 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHEAR 2021: Holistic Evaluation of Audio Representations
Mar 26, 2022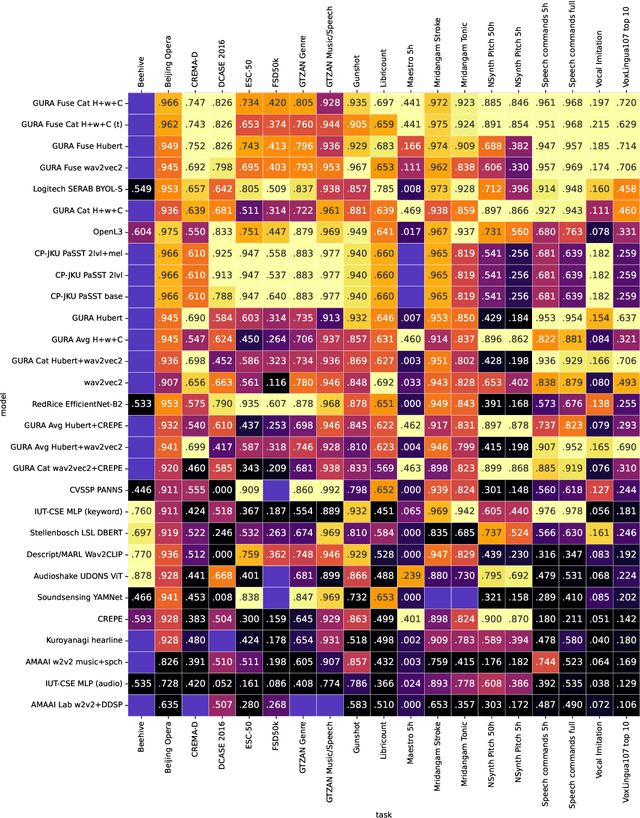
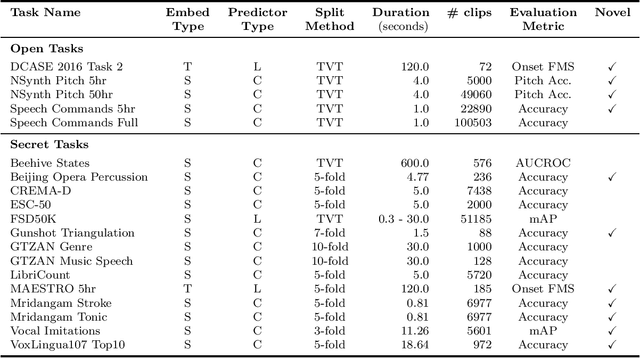

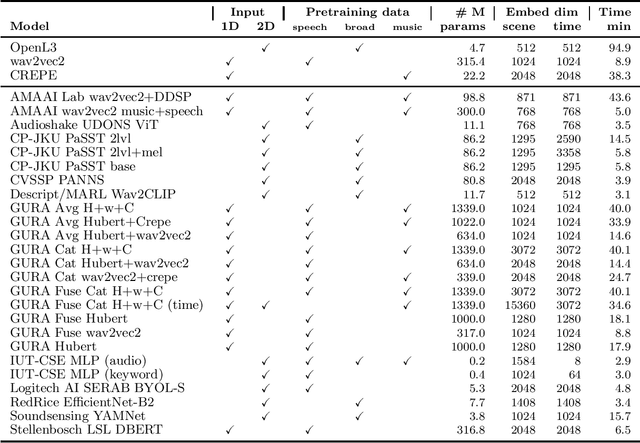
What audio embedding approach generalizes best to a wide range of downstream tasks across a variety of everyday domains without fine-tuning? The aim of the HEAR 2021 NeurIPS challenge is to develop a general-purpose audio representation that provides a strong basis for learning in a wide variety of tasks and scenarios. HEAR 2021 evaluates audio representations using a benchmark suite across a variety of domains, including speech, environmental sound, and music. In the spirit of shared exchange, each participant submitted an audio embedding model following a common API that is general-purpose, open-source, and freely available to use. Twenty-nine models by thirteen external teams were evaluated on nineteen diverse downstream tasks derived from sixteen datasets. Open evaluation code, submitted models and datasets are key contributions, enabling comprehensive and reproducible evaluation, as well as previously impossible longitudinal studies. It still remains an open question whether one single general-purpose audio representation can perform as holistically as the human ear.
Towards Developing a Multilingual and Code-Mixed Visual Question Answering System by Knowledge Distillation
Sep 10, 2021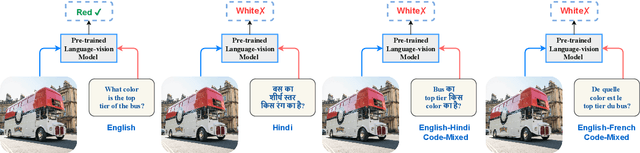
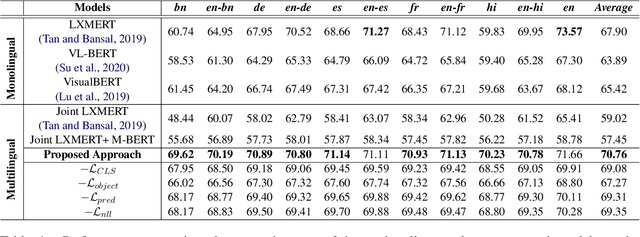
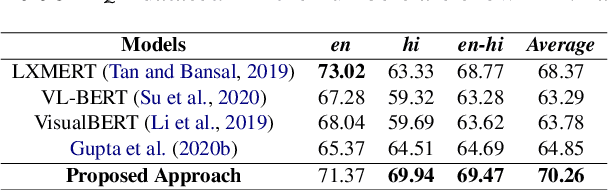
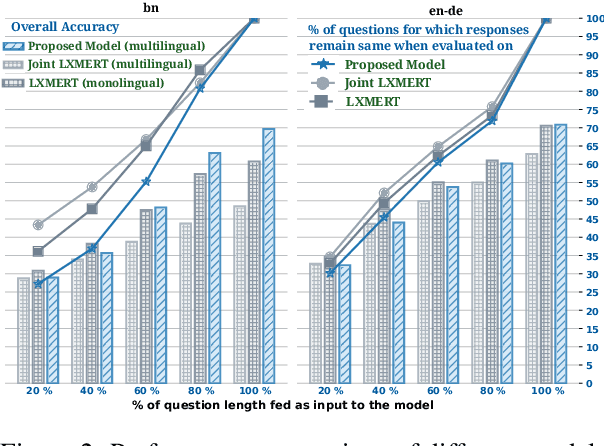
Pre-trained language-vision models have shown remarkable performance on the visual question answering (VQA) task. However, most pre-trained models are trained by only considering monolingual learning, especially the resource-rich language like English. Training such models for multilingual setups demand high computing resources and multilingual language-vision dataset which hinders their application in practice. To alleviate these challenges, we propose a knowledge distillation approach to extend an English language-vision model (teacher) into an equally effective multilingual and code-mixed model (student). Unlike the existing knowledge distillation methods, which only use the output from the last layer of the teacher network for distillation, our student model learns and imitates the teacher from multiple intermediate layers (language and vision encoders) with appropriately designed distillation objectives for incremental knowledge extraction. We also create the large-scale multilingual and code-mixed VQA dataset in eleven different language setups considering the multiple Indian and European languages. Experimental results and in-depth analysis show the effectiveness of the proposed VQA model over the pre-trained language-vision models on eleven diverse language setups.