 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCyber Security Data Science: Machine Learning Methods and their Performance on Imbalanced Datasets
May 07, 2025Cybersecurity has become essential worldwide and at all levels, concerning individuals, institutions, and governments. A basic principle in cybersecurity is to be always alert. Therefore, automation is imperative in processes where the volume of daily operations is large. Several cybersecurity applications can be addressed as binary classification problems, including anomaly detection, fraud detection, intrusion detection, spam detection, or malware detection. We present three experiments. In the first experiment, we evaluate single classifiers including Random Forests, Light Gradient Boosting Machine, eXtreme Gradient Boosting, Logistic Regression, Decision Tree, and Gradient Boosting Decision Tree. In the second experiment, we test different sampling techniques including over-sampling, under-sampling, Synthetic Minority Over-sampling Technique, and Self-Paced Ensembling. In the last experiment, we evaluate Self-Paced Ensembling and its number of base classifiers. We found that imbalance learning techniques had positive and negative effects, as reported in related studies. Thus, these techniques should be applied with caution. Besides, we found different best performers for each dataset. Therefore, we recommend testing single classifiers and imbalance learning techniques for each new dataset and application involving imbalanced datasets as is the case in several cyber security applications.
* 13 pages, 5 figures. Digital Management and Artificial Intelligence. Proceedings of the Fourth International Scientific-Practical Conference (ISPC 2024), Hybrid, October 10-11, 2024. https://link.springer.com/chapter/10.1007/978-3-031-88052-0_45
An approach to melodic segmentation and classification based on filtering with the Haar-wavelet
Apr 29, 2025We present a novel method of classification and segmentation of melodies in symbolic representation. The method is based on filtering pitch as a signal over time with the Haar-wavelet, and we evaluate it on two tasks. The filtered signal corresponds to a single-scale signal ws from the continuous Haar wavelet transform. The melodies are first segmented using local maxima or zero-crossings of w_s. The segments of w_s are then classified using the k-nearest neighbour algorithm with Euclidian and city-block distances. The method proves more effective than using unfiltered pitch signals and Gestalt-based segmentation when used to recognize the parent works of segments from Bach's Two-Part Inventions (BWV 772-786). When used to classify 360 Dutch folk tunes into 26 tune families, the performance of the method is comparable to the use of pitch signals, but not as good as that of string-matching methods based on multiple features.
Wavelet-Filtering of Symbolic Music Representations for Folk Tune Segmentation and Classification
Apr 29, 2025The aim of this study is to evaluate a machine-learning method in which symbolic representations of folk songs are segmented and classified into tune families with Haar-wavelet filtering. The method is compared with previously proposed Gestalt-based method. Melodies are represented as discrete symbolic pitch-time signals. We apply the continuous wavelet transform (CWT) with the Haar wavelet at specific scales, obtaining filtered versions of melodies emphasizing their information at particular time-scales. We use the filtered signal for representation and segmentation, using the wavelet coefficients' local maxima to indicate local boundaries and classify segments by means of k-nearest neighbours based on standard vector-metrics (Euclidean, cityblock), and compare the results to a Gestalt-based segmentation method and metrics applied directly to the pitch signal. We found that the wavelet based segmentation and wavelet-filtering of the pitch signal lead to better classification accuracy in cross-validated evaluation when the time-scale and other parameters are optimized.
Performance of Machine Learning Classifiers for Anomaly Detection in Cyber Security Applications
Apr 26, 2025This work empirically evaluates machine learning models on two imbalanced public datasets (KDDCUP99 and Credit Card Fraud 2013). The method includes data preparation, model training, and evaluation, using an 80/20 (train/test) split. Models tested include eXtreme Gradient Boosting (XGB), Multi Layer Perceptron (MLP), Generative Adversarial Network (GAN), Variational Autoencoder (VAE), and Multiple-Objective Generative Adversarial Active Learning (MO-GAAL), with XGB and MLP further combined with Random-Over-Sampling (ROS) and Self-Paced-Ensemble (SPE). Evaluation involves 5-fold cross-validation and imputation techniques (mean, median, and IterativeImputer) with 10, 20, 30, and 50 % missing data. Findings show XGB and MLP outperform generative models. IterativeImputer results are comparable to mean and median, but not recommended for large datasets due to increased complexity and execution time. The code used is publicly available on GitHub (github.com/markushaug/acr-25).
A Machine Learning Approach For Bitcoin Forecasting
Apr 25, 2025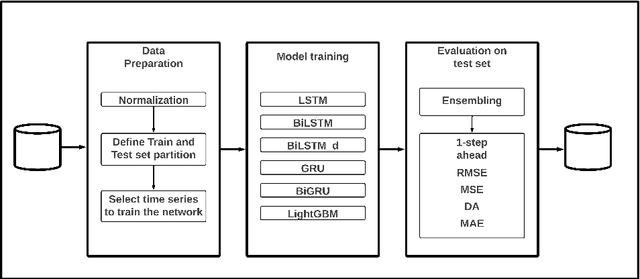

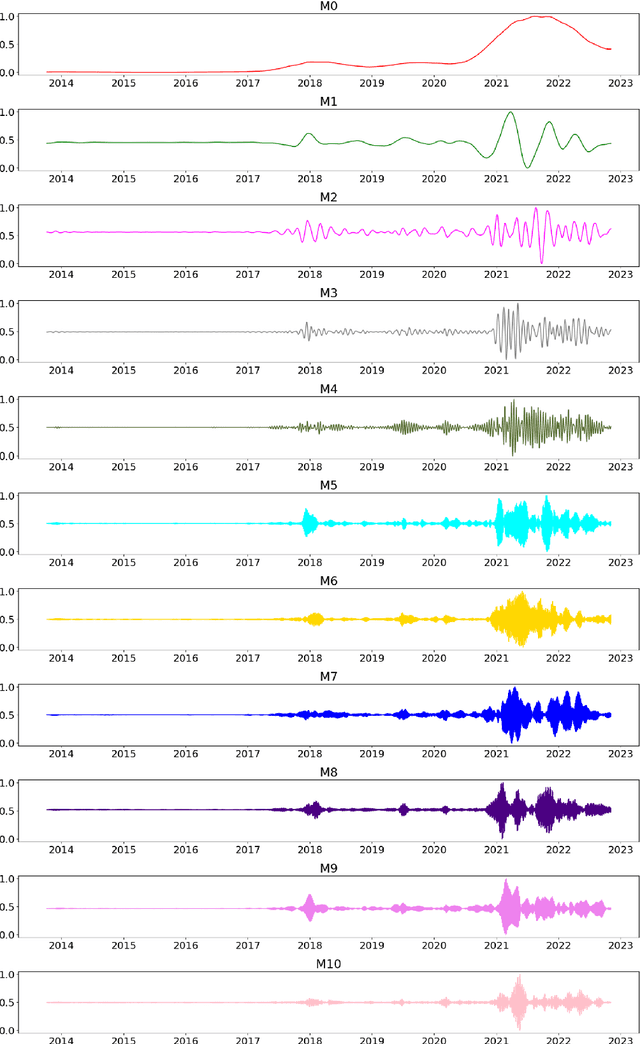
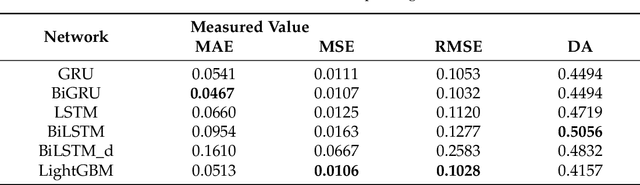
Bitcoin is one of the cryptocurrencies that is gaining more popularity in recent years. Previous studies have shown that closing price alone is not enough to forecast stock market series. We introduce a new set of time series and demonstrate that a subset is necessary to improve directional accuracy based on a machine learning ensemble. In our experiments, we study which time series and machine learning algorithms deliver the best results. We found that the most relevant time series that contribute to improving directional accuracy are Open, High and Low, with the largest contribution of Low in combination with an ensemble of Gated Recurrent Unit network and a baseline forecast. The relevance of other Bitcoin-related features that are not price-related is negligible. The proposed method delivers similar performance to the state-of-the-art when observing directional accuracy.
* 15 pages
Tree Boosting Methods for Balanced andImbalanced Classification and their Robustness Over Time in Risk Assessment
Apr 25, 2025
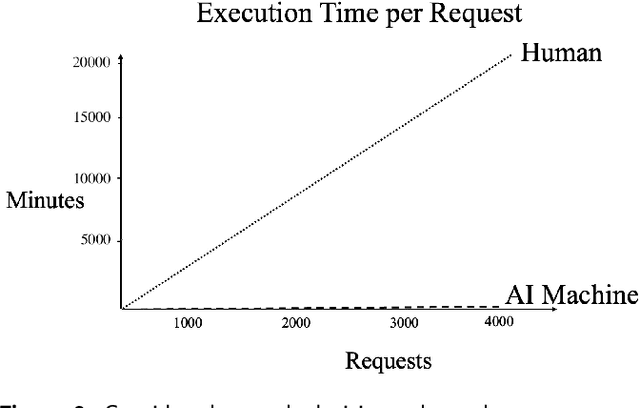
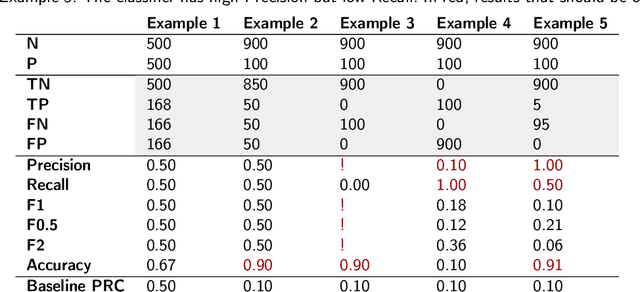
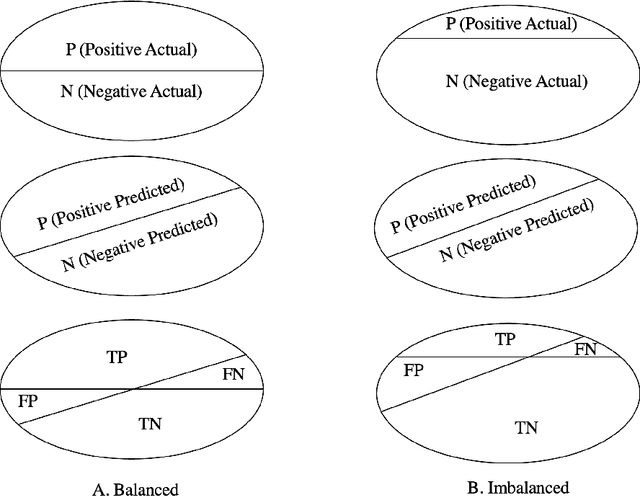
Most real-world classification problems deal with imbalanced datasets, posing a challenge for Artificial Intelligence (AI), i.e., machine learning algorithms, because the minority class, which is of extreme interest, often proves difficult to be detected. This paper empirically evaluates tree boosting methods' performance given different dataset sizes and class distributions, from perfectly balanced to highly imbalanced. For tabular data, tree-based methods such as XGBoost, stand out in several benchmarks due to detection performance and speed. Therefore, XGBoost and Imbalance-XGBoost are evaluated. After introducing the motivation to address risk assessment with machine learning, the paper reviews evaluation metrics for detection systems or binary classifiers. It proposes a method for data preparation followed by tree boosting methods including hyper-parameter optimization. The method is evaluated on private datasets of 1 thousand (K), 10K and 100K samples on distributions with 50, 45, 25, and 5 percent positive samples. As expected, the developed method increases its recognition performance as more data is given for training and the F1 score decreases as the data distribution becomes more imbalanced, but it is still significantly superior to the baseline of precision-recall determined by the ratio of positives divided by positives and negatives. Sampling to balance the training set does not provide consistent improvement and deteriorates detection. In contrast, classifier hyper-parameter optimization improves recognition, but should be applied carefully depending on data volume and distribution. Finally, the developed method is robust to data variation over time up to some point. Retraining can be used when performance starts deteriorating.
* 14 pages. arXiv admin note: text overlap with arXiv:2303.15218
An Open-Source and Reproducible Implementation of LSTM and GRU Networks for Time Series Forecasting
Apr 25, 2025This paper introduces an open-source and reproducible implementation of Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) Networks for time series forecasting. We evaluated LSTM and GRU networks because of their performance reported in related work. We describe our method and its results on two datasets. The first dataset is the S&P BSE BANKEX, composed of stock time series (closing prices) of ten financial institutions. The second dataset, called Activities, comprises ten synthetic time series resembling weekly activities with five days of high activity and two days of low activity. We report Root Mean Squared Error (RMSE) between actual and predicted values, as well as Directional Accuracy (DA). We show that a single time series from a dataset can be used to adequately train the networks if the sequences in the dataset contain patterns that repeat, even with certain variation, and are properly processed. For 1-step ahead and 20-step ahead forecasts, LSTM and GRU networks significantly outperform a baseline on the Activities dataset. The baseline simply repeats the last available value. On the stock market dataset, the networks perform just like the baseline, possibly due to the nature of these series. We release the datasets used as well as the implementation with all experiments performed to enable future comparisons and to make our research reproducible.
* 12 pages
Evaluating XGBoost for Balanced and Imbalanced Data: Application to Fraud Detection
Mar 27, 2023This paper evaluates XGboost's performance given different dataset sizes and class distributions, from perfectly balanced to highly imbalanced. XGBoost has been selected for evaluation, as it stands out in several benchmarks due to its detection performance and speed. After introducing the problem of fraud detection, the paper reviews evaluation metrics for detection systems or binary classifiers, and illustrates with examples how different metrics work for balanced and imbalanced datasets. Then, it examines the principles of XGBoost. It proposes a pipeline for data preparation and compares a Vanilla XGBoost against a random search-tuned XGBoost. Random search fine-tuning provides consistent improvement for large datasets of 100 thousand samples, not so for medium and small datasets of 10 and 1 thousand samples, respectively. Besides, as expected, XGBoost recognition performance improves as more data is available, and deteriorates detection performance as the datasets become more imbalanced. Tests on distributions with 50, 45, 25, and 5 percent positive samples show that the largest drop in detection performance occurs for the distribution with only 5 percent positive samples. Sampling to balance the training set does not provide consistent improvement. Therefore, future work will include a systematic study of different techniques to deal with data imbalance and evaluating other approaches, including graphs, autoencoders, and generative adversarial methods, to deal with the lack of labels.
Forecasting with Deep Learning
Feb 17, 2023This paper presents a method for time series forecasting with deep learning and its assessment on two datasets. The method starts with data preparation, followed by model training and evaluation. The final step is a visual inspection. Experimental work demonstrates that a single time series can be used to train deep learning networks if time series in a dataset contain patterns that repeat even with a certain variation. However, for less structured time series such as stock market closing prices, the networks perform just like a baseline that repeats the last observed value. The implementation of the method as well as the experiments are open-source.
Benchmarking Algorithms for Automatic License Plate Recognition
Mar 27, 2022
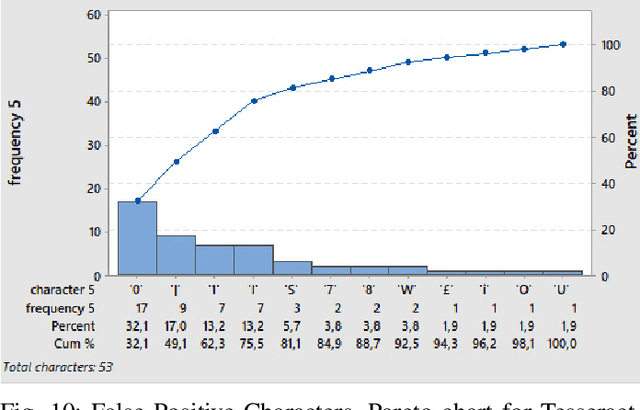
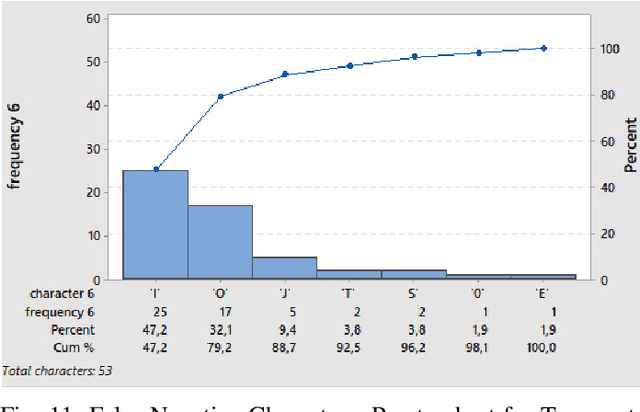

We evaluated a lightweight Convolutional Neural Network (CNN) called LPRNet [1] for automatic License Plate Recognition (LPR). We evaluated the algorithm on two datasets, one composed of real license plate images and the other of synthetic license plate images. In addition, we compared its performance against Tesseract [2], an Optical Character Recognition engine. We measured performance based on recognition accuracy and Levenshtein Distance. LPRNet is an end-to-end framework and demonstrated robust performance on both datasets, delivering 90 and 89 percent recognition accuracy on test sets of 1000 real and synthetic license plate images, respectively. Tesseract was not trained using real license plate images and performed well only on the synthetic dataset after pre-processing steps delivering 93 percent recognition accuracy. Finally, Pareto analysis for frequency analysis of misclassified characters allowed us to find in detail which characters were the most conflicting ones according to the percentage of accumulated error. Depending on the region, license plate images possess particular characteristics. Once properly trained, LPRNet can be used to recognize characters from a specific region and dataset. Future work can focus on applying transfer learning to utilize the features learned by LPRNet and fine-tune it given a smaller, newer dataset of license plates.