 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA deep cascade of ensemble of dual domain networks with gradient-based T1 assistance and perceptual refinement for fast MRI reconstruction
Jul 05, 2022
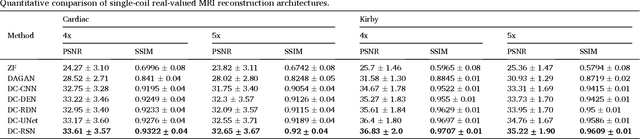
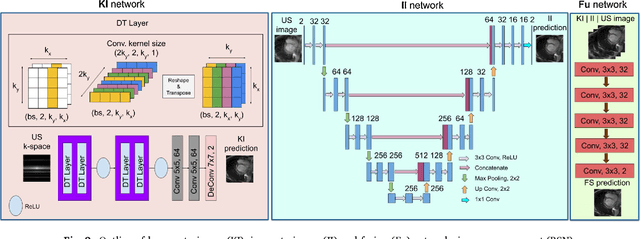
Deep learning networks have shown promising results in fast magnetic resonance imaging (MRI) reconstruction. In our work, we develop deep networks to further improve the quantitative and the perceptual quality of reconstruction. To begin with, we propose reconsynergynet (RSN), a network that combines the complementary benefits of independently operating on both the image and the Fourier domain. For a single-coil acquisition, we introduce deep cascade RSN (DC-RSN), a cascade of RSN blocks interleaved with data fidelity (DF) units. Secondly, we improve the structure recovery of DC-RSN for T2 weighted Imaging (T2WI) through assistance of T1 weighted imaging (T1WI), a sequence with short acquisition time. T1 assistance is provided to DC-RSN through a gradient of log feature (GOLF) fusion. Furthermore, we propose perceptual refinement network (PRN) to refine the reconstructions for better visual information fidelity (VIF), a metric highly correlated to radiologists opinion on the image quality. Lastly, for multi-coil acquisition, we propose variable splitting RSN (VS-RSN), a deep cascade of blocks, each block containing RSN, multi-coil DF unit, and a weighted average module. We extensively validate our models DC-RSN and VS-RSN for single-coil and multi-coil acquisitions and report the state-of-the-art performance. We obtain a SSIM of 0.768, 0.923, 0.878 for knee single-coil-4x, multi-coil-4x, and multi-coil-8x in fastMRI. We also conduct experiments to demonstrate the efficacy of GOLF based T1 assistance and PRN.
A Deep Knowledge Distillation framework for EEG assisted enhancement of single-lead ECG based sleep staging
Dec 14, 2021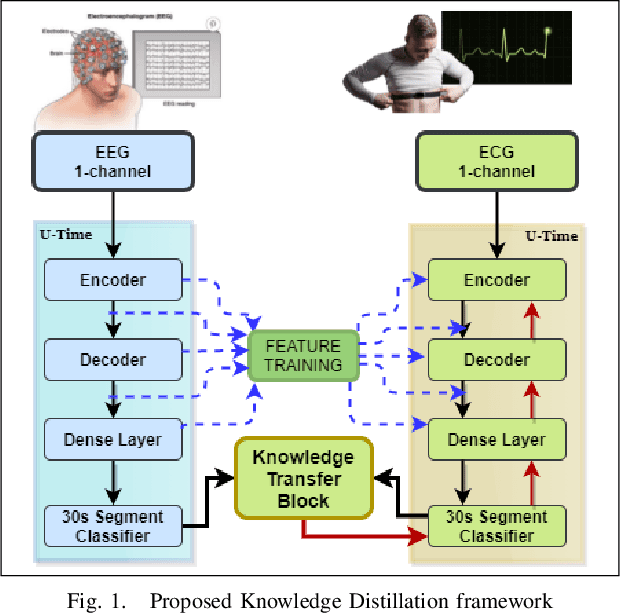
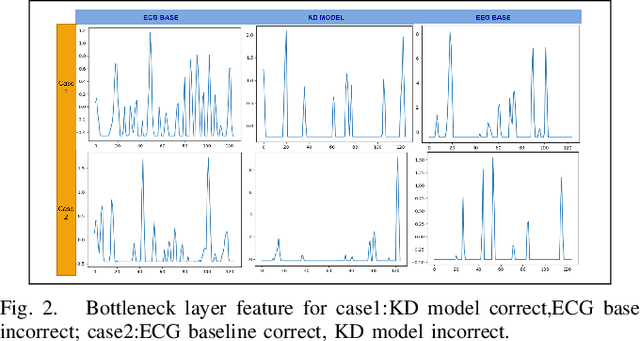

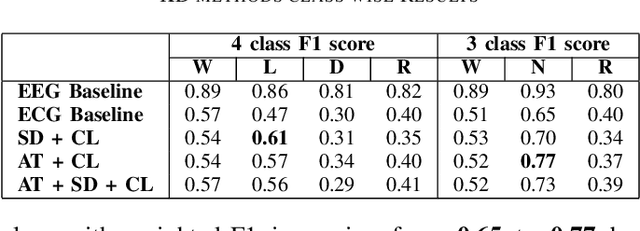
Automatic Sleep Staging study is presently done with the help of Electroencephalogram (EEG) signals. Recently, Deep Learning (DL) based approaches have enabled significant progress in this area, allowing for near-human accuracy in automated sleep staging. However, EEG based sleep staging requires an extensive as well as an expensive clinical setup. Moreover, the requirement of an expert for setup and the added inconvenience to the subject under study renders it unfavourable in a point of care context. Electrocardiogram (ECG), an unobtrusive alternative to EEG, is more suitable, but its performance, unsurprisingly, remains sub-par compared to EEG-based sleep staging. Naturally, it would be helpful to transfer knowledge from EEG to ECG, ultimately enhancing the model's performance on ECG based inputs. Knowledge Distillation (KD) is a renowned concept in DL that looks to transfer knowledge from a better but potentially more cumbersome teacher model to a compact student model. Building on this concept, we propose a cross-modal KD framework to improve ECG-based sleep staging performance with assistance from features learned through models trained on EEG. Additionally, we also conducted multiple experiments on the individual components of the proposed model to get better insight into the distillation approach. Data of 200 subjects from the Montreal Archive of Sleep Studies (MASS) was utilized for our study. The proposed model showed a 14.3\% and 13.4\% increase in weighted-F1-score in 4-class and 3-class sleep staging, respectively. This demonstrates the viability of KD for performance improvement of single-channel ECG based sleep staging in 4-class(W-L-D-R) and 3-class(W-N-R) classification.
A Deep Learning Based Multitask Network for Respiration Rate Estimation -- A Practical Perspective
Dec 13, 2021
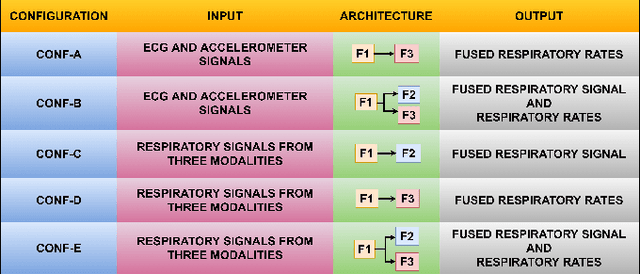
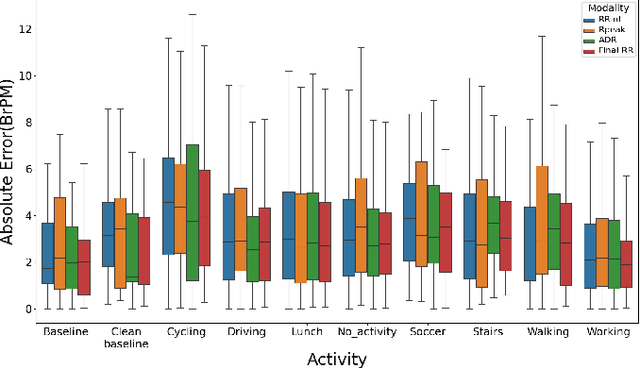
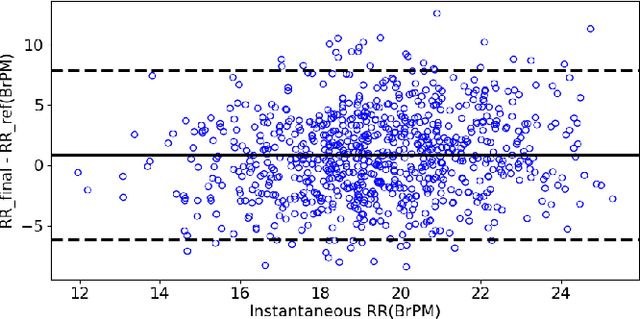
The exponential rise in wearable sensors has garnered significant interest in assessing the physiological parameters during day-to-day activities. Respiration rate is one of the vital parameters used in the performance assessment of lifestyle activities. However, obtrusive setup for measurement, motion artifacts, and other noises complicate the process. This paper presents a multitasking architecture based on Deep Learning (DL) for estimating instantaneous and average respiration rate from ECG and accelerometer signals, such that it performs efficiently under daily living activities like cycling, walking, etc. The multitasking network consists of a combination of Encoder-Decoder and Encoder-IncResNet, to fetch the average respiration rate and the respiration signal. The respiration signal can be leveraged to obtain the breathing peaks and instantaneous breathing cycles. Mean absolute error(MAE), Root mean square error (RMSE), inference time, and parameter count analysis has been used to compare the network with the current state of art Machine Learning (ML) model and other DL models developed in previous studies. Other DL configurations based on a variety of inputs are also developed as a part of the work. The proposed model showed better overall accuracy and gave better results than individual modalities during different activities.
RPnet: A Deep Learning approach for robust R Peak detection in noisy ECG
Apr 17, 2020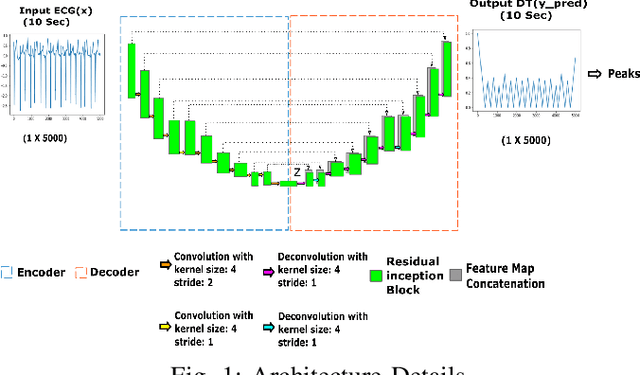
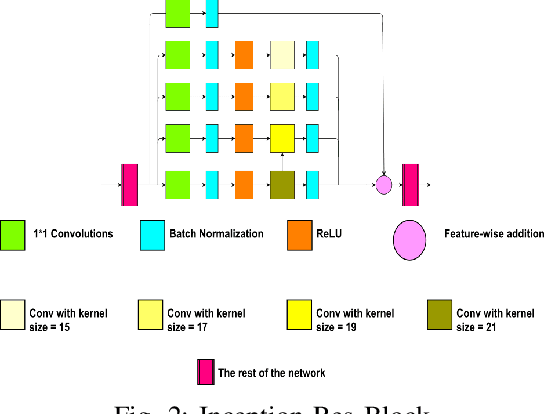
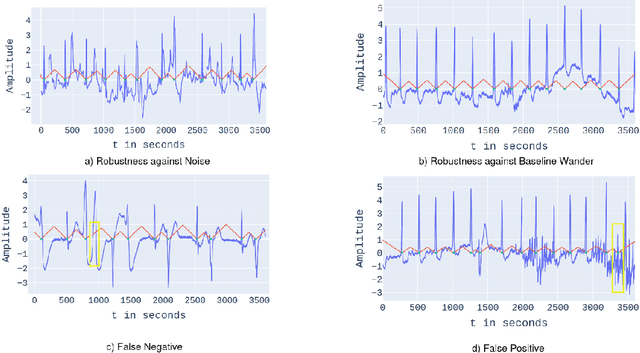
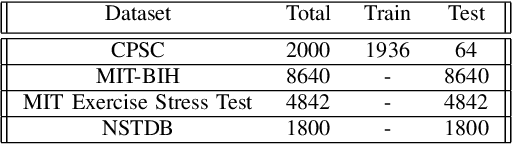
Automatic detection of R-peaks in an Electrocardiogram signal is crucial in a multitude of applications including Heart Rate Variability (HRV) analysis and Cardio Vascular Disease(CVD) diagnosis. Although there have been numerous approaches that have successfully addressed the problem, there has been a notable dip in the performance of these existing detectors on ECG episodes that contain noise and HRV Irregulates. On the other hand, Deep Learning(DL) based methods have shown to be adept at modelling data that contain noise. In image to image translation, Unet is the fundamental block in many of the networks. In this work, a novel application of the Unet combined with Inception and Residual blocks is proposed to perform the extraction of R-peaks from an ECG. Furthermore, the problem formulation also robustly deals with issues of variability and sparsity of ECG R-peaks. The proposed network was trained on a database containing ECG episodes that have CVD and was tested against three traditional ECG detectors on a validation set. The model achieved an F1 score of 0.9837, which is a substantial improvement over the other beat detectors. Furthermore, the model was also evaluated on three other databases. The proposed network achieved high F1 scores across all datasets which established its generalizing capacity. Additionally, a thorough analysis of the model's performance in the presence of different levels of noise was carried out.
Robust Modelling of Reflectance Pulse Oximetry for SpO$_2$ Estimation
Apr 14, 2020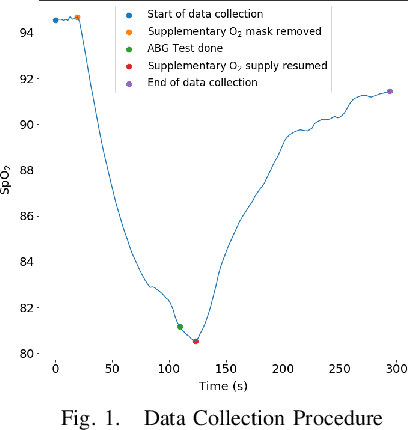
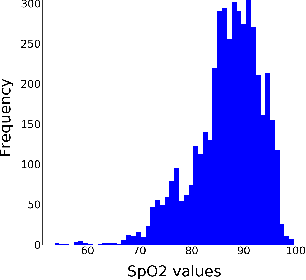
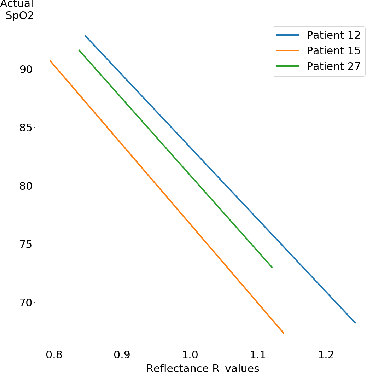
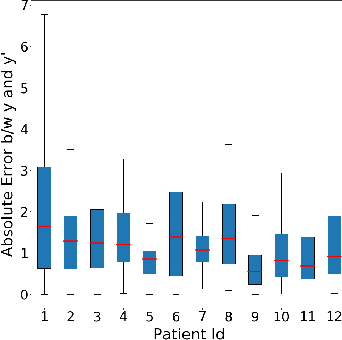
Continuous monitoring of blood oxygen saturation levels is vital for patients with pulmonary disorders. Traditionally, SpO$_2$ monitoring has been carried out using transmittance pulse oximeters due to its dependability. However, SpO$_2$ measurement from transmittance pulse oximeters is limited to peripheral regions. This becomes a disadvantage at very low temperatures as blood perfusion to the peripherals decreases. On the other hand, reflectance pulse oximeters can be used at various sites like finger, wrist, chest and forehead. Additionally, reflectance pulse oximeters can be scaled down to affordable patches that do not interfere with the user's diurnal activities. However, accurate SpO$_2$ estimation from reflectance pulse oximeters is challenging due to its patient dependent, subjective nature of measurement. Recently, a Machine Learning (ML) method was used to model reflectance waveforms onto SpO$_2$ obtained from transmittance waveforms. However, the generalizability of the model to new patients was not tested. In light of this, the current work implemented multiple ML based approaches which were subsequently found to be incapable of generalizing to new patients. Furthermore, a minimally calibrated data driven approach was utilized in order to obtain SpO$_2$ from reflectance PPG waveforms. The proposed solution produces an average mean absolute error of 1.81\% on unseen patients which is well within the clinically permissible error of 2\%. Two statistical tests were conducted to establish the effectiveness of the proposed method.
Interpreting Deep Neural Networks for Single-Lead ECG Arrhythmia Classification
Apr 11, 2020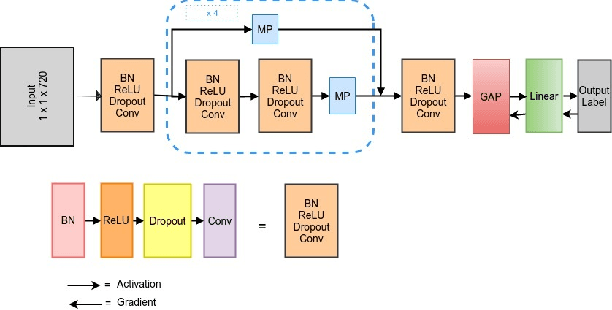
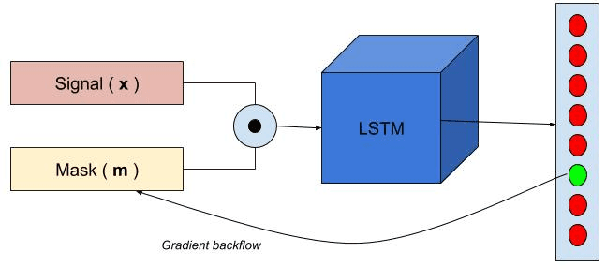
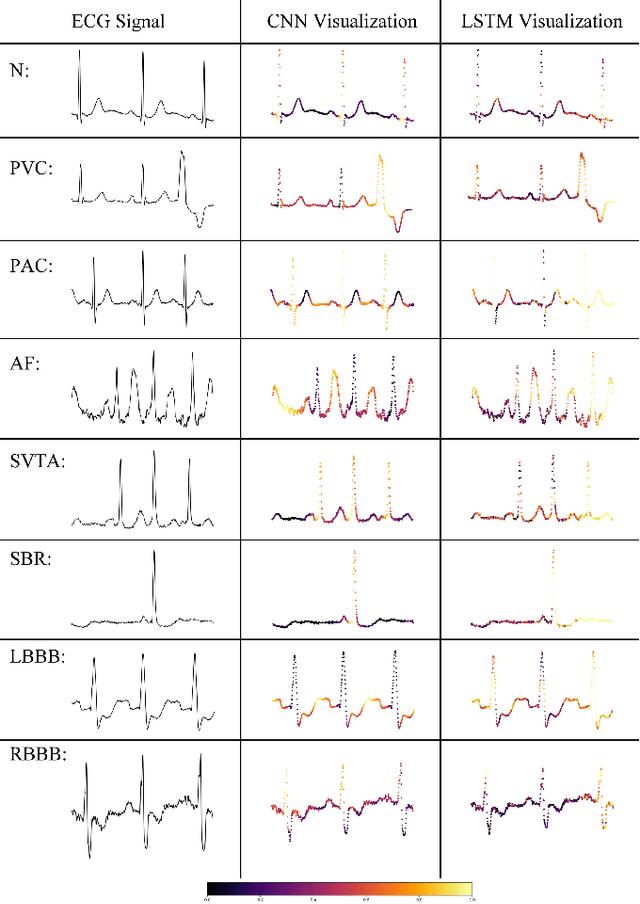
Cardiac arrhythmia is a prevalent and significant cause of morbidity and mortality among cardiac ailments. Early diagnosis is crucial in providing intervention for patients suffering from cardiac arrhythmia. Traditionally, diagnosis is performed by examination of the Electrocardiogram (ECG) by a cardiologist. This method of diagnosis is hampered by the lack of accessibility to expert cardiologists. For quite some time, signal processing methods had been used to automate arrhythmia diagnosis. However, these traditional methods require expert knowledge and are unable to model a wide range of arrhythmia. Recently, Deep Learning methods have provided solutions to performing arrhythmia diagnosis at scale. However, the black-box nature of these models prohibit clinical interpretation of cardiac arrhythmia. There is a dire need to correlate the obtained model outputs to the corresponding segments of the ECG. To this end, two methods are proposed to provide interpretability to the models. The first method is a novel application of Gradient-weighted Class Activation Map (Grad-CAM) for visualizing the saliency of the CNN model. In the second approach, saliency is derived by learning the input deletion mask for the LSTM model. The visualizations are provided on a model whose competence is established by comparisons against baselines. The results of model saliency not only provide insight into the prediction capability of the model but also aligns with the medical literature for the classification of cardiac arrhythmia.
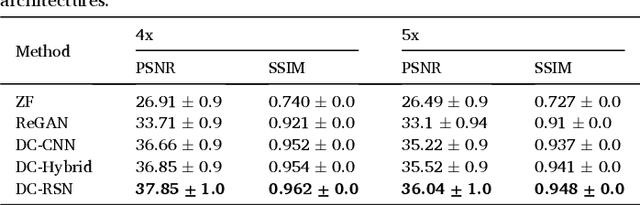
KD-MRI: A knowledge distillation framework for image reconstruction and image restoration in MRI workflow
Apr 11, 2020
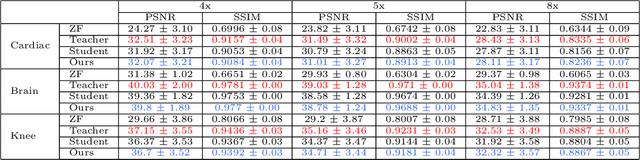
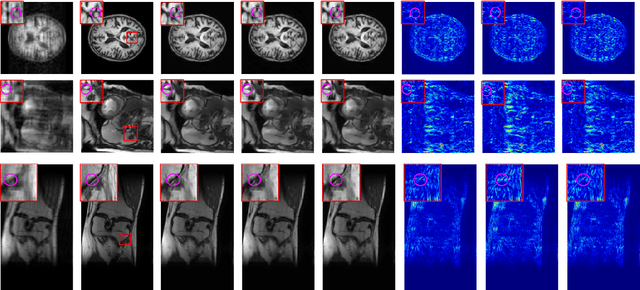
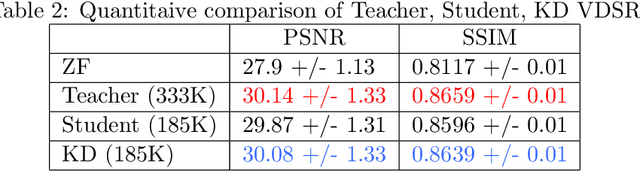
Deep learning networks are being developed in every stage of the MRI workflow and have provided state-of-the-art results. However, this has come at the cost of increased computation requirement and storage. Hence, replacing the networks with compact models at various stages in the MRI workflow can significantly reduce the required storage space and provide considerable speedup. In computer vision, knowledge distillation is a commonly used method for model compression. In our work, we propose a knowledge distillation (KD) framework for the image to image problems in the MRI workflow in order to develop compact, low-parameter models without a significant drop in performance. We propose a combination of the attention-based feature distillation method and imitation loss and demonstrate its effectiveness on the popular MRI reconstruction architecture, DC-CNN. We conduct extensive experiments using Cardiac, Brain, and Knee MRI datasets for 4x, 5x and 8x accelerations. We observed that the student network trained with the assistance of the teacher using our proposed KD framework provided significant improvement over the student network trained without assistance across all the datasets and acceleration factors. Specifically, for the Knee dataset, the student network achieves $65\%$ parameter reduction, 2x faster CPU running time, and 1.5x faster GPU running time compared to the teacher. Furthermore, we compare our attention-based feature distillation method with other feature distillation methods. We also conduct an ablative study to understand the significance of attention-based distillation and imitation loss. We also extend our KD framework for MRI super-resolution and show encouraging results.