 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKD-MRI: A knowledge distillation framework for image reconstruction and image restoration in MRI workflow
Apr 11, 2020
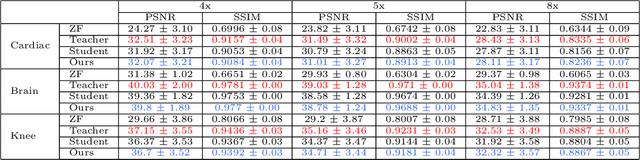
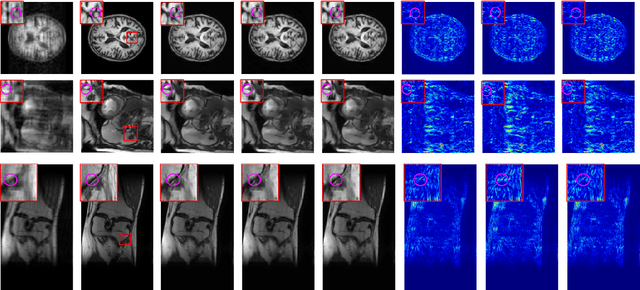
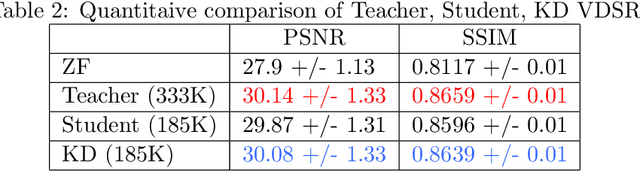
Deep learning networks are being developed in every stage of the MRI workflow and have provided state-of-the-art results. However, this has come at the cost of increased computation requirement and storage. Hence, replacing the networks with compact models at various stages in the MRI workflow can significantly reduce the required storage space and provide considerable speedup. In computer vision, knowledge distillation is a commonly used method for model compression. In our work, we propose a knowledge distillation (KD) framework for the image to image problems in the MRI workflow in order to develop compact, low-parameter models without a significant drop in performance. We propose a combination of the attention-based feature distillation method and imitation loss and demonstrate its effectiveness on the popular MRI reconstruction architecture, DC-CNN. We conduct extensive experiments using Cardiac, Brain, and Knee MRI datasets for 4x, 5x and 8x accelerations. We observed that the student network trained with the assistance of the teacher using our proposed KD framework provided significant improvement over the student network trained without assistance across all the datasets and acceleration factors. Specifically, for the Knee dataset, the student network achieves $65\%$ parameter reduction, 2x faster CPU running time, and 1.5x faster GPU running time compared to the teacher. Furthermore, we compare our attention-based feature distillation method with other feature distillation methods. We also conduct an ablative study to understand the significance of attention-based distillation and imitation loss. We also extend our KD framework for MRI super-resolution and show encouraging results.
A context based deep learning approach for unbalanced medical image segmentation
Jan 08, 2020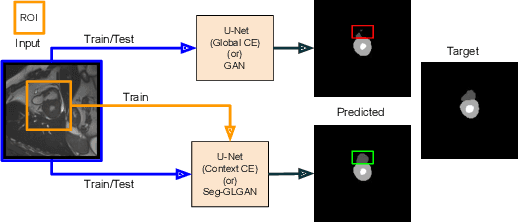
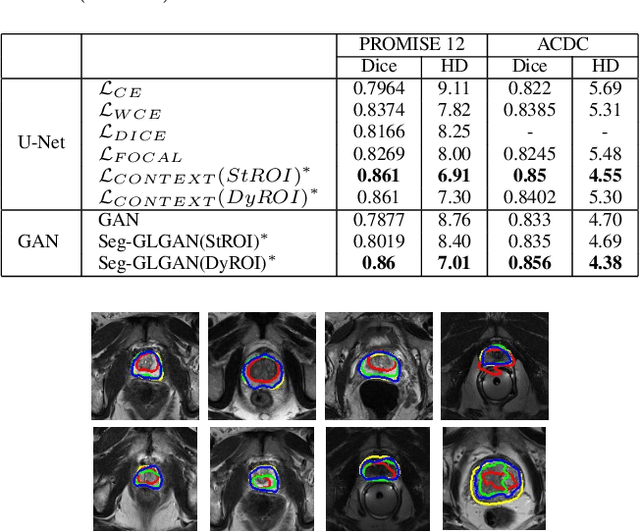
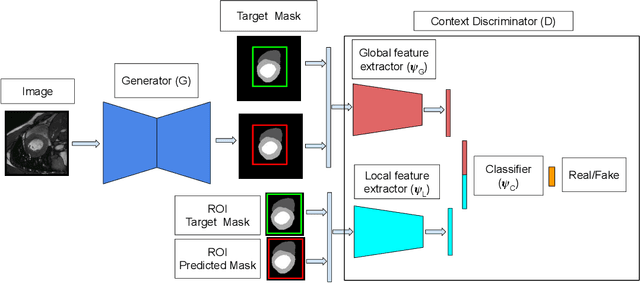

Automated medical image segmentation is an important step in many medical procedures. Recently, deep learning networks have been widely used for various medical image segmentation tasks, with U-Net and generative adversarial nets (GANs) being some of the commonly used ones. Foreground-background class imbalance is a common occurrence in medical images, and U-Net has difficulty in handling class imbalance because of its cross entropy (CE) objective function. Similarly, GAN also suffers from class imbalance because the discriminator looks at the entire image to classify it as real or fake. Since the discriminator is essentially a deep learning classifier, it is incapable of correctly identifying minor changes in small structures. To address these issues, we propose a novel context based CE loss function for U-Net, and a novel architecture Seg-GLGAN. The context based CE is a linear combination of CE obtained over the entire image and its region of interest (ROI). In Seg-GLGAN, we introduce a novel context discriminator to which the entire image and its ROI are fed as input, thus enforcing local context. We conduct extensive experiments using two challenging unbalanced datasets: PROMISE12 and ACDC. We observe that segmentation results obtained from our methods give better segmentation metrics as compared to various baseline methods.
Recon-GLGAN: A Global-Local context based Generative Adversarial Network for MRI Reconstruction
Aug 25, 2019
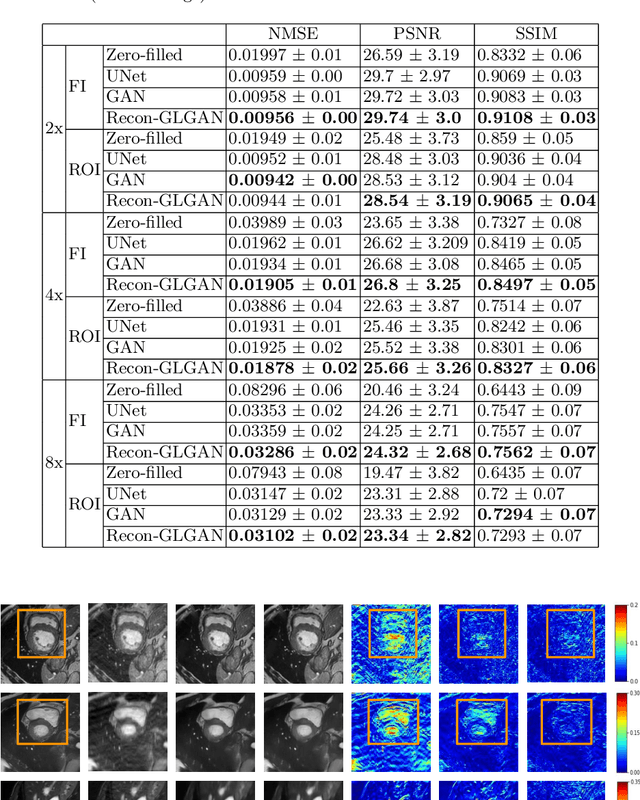

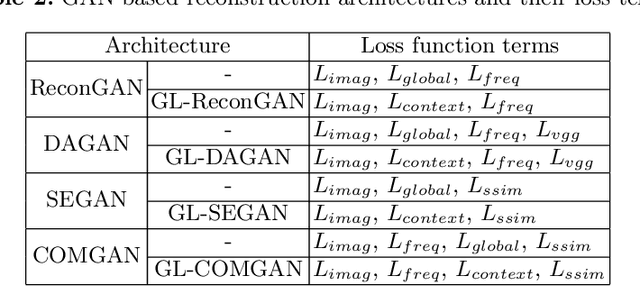
Magnetic resonance imaging (MRI) is one of the best medical imaging modalities as it offers excellent spatial resolution and soft-tissue contrast. But, the usage of MRI is limited by its slow acquisition time, which makes it expensive and causes patient discomfort. In order to accelerate the acquisition, multiple deep learning networks have been proposed. Recently, Generative Adversarial Networks (GANs) have shown promising results in MRI reconstruction. The drawback with the proposed GAN based methods is it does not incorporate the prior information about the end goal which could help in better reconstruction. For instance, in the case of cardiac MRI, the physician would be interested in the heart region which is of diagnostic relevance while excluding the peripheral regions. In this work, we show that incorporating prior information about a region of interest in the model would offer better performance. Thereby, we propose a novel GAN based architecture, Reconstruction Global-Local GAN (Recon-GLGAN) for MRI reconstruction. The proposed model contains a generator and a context discriminator which incorporates global and local contextual information from images. Our model offers significant performance improvement over the baseline models. Our experiments show that the concept of a context discriminator can be extended to existing GAN based reconstruction models to offer better performance. We also demonstrate that the reconstructions from the proposed method give segmentation results similar to fully sampled images.
Conv-MCD: A Plug-and-Play Multi-task Module for Medical Image Segmentation
Aug 14, 2019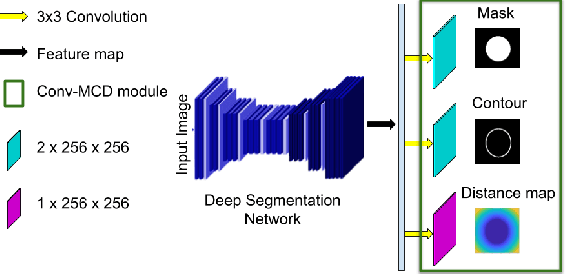
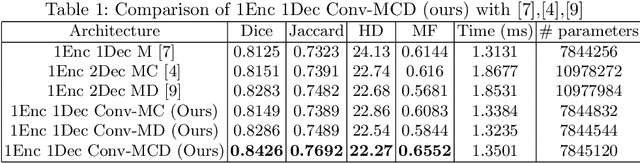

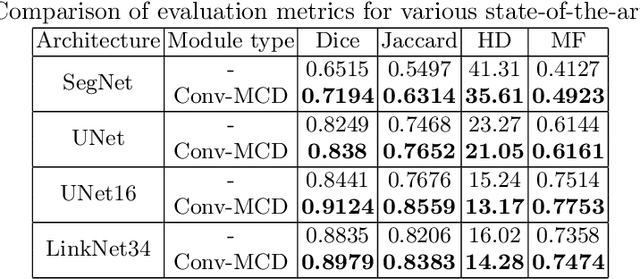
For the task of medical image segmentation, fully convolutional network (FCN) based architectures have been extensively used with various modifications. A rising trend in these architectures is to employ joint-learning of the target region with an auxiliary task, a method commonly known as multi-task learning. These approaches help impose smoothness and shape priors, which vanilla FCN approaches do not necessarily incorporate. In this paper, we propose a novel plug-and-play module, which we term as Conv-MCD, which exploits structural information in two ways - i) using the contour map and ii) using the distance map, both of which can be obtained from ground truth segmentation maps with no additional annotation costs. The key benefit of our module is the ease of its addition to any state-of-the-art architecture, resulting in a significant improvement in performance with a minimal increase in parameters. To substantiate the above claim, we conduct extensive experiments using 4 state-of-the-art architectures across various evaluation metrics, and report a significant increase in performance in relation to the base networks. In addition to the aforementioned experiments, we also perform ablative studies and visualization of feature maps to further elucidate our approach.
Psi-Net: Shape and boundary aware joint multi-task deep network for medical image segmentation
Feb 18, 2019
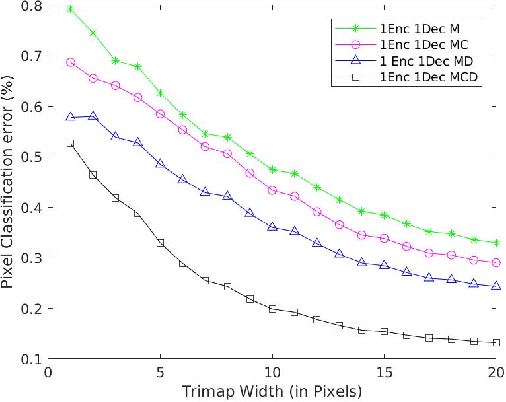


Image segmentation is a primary task in many medical applications. Recently, many deep networks derived from U-Net have been extensively used in various medical image segmentation tasks. However, in most of the cases, networks similar to U-net produce coarse and non-smooth segmentations with lots of discontinuities. To improve and refine the performance of U-Net like networks, we propose the use of parallel decoders which along with performing the mask predictions also perform contour prediction and distance map estimation. The contour and distance map aid in ensuring smoothness in the segmentation predictions. To facilitate joint training of three tasks, we propose a novel architecture called Psi-Net with a single encoder and three parallel decoders (thus having a shape of $\Psi$), one decoder to learns the segmentation mask prediction and other two decoders to learn the auxiliary tasks of contour detection and distance map estimation. The learning of these auxiliary tasks helps in capturing the shape and the boundary information. We also propose a new joint loss function for the proposed architecture. The loss function consists of a weighted combination of Negative Log likelihood and Mean Square Error loss. We have used two publicly available datasets: 1) Origa dataset for the task of optic cup and disc segmentation and 2) Endovis segment dataset for the task of polyp segmentation to evaluate our model. We have conducted extensive experiments using our network to show our model gives better results in terms of segmentation, boundary and shape metrics.
Joint shape learning and segmentation for medical images using a minimalistic deep network
Jan 25, 2019

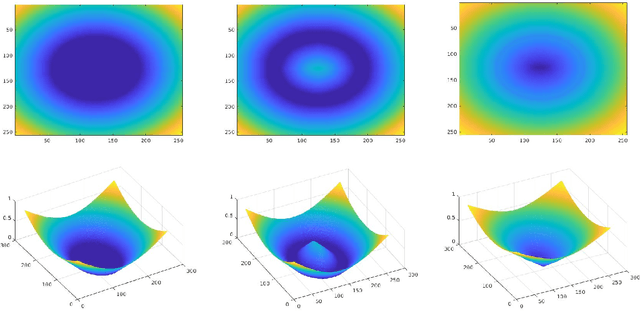
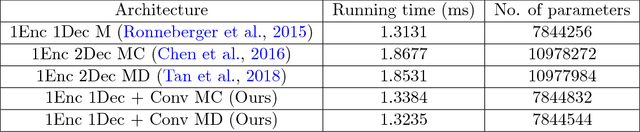
Recently, state-of-the-art results have been achieved in semantic segmentation using fully convolutional networks (FCNs). Most of these networks employ encoder-decoder style architecture similar to U-Net and are trained with images and the corresponding segmentation maps as a pixel-wise classification task. Such frameworks only exploit class information by using the ground truth segmentation maps. In this paper, we propose a multi-task learning framework with the main aim of exploiting structural and spatial information along with the class information. We modify the decoder part of the FCN to exploit class information and the structural information as well. We intend to do this while also keeping the parameters of the network as low as possible. We obtain the structural information using either of the two ways: i) using the contour map and ii) using the distance map, both of which can be obtained from ground truth segmentation maps with no additional annotation costs. We also explore different ways in which distance maps can be computed and study the effects of different distance maps on the segmentation performance. We also experiment extensively on two different medical image segmentation applications: i.e i) using color fundus images for optic disc and cup segmentation and ii) using endoscopic images for polyp segmentation. Through our experiments, we report results comparable to, and in some cases performing better than the current state-of-the-art architectures and with an order of 2x reduction in the number of parameters.