 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTree Boosting Methods for Balanced andImbalanced Classification and their Robustness Over Time in Risk Assessment
Apr 25, 2025
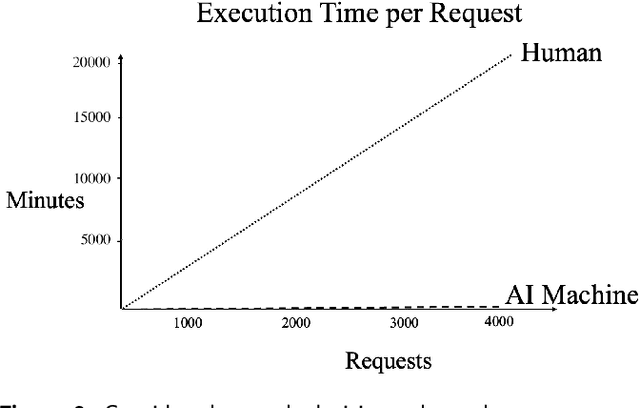
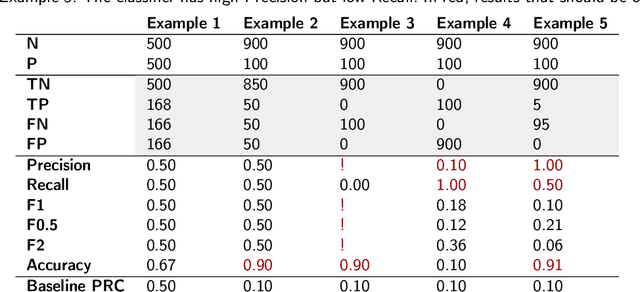
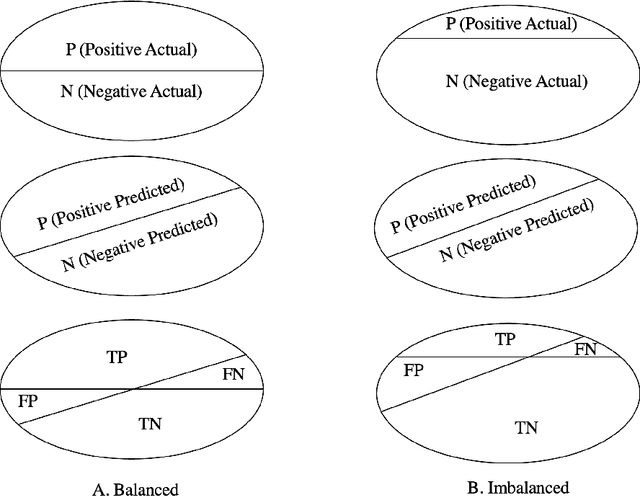
Most real-world classification problems deal with imbalanced datasets, posing a challenge for Artificial Intelligence (AI), i.e., machine learning algorithms, because the minority class, which is of extreme interest, often proves difficult to be detected. This paper empirically evaluates tree boosting methods' performance given different dataset sizes and class distributions, from perfectly balanced to highly imbalanced. For tabular data, tree-based methods such as XGBoost, stand out in several benchmarks due to detection performance and speed. Therefore, XGBoost and Imbalance-XGBoost are evaluated. After introducing the motivation to address risk assessment with machine learning, the paper reviews evaluation metrics for detection systems or binary classifiers. It proposes a method for data preparation followed by tree boosting methods including hyper-parameter optimization. The method is evaluated on private datasets of 1 thousand (K), 10K and 100K samples on distributions with 50, 45, 25, and 5 percent positive samples. As expected, the developed method increases its recognition performance as more data is given for training and the F1 score decreases as the data distribution becomes more imbalanced, but it is still significantly superior to the baseline of precision-recall determined by the ratio of positives divided by positives and negatives. Sampling to balance the training set does not provide consistent improvement and deteriorates detection. In contrast, classifier hyper-parameter optimization improves recognition, but should be applied carefully depending on data volume and distribution. Finally, the developed method is robust to data variation over time up to some point. Retraining can be used when performance starts deteriorating.
* 14 pages. arXiv admin note: text overlap with arXiv:2303.15218
Evaluating XGBoost for Balanced and Imbalanced Data: Application to Fraud Detection
Mar 27, 2023This paper evaluates XGboost's performance given different dataset sizes and class distributions, from perfectly balanced to highly imbalanced. XGBoost has been selected for evaluation, as it stands out in several benchmarks due to its detection performance and speed. After introducing the problem of fraud detection, the paper reviews evaluation metrics for detection systems or binary classifiers, and illustrates with examples how different metrics work for balanced and imbalanced datasets. Then, it examines the principles of XGBoost. It proposes a pipeline for data preparation and compares a Vanilla XGBoost against a random search-tuned XGBoost. Random search fine-tuning provides consistent improvement for large datasets of 100 thousand samples, not so for medium and small datasets of 10 and 1 thousand samples, respectively. Besides, as expected, XGBoost recognition performance improves as more data is available, and deteriorates detection performance as the datasets become more imbalanced. Tests on distributions with 50, 45, 25, and 5 percent positive samples show that the largest drop in detection performance occurs for the distribution with only 5 percent positive samples. Sampling to balance the training set does not provide consistent improvement. Therefore, future work will include a systematic study of different techniques to deal with data imbalance and evaluating other approaches, including graphs, autoencoders, and generative adversarial methods, to deal with the lack of labels.
EEG aided boosting of single-lead ECG based sleep staging with Deep Knowledge Distillation
Nov 18, 2022



An electroencephalogram (EEG) signal is currently accepted as a standard for automatic sleep staging. Lately, Near-human accuracy in automated sleep staging has been achievable by Deep Learning (DL) based approaches, enabling multi-fold progress in this area. However, An extensive and expensive clinical setup is required for EEG based sleep staging. Additionally, the EEG setup being obtrusive in nature and requiring an expert for setup adds to the inconvenience of the subject under study, making it adverse in the point of care setting. An unobtrusive and more suitable alternative to EEG is Electrocardiogram (ECG). Unsurprisingly, compared to EEG in sleep staging, its performance remains sub-par. In order to take advantage of both the modalities, transferring knowledge from EEG to ECG is a reasonable approach, ultimately boosting the performance of ECG based sleep staging. Knowledge Distillation (KD) is a promising notion in DL that shares knowledge from a superior performing but usually more complex teacher model to an inferior but compact student model. Building upon this concept, a cross-modality KD framework assisting features learned through models trained on EEG to improve ECG-based sleep staging performance is proposed. Additionally, to better understand the distillation approach, extensive experimentation on the independent modules of the proposed model was conducted. Montreal Archive of Sleep Studies (MASS) dataset consisting of 200 subjects was utilized for this study. The results from the proposed model for weighted-F1-score in 3-class and 4-class sleep staging showed a 13.40 \% and 14.30 \% improvement, respectively. This study demonstrates the feasibility of KD for single-channel ECG based sleep staging's performance enhancement in 3-class (W-R-N) and 4-class (W-R-L-D) classification.
A Deep Knowledge Distillation framework for EEG assisted enhancement of single-lead ECG based sleep staging
Dec 14, 2021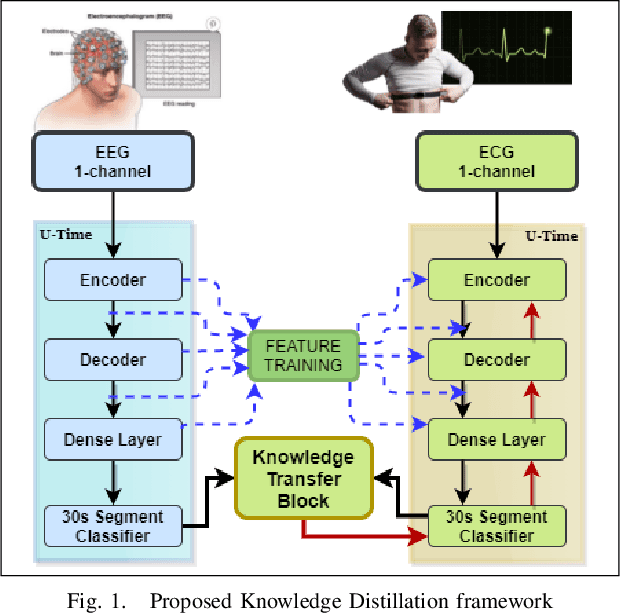
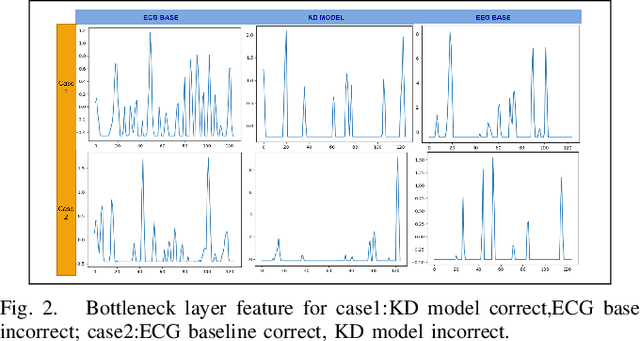

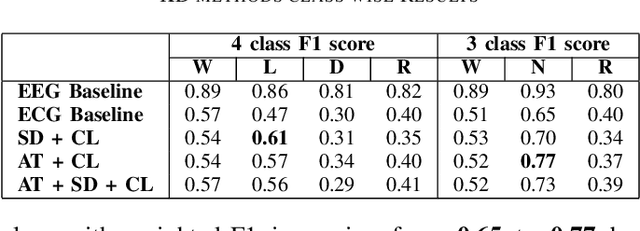
Automatic Sleep Staging study is presently done with the help of Electroencephalogram (EEG) signals. Recently, Deep Learning (DL) based approaches have enabled significant progress in this area, allowing for near-human accuracy in automated sleep staging. However, EEG based sleep staging requires an extensive as well as an expensive clinical setup. Moreover, the requirement of an expert for setup and the added inconvenience to the subject under study renders it unfavourable in a point of care context. Electrocardiogram (ECG), an unobtrusive alternative to EEG, is more suitable, but its performance, unsurprisingly, remains sub-par compared to EEG-based sleep staging. Naturally, it would be helpful to transfer knowledge from EEG to ECG, ultimately enhancing the model's performance on ECG based inputs. Knowledge Distillation (KD) is a renowned concept in DL that looks to transfer knowledge from a better but potentially more cumbersome teacher model to a compact student model. Building on this concept, we propose a cross-modal KD framework to improve ECG-based sleep staging performance with assistance from features learned through models trained on EEG. Additionally, we also conducted multiple experiments on the individual components of the proposed model to get better insight into the distillation approach. Data of 200 subjects from the Montreal Archive of Sleep Studies (MASS) was utilized for our study. The proposed model showed a 14.3\% and 13.4\% increase in weighted-F1-score in 4-class and 3-class sleep staging, respectively. This demonstrates the viability of KD for performance improvement of single-channel ECG based sleep staging in 4-class(W-L-D-R) and 3-class(W-N-R) classification.