dynamically evolves with natural speech and movement. Utilizing this encoded directivity representation, we train a machine learning model that leverages to estimate the full, dynamic directivity pattern when given a limited set of speech signals, as would be the case when speech is recorded using the microphones on a head-mounted display (HMD). We examine a variety of model architectures and training paradigms, and discuss the utility and practicality of each implementation. Our results demonstrate that neural networks can be used to regress from limited speech information to an accurate, dynamic estimation of the full directivity pattern.
Longitudinal Acoustic Speech Tracking Following Pediatric Traumatic Brain Injury
Sep 09, 2022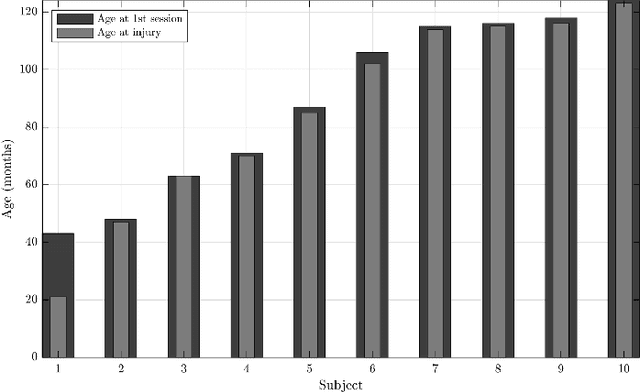
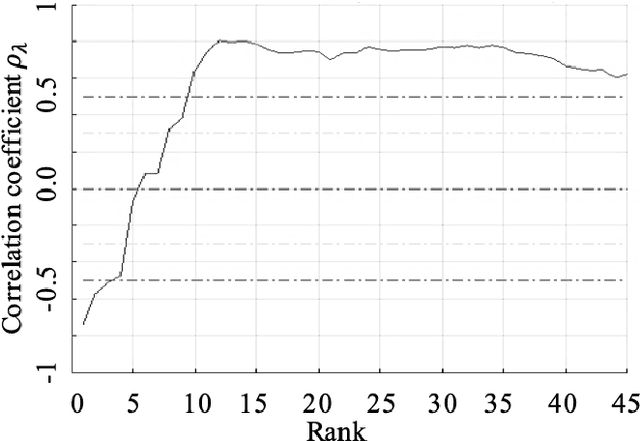
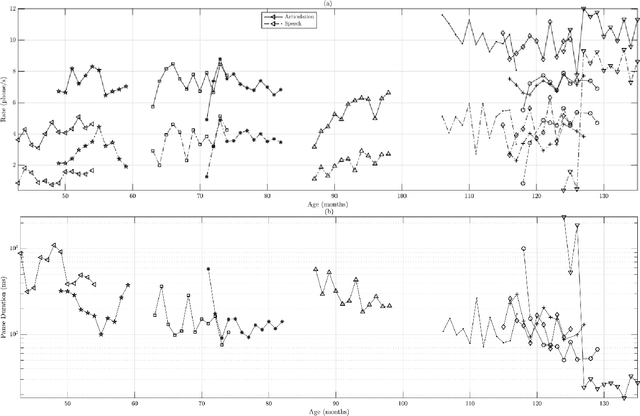
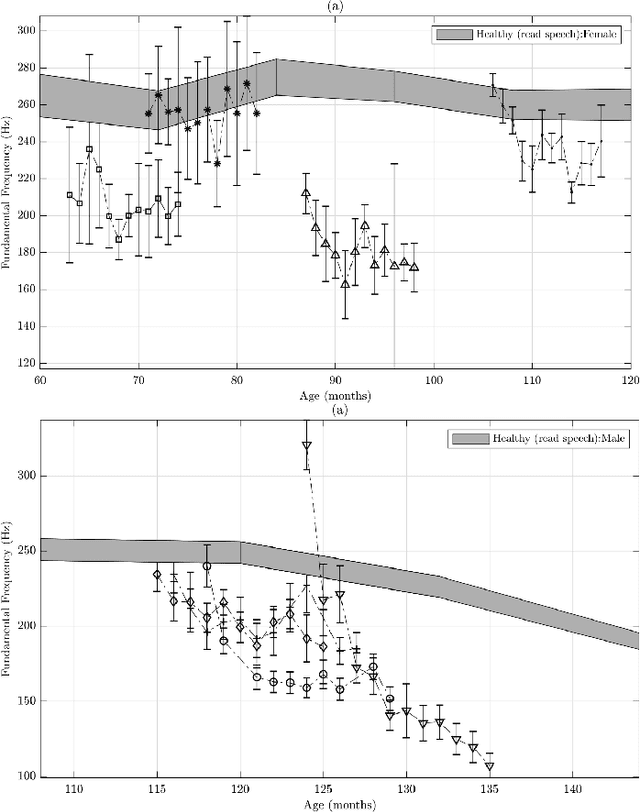
Recommendations for common outcome measures following pediatric traumatic brain injury (TBI) support the integration of instrumental measurements alongside perceptual assessment in recovery and treatment plans. A comprehensive set of sensitive, robust and non-invasive measurements is therefore essential in assessing variations in speech characteristics over time following pediatric TBI. In this article, we study the changes in the acoustic speech patterns of a pediatric cohort of ten subjects diagnosed with severe TBI. We extract a diverse set of both well-known and novel acoustic features from child speech recorded throughout the year after the child produced intelligible words. These features are analyzed individually and by speech subsystem, within-subject and across the cohort. As a group, older children exhibit highly significant (p<0.01) increases in pitch variation and phoneme diversity, shortened pause length, and steadying articulation rate variability. Younger children exhibit similar steadied rate variability alongside an increase in formant-based articulation complexity. Correlation analysis of the feature set with age and comparisons to normative developmental data confirm that age at injury plays a significant role in framing the recovery trajectory. Nearly all speech features significantly change (p<0.05) for the cohort as a whole, confirming that acoustic measures supplementing perceptual assessment are needed to identify efficacious treatment targets for speech therapy following TBI.
The Role of Voice Persona in Expressive Communication:An Argument for Relevance in Speech Synthesis Design
Sep 06, 2022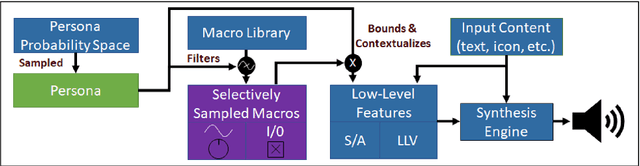
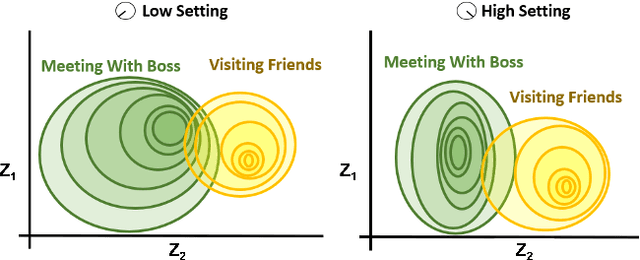
We present an approach to imbuing expressivity in a synthesized voice by acquiring a thematic analysis of 10 interviews with vocal studies and performance experts to inform the design framework for a real-time, interactive vocal persona that would generate compelling and appropriate contextually-dependent expression. The resultant tone of voice is defined as a point existing within a continuous, contextually-dependent probability space. The inclusion of voice persona in synthesized voice can be significant in a broad range of applications. Of particular interest is the potential impact in augmentative and assistive communication (AAC) community. Finally, we conclude with an introduction to our ongoing research investigating the themes of vocal persona and how they may continue to inform proposed expressive speech synthesis design frameworks.
HEAR 2021: Holistic Evaluation of Audio Representations
Mar 26, 2022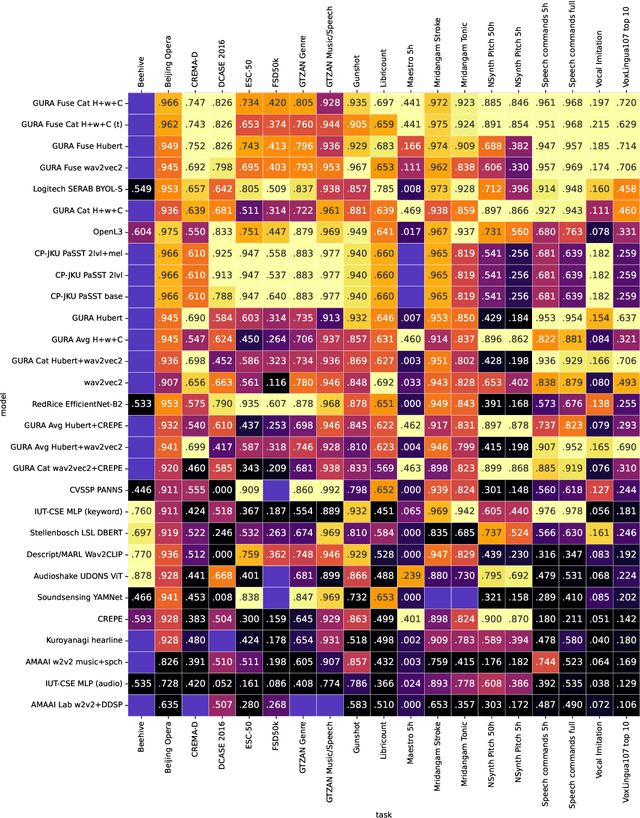
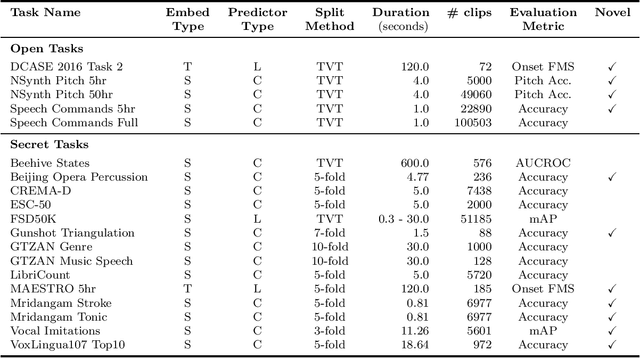

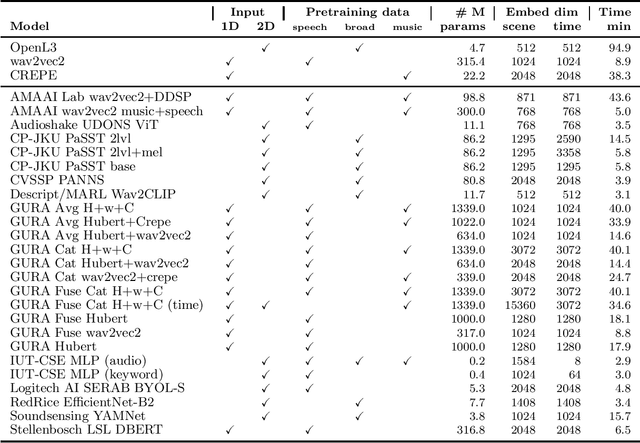
What audio embedding approach generalizes best to a wide range of downstream tasks across a variety of everyday domains without fine-tuning? The aim of the HEAR 2021 NeurIPS challenge is to develop a general-purpose audio representation that provides a strong basis for learning in a wide variety of tasks and scenarios. HEAR 2021 evaluates audio representations using a benchmark suite across a variety of domains, including speech, environmental sound, and music. In the spirit of shared exchange, each participant submitted an audio embedding model following a common API that is general-purpose, open-source, and freely available to use. Twenty-nine models by thirteen external teams were evaluated on nineteen diverse downstream tasks derived from sixteen datasets. Open evaluation code, submitted models and datasets are key contributions, enabling comprehensive and reproducible evaluation, as well as previously impossible longitudinal studies. It still remains an open question whether one single general-purpose audio representation can perform as holistically as the human ear.
Unsupervised Representation Learning For Context of Vocal Music
Jul 17, 2020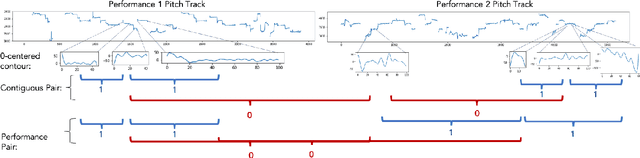


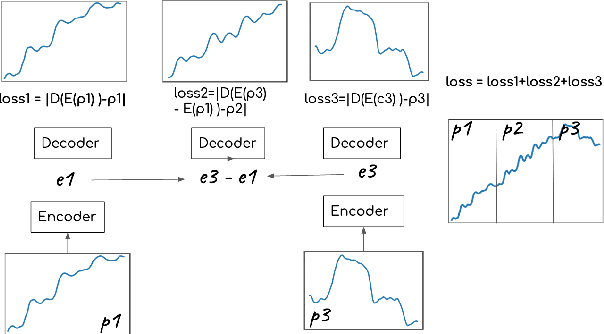
In this paper we aim to learn meaningful representations of sung intonation patterns derived from surrounding data without supervision. We focus on two facets of context in which a vocal line is produced: 1) within the short-time context of contiguous vocalizations, and 2) within the larger context of a recording. We propose two unsupervised deep learning methods, pseudo-task learning and slot filling, to produce latent encodings of these con-textual representations. To evaluate the quality of these representations and their usefulness as meaningful feature space, we conduct classification tasks on recordings sung by both professional and amateur singers. Initial results indicate that the learned representations enhance the performance of downstream classification tasks by several points, as compared to learning directly from the intonation contours alone. Larger increases in performance on classification of technique and vocal phrase patterns suggest that the representations encode short-time temporal context learned directly from the original recordings. Additionally, their ability to improve singer and gender identification suggest the learning of more broad contextual pat-terns. The growing availability of large unlabeled datasets makes this idea of contextual representation learning additionally promising, with larger amounts of meaningful samples often yielding better performance