 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKD-MRI: A knowledge distillation framework for image reconstruction and image restoration in MRI workflow
Paper and Code

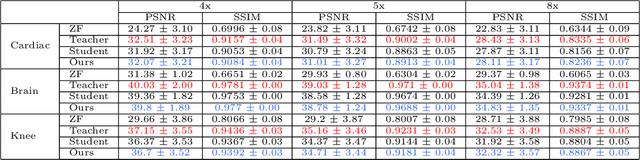
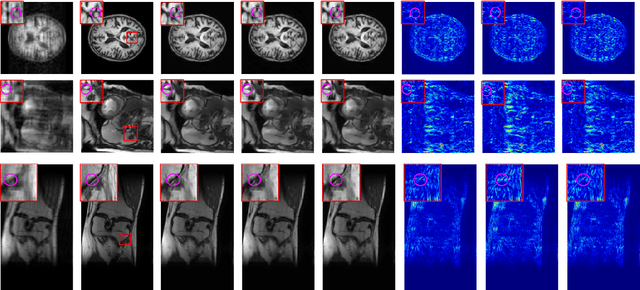
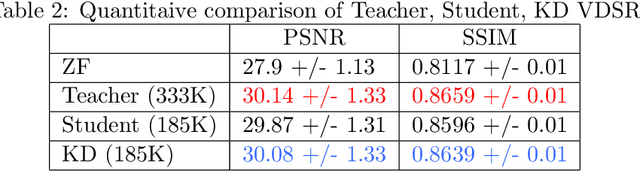
Deep learning networks are being developed in every stage of the MRI workflow and have provided state-of-the-art results. However, this has come at the cost of increased computation requirement and storage. Hence, replacing the networks with compact models at various stages in the MRI workflow can significantly reduce the required storage space and provide considerable speedup. In computer vision, knowledge distillation is a commonly used method for model compression. In our work, we propose a knowledge distillation (KD) framework for the image to image problems in the MRI workflow in order to develop compact, low-parameter models without a significant drop in performance. We propose a combination of the attention-based feature distillation method and imitation loss and demonstrate its effectiveness on the popular MRI reconstruction architecture, DC-CNN. We conduct extensive experiments using Cardiac, Brain, and Knee MRI datasets for 4x, 5x and 8x accelerations. We observed that the student network trained with the assistance of the teacher using our proposed KD framework provided significant improvement over the student network trained without assistance across all the datasets and acceleration factors. Specifically, for the Knee dataset, the student network achieves $65\%$ parameter reduction, 2x faster CPU running time, and 1.5x faster GPU running time compared to the teacher. Furthermore, we compare our attention-based feature distillation method with other feature distillation methods. We also conduct an ablative study to understand the significance of attention-based distillation and imitation loss. We also extend our KD framework for MRI super-resolution and show encouraging results.