 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Attention-guided Adaptive Subsampling
Oct 14, 2025Although deep neural networks have provided impressive gains in performance, these improvements often come at the cost of increased computational complexity and expense. In many cases, such as 3D volume or video classification tasks, not all slices or frames are necessary due to inherent redundancies. To address this issue, we propose a novel learnable subsampling framework that can be integrated into any neural network architecture. Subsampling, being a nondifferentiable operation, poses significant challenges for direct adaptation into deep learning models. While some works, have proposed solutions using the Gumbel-max trick to overcome the problem of non-differentiability, they fall short in a crucial aspect: they are only task-adaptive and not inputadaptive. Once the sampling mechanism is learned, it remains static and does not adjust to different inputs, making it unsuitable for real-world applications. To this end, we propose an attention-guided sampling module that adapts to inputs even during inference. This dynamic adaptation results in performance gains and reduces complexity in deep neural network models. We demonstrate the effectiveness of our method on 3D medical imaging datasets from MedMNIST3D as well as two ultrasound video datasets for classification tasks, one of them being a challenging in-house dataset collected under real-world clinical conditions.
Model Uncertainty based Active Learning on Tabular Data using Boosted Trees
Oct 30, 2023Supervised machine learning relies on the availability of good labelled data for model training. Labelled data is acquired by human annotation, which is a cumbersome and costly process, often requiring subject matter experts. Active learning is a sub-field of machine learning which helps in obtaining the labelled data efficiently by selecting the most valuable data instances for model training and querying the labels only for those instances from the human annotator. Recently, a lot of research has been done in the field of active learning, especially for deep neural network based models. Although deep learning shines when dealing with image\textual\multimodal data, gradient boosting methods still tend to achieve much better results on tabular data. In this work, we explore active learning for tabular data using boosted trees. Uncertainty based sampling in active learning is the most commonly used querying strategy, wherein the labels of those instances are sequentially queried for which the current model prediction is maximally uncertain. Entropy is often the choice for measuring uncertainty. However, entropy is not exactly a measure of model uncertainty. Although there has been a lot of work in deep learning for measuring model uncertainty and employing it in active learning, it is yet to be explored for non-neural network models. To this end, we explore the effectiveness of boosted trees based model uncertainty methods in active learning. Leveraging this model uncertainty, we propose an uncertainty based sampling in active learning for regression tasks on tabular data. Additionally, we also propose a novel cost-effective active learning method for regression tasks along with an improved cost-effective active learning method for classification tasks.
ADAM Challenge: Detecting Age-related Macular Degeneration from Fundus Images
Feb 18, 2022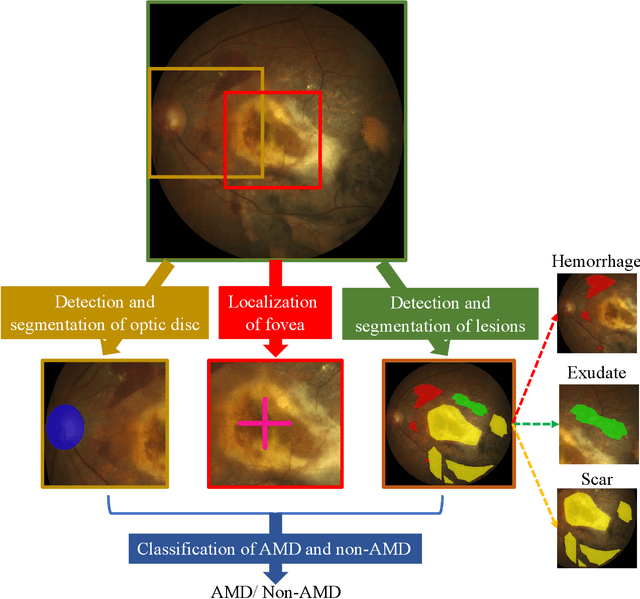

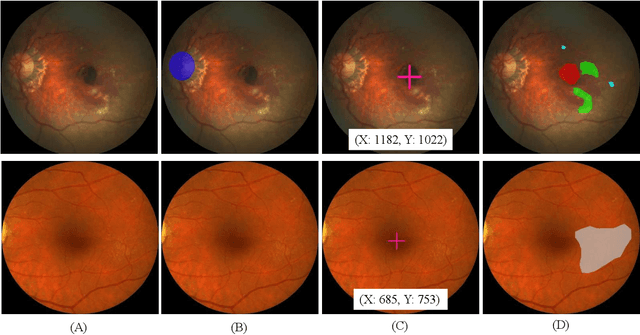
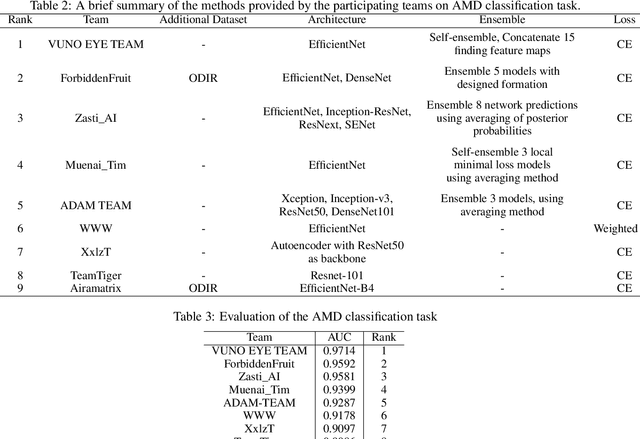
Age-related macular degeneration (AMD) is the leading cause of visual impairment among elderly in the world. Early detection of AMD is of great importance as the vision loss caused by AMD is irreversible and permanent. Color fundus photography is the most cost-effective imaging modality to screen for retinal disorders. \textcolor{red}{Recently, some algorithms based on deep learning had been developed for fundus image analysis and automatic AMD detection. However, a comprehensive annotated dataset and a standard evaluation benchmark are still missing.} To deal with this issue, we set up the Automatic Detection challenge on Age-related Macular degeneration (ADAM) for the first time, held as a satellite event of the ISBI 2020 conference. The ADAM challenge consisted of four tasks which cover the main topics in detecting AMD from fundus images, including classification of AMD, detection and segmentation of optic disc, localization of fovea, and detection and segmentation of lesions. The ADAM challenge has released a comprehensive dataset of 1200 fundus images with the category labels of AMD, the pixel-wise segmentation masks of the full optic disc and lesions (drusen, exudate, hemorrhage, scar, and other), as well as the location coordinates of the macular fovea. A uniform evaluation framework has been built to make a fair comparison of different models. During the ADAM challenge, 610 results were submitted for online evaluation, and finally, 11 teams participated in the onsite challenge. This paper introduces the challenge, dataset, and evaluation methods, as well as summarizes the methods and analyzes the results of the participating teams of each task. In particular, we observed that ensembling strategy and clinical prior knowledge can better improve the performances of the deep learning models.
Attention Augmented Convolutional Transformer for Tabular Time-series
Oct 05, 2021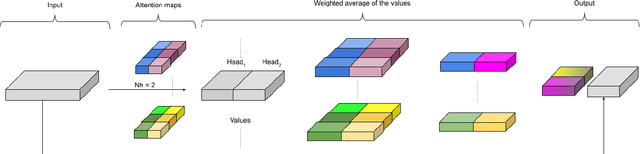
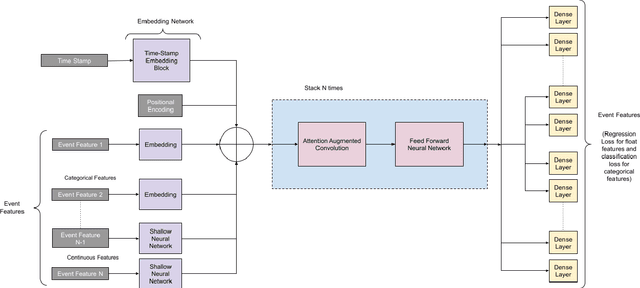
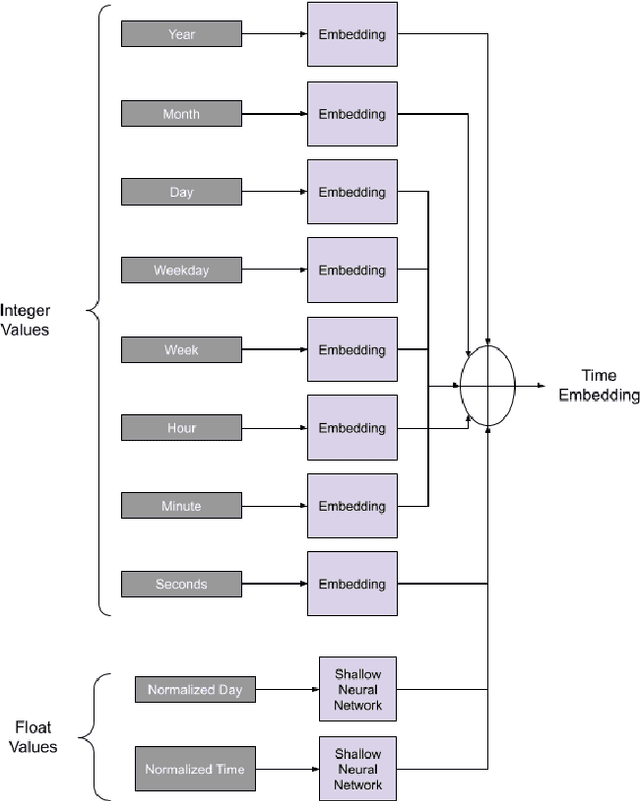
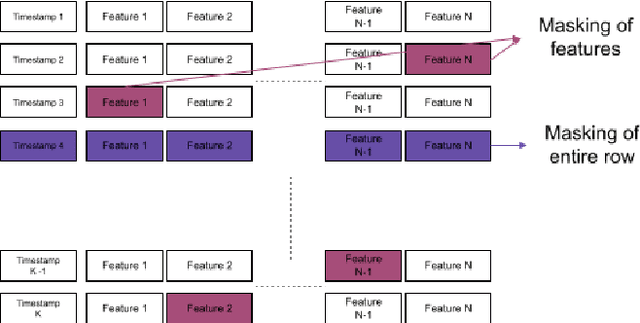
Time-series classification is one of the most frequently performed tasks in industrial data science, and one of the most widely used data representation in the industrial setting is tabular representation. In this work, we propose a novel scalable architecture for learning representations from tabular time-series data and subsequently performing downstream tasks such as time-series classification. The representation learning framework is end-to-end, akin to bidirectional encoder representations from transformers (BERT) in language modeling, however, we introduce novel masking technique suitable for pretraining of time-series data. Additionally, we also use one-dimensional convolutions augmented with transformers and explore their effectiveness, since the time-series datasets lend themselves naturally for one-dimensional convolutions. We also propose a novel timestamp embedding technique, which helps in handling both periodic cycles at different time granularity levels, and aperiodic trends present in the time-series data. Our proposed model is end-to-end and can handle both categorical and continuous valued inputs, and does not require any quantization or encoding of continuous features.
Fundus Image Analysis for Age Related Macular Degeneration: ADAM-2020 Challenge Report
Sep 03, 2020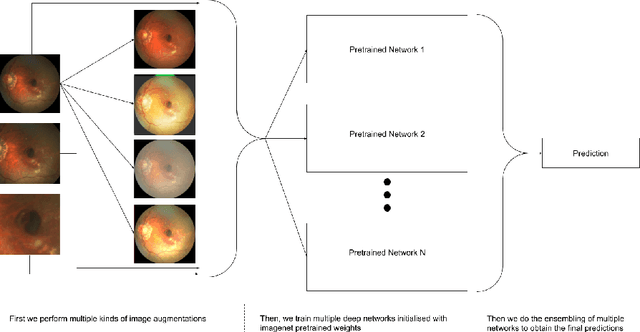
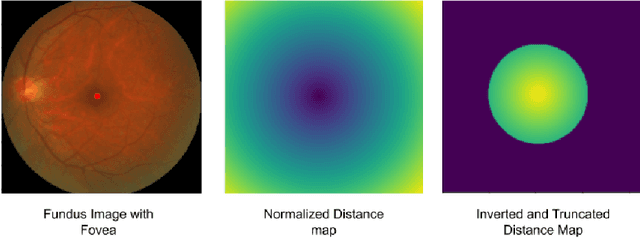
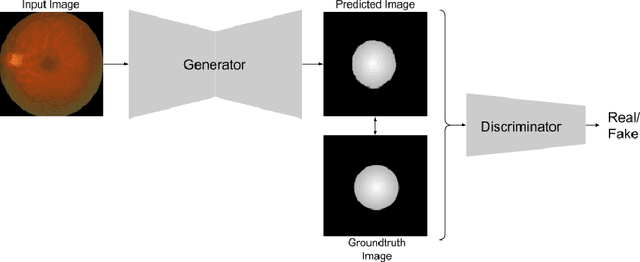
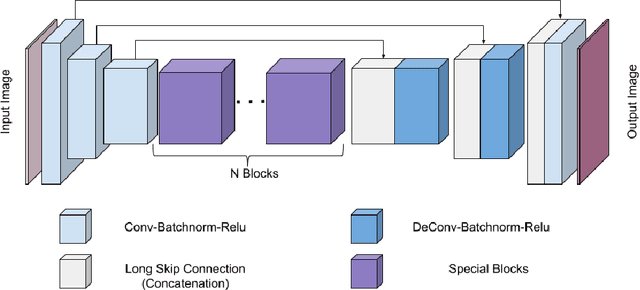
Age related macular degeneration (AMD) is one of the major causes for blindness in the elderly population. In this report, we propose deep learning based methods for retinal analysis using color fundus images for computer aided diagnosis of AMD. We leverage the recent state of the art deep networks for building a single fundus image based AMD classification pipeline. We also propose methods for the other directly relevant and auxiliary tasks such as lesions detection and segmentation, fovea detection and optic disc segmentation. We propose the use of generative adversarial networks (GANs) for the tasks of segmentation and detection. We also propose a novel method of fovea detection using GANs.
Monocular Retinal Depth Estimation and Joint Optic Disc and Cup Segmentation using Adversarial Networks
Jul 15, 2020
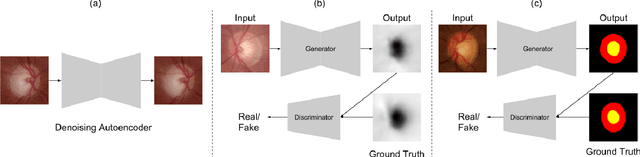
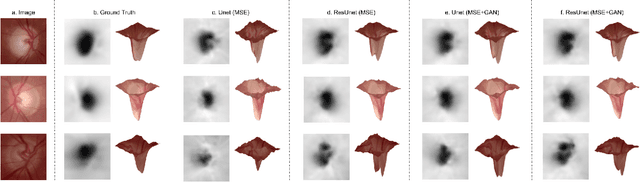

One of the important parameters for the assessment of glaucoma is optic nerve head (ONH) evaluation, which usually involves depth estimation and subsequent optic disc and cup boundary extraction. Depth is usually obtained explicitly from imaging modalities like optical coherence tomography (OCT) and is very challenging to estimate depth from a single RGB image. To this end, we propose a novel method using adversarial network to predict depth map from a single image. The proposed depth estimation technique is trained and evaluated using individual retinal images from INSPIRE-stereo dataset. We obtain a very high average correlation coefficient of 0.92 upon five fold cross validation outperforming the state of the art. We then use the depth estimation process as a proxy task for joint optic disc and cup segmentation.
A context based deep learning approach for unbalanced medical image segmentation
Jan 08, 2020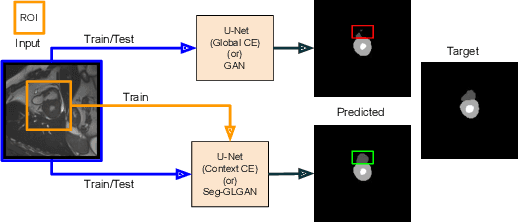
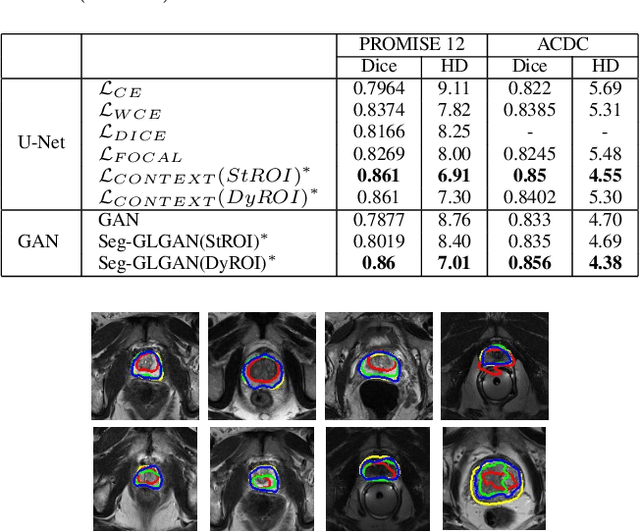
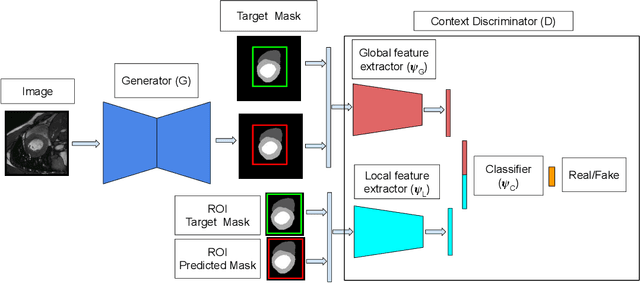

Automated medical image segmentation is an important step in many medical procedures. Recently, deep learning networks have been widely used for various medical image segmentation tasks, with U-Net and generative adversarial nets (GANs) being some of the commonly used ones. Foreground-background class imbalance is a common occurrence in medical images, and U-Net has difficulty in handling class imbalance because of its cross entropy (CE) objective function. Similarly, GAN also suffers from class imbalance because the discriminator looks at the entire image to classify it as real or fake. Since the discriminator is essentially a deep learning classifier, it is incapable of correctly identifying minor changes in small structures. To address these issues, we propose a novel context based CE loss function for U-Net, and a novel architecture Seg-GLGAN. The context based CE is a linear combination of CE obtained over the entire image and its region of interest (ROI). In Seg-GLGAN, we introduce a novel context discriminator to which the entire image and its ROI are fed as input, thus enforcing local context. We conduct extensive experiments using two challenging unbalanced datasets: PROMISE12 and ACDC. We observe that segmentation results obtained from our methods give better segmentation metrics as compared to various baseline methods.
Conv-MCD: A Plug-and-Play Multi-task Module for Medical Image Segmentation
Aug 14, 2019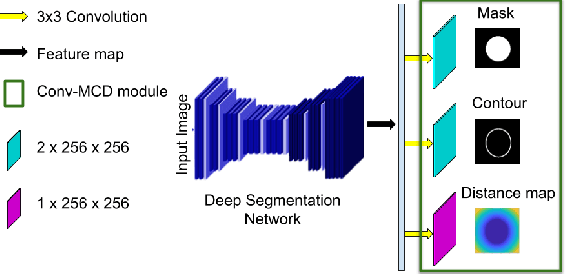
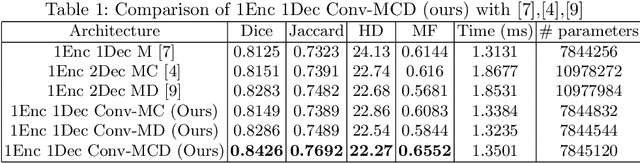

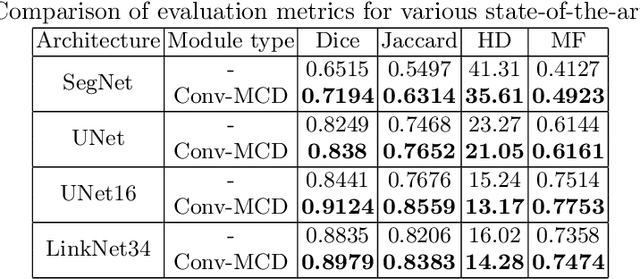
For the task of medical image segmentation, fully convolutional network (FCN) based architectures have been extensively used with various modifications. A rising trend in these architectures is to employ joint-learning of the target region with an auxiliary task, a method commonly known as multi-task learning. These approaches help impose smoothness and shape priors, which vanilla FCN approaches do not necessarily incorporate. In this paper, we propose a novel plug-and-play module, which we term as Conv-MCD, which exploits structural information in two ways - i) using the contour map and ii) using the distance map, both of which can be obtained from ground truth segmentation maps with no additional annotation costs. The key benefit of our module is the ease of its addition to any state-of-the-art architecture, resulting in a significant improvement in performance with a minimal increase in parameters. To substantiate the above claim, we conduct extensive experiments using 4 state-of-the-art architectures across various evaluation metrics, and report a significant increase in performance in relation to the base networks. In addition to the aforementioned experiments, we also perform ablative studies and visualization of feature maps to further elucidate our approach.
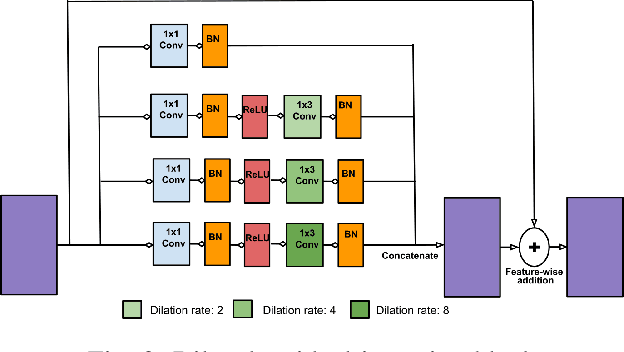
Deep Network for Capacitive ECG Denoising
Mar 29, 2019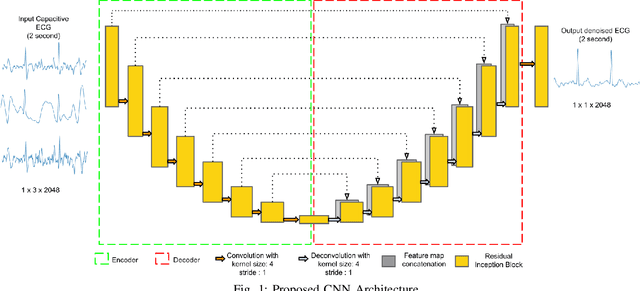
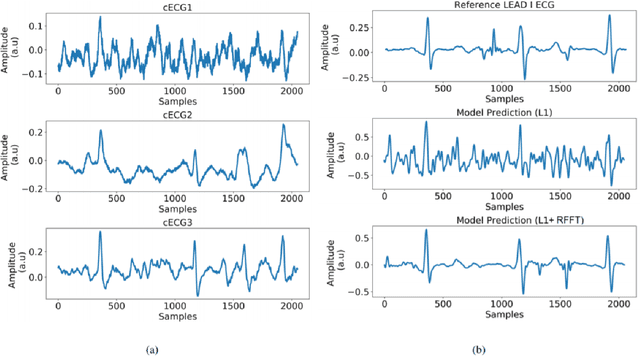
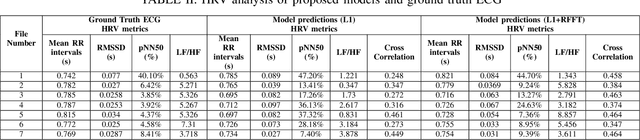

Continuous monitoring of cardiac health under free living condition is crucial to provide effective care for patients undergoing post operative recovery and individuals with high cardiac risk like the elderly. Capacitive Electrocardiogram (cECG) is one such technology which allows comfortable and long term monitoring through its ability to measure biopotential in conditions without having skin contact. cECG monitoring can be done using many household objects like chairs, beds and even car seats allowing for seamless monitoring of individuals. This method is unfortunately highly susceptible to motion artifacts which greatly limits its usage in clinical practice. The current use of cECG systems has been limited to performing rhythmic analysis. In this paper we propose a novel end-to-end deep learning architecture to perform the task of denoising capacitive ECG. The proposed network is trained using motion corrupted three channel cECG and a reference LEAD I ECG collected on individuals while driving a car. Further, we also propose a novel joint loss function to apply loss on both signal and frequency domain. We conduct extensive rhythmic analysis on the model predictions and the ground truth. We further evaluate the signal denoising using Mean Square Error(MSE) and Cross Correlation between model predictions and ground truth. We report MSE of 0.167 and Cross Correlation of 0.476. The reported results highlight the feasibility of performing morphological analysis using the filtered cECG. The proposed approach can allow for continuous and comprehensive monitoring of the individuals in free living conditions.
RespNet: A deep learning model for extraction of respiration from photoplethysmogram
Feb 20, 2019
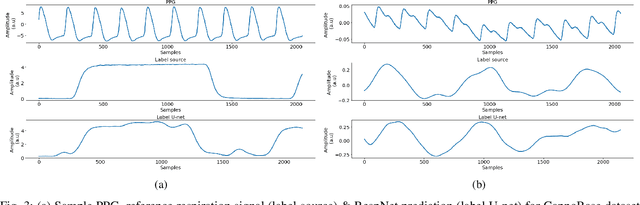

Respiratory ailments afflict a wide range of people and manifests itself through conditions like asthma and sleep apnea. Continuous monitoring of chronic respiratory ailments is seldom used outside the intensive care ward due to the large size and cost of the monitoring system. While Electrocardiogram (ECG) based respiration extraction is a validated approach, its adoption is limited by access to a suitable continuous ECG monitor. Recently, due to the widespread adoption of wearable smartwatches with in-built Photoplethysmogram (PPG) sensor, it is being considered as a viable candidate for continuous and unobtrusive respiration monitoring. Research in this domain, however, has been predominantly focussed on estimating respiration rate from PPG. In this work, a novel end-to-end deep learning network called RespNet is proposed to perform the task of extracting the respiration signal from a given input PPG as opposed to extracting respiration rate. The proposed network was trained and tested on two different datasets utilizing different modalities of reference respiration signal recordings. Also, the similarity and performance of the proposed network against two conventional signal processing approaches for extracting respiration signal were studied. The proposed method was tested on two independent datasets with a Mean Squared Error of 0.262 and 0.145. The Cross-Correlation coefficient of the respective datasets were found to be 0.933 and 0.931. The reported errors and similarity was found to be better than conventional approaches. The proposed approach would aid clinicians to provide comprehensive evaluation of sleep-related respiratory conditions and chronic respiratory ailments while being comfortable and inexpensive for the patient.