 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Prompt Leakage Attacks on Large Language Models Using Agentic Approach
Feb 18, 2025This paper presents a novel approach to evaluating the security of large language models (LLMs) against prompt leakage-the exposure of system-level prompts or proprietary configurations. We define prompt leakage as a critical threat to secure LLM deployment and introduce a framework for testing the robustness of LLMs using agentic teams. Leveraging AG2 (formerly AutoGen), we implement a multi-agent system where cooperative agents are tasked with probing and exploiting the target LLM to elicit its prompt. Guided by traditional definitions of security in cryptography, we further define a prompt leakage-safe system as one in which an attacker cannot distinguish between two agents: one initialized with an original prompt and the other with a prompt stripped of all sensitive information. In a safe system, the agents' outputs will be indistinguishable to the attacker, ensuring that sensitive information remains secure. This cryptographically inspired framework provides a rigorous standard for evaluating and designing secure LLMs. This work establishes a systematic methodology for adversarial testing of prompt leakage, bridging the gap between automated threat modeling and practical LLM security. You can find the implementation of our prompt leakage probing on GitHub.
Constrained Monotonic Neural Networks
May 24, 2022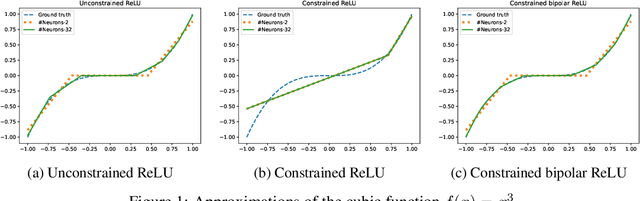
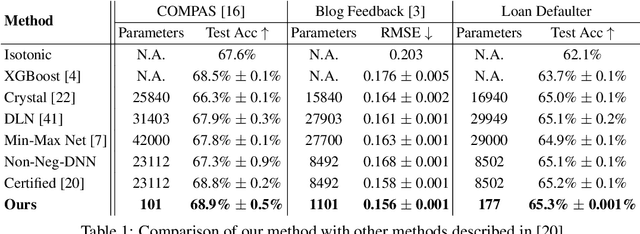
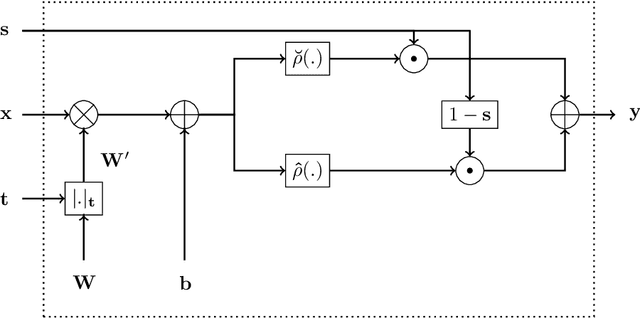
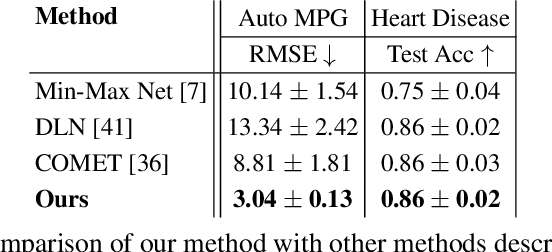
Deep neural networks are becoming increasingly popular in approximating arbitrary functions from noisy data. But wider adoption is being hindered by the need to explain such models and to impose additional constraints on them. Monotonicity constraint is one of the most requested properties in real-world scenarios and is the focus of this paper. One of the oldest ways to construct a monotonic fully connected neural network is to constrain its weights to be non-negative while employing a monotonic activation function. Unfortunately, this construction does not work with popular non-saturated activation functions such as ReLU, ELU, SELU etc, as it can only approximate convex functions. We show this shortcoming can be fixed by employing the original activation function for a part of the neurons in the layer, and employing its point reflection for the other part. Our experiments show this approach of building monotonic deep neural networks have matching or better accuracy when compared to other state-of-the-art methods such as deep lattice networks or monotonic networks obtained by heuristic regularization. This method is the simplest one in the sense of having the least number of parameters, not requiring any modifications to the learning procedure or steps post-learning steps.
Attention Augmented Convolutional Transformer for Tabular Time-series
Oct 05, 2021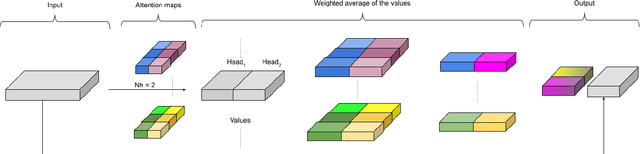
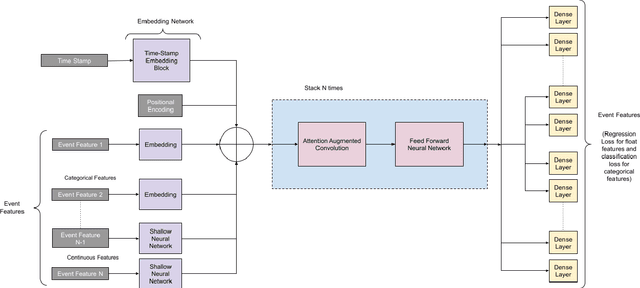
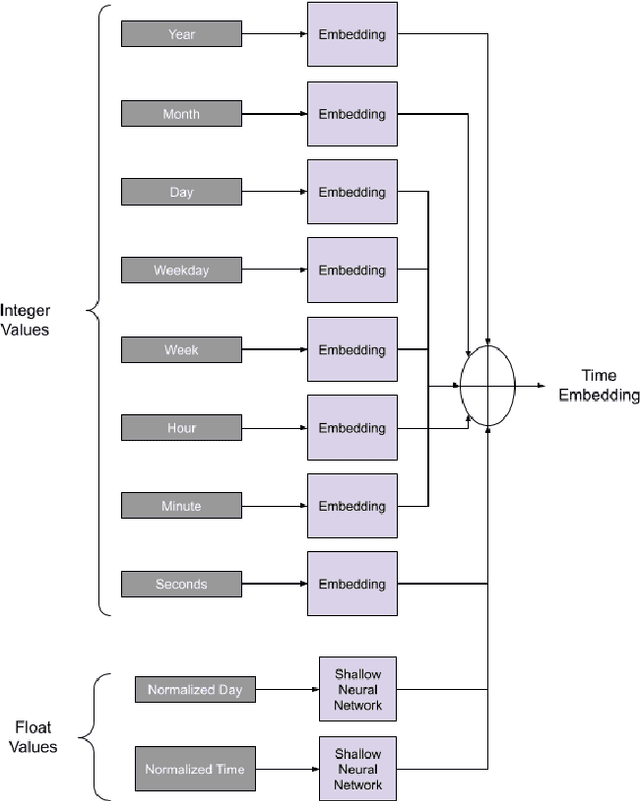
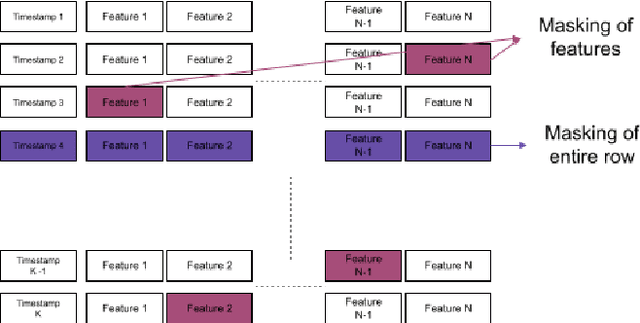
Time-series classification is one of the most frequently performed tasks in industrial data science, and one of the most widely used data representation in the industrial setting is tabular representation. In this work, we propose a novel scalable architecture for learning representations from tabular time-series data and subsequently performing downstream tasks such as time-series classification. The representation learning framework is end-to-end, akin to bidirectional encoder representations from transformers (BERT) in language modeling, however, we introduce novel masking technique suitable for pretraining of time-series data. Additionally, we also use one-dimensional convolutions augmented with transformers and explore their effectiveness, since the time-series datasets lend themselves naturally for one-dimensional convolutions. We also propose a novel timestamp embedding technique, which helps in handling both periodic cycles at different time granularity levels, and aperiodic trends present in the time-series data. Our proposed model is end-to-end and can handle both categorical and continuous valued inputs, and does not require any quantization or encoding of continuous features.
ALIME: Autoencoder Based Approach for Local Interpretability
Sep 04, 2019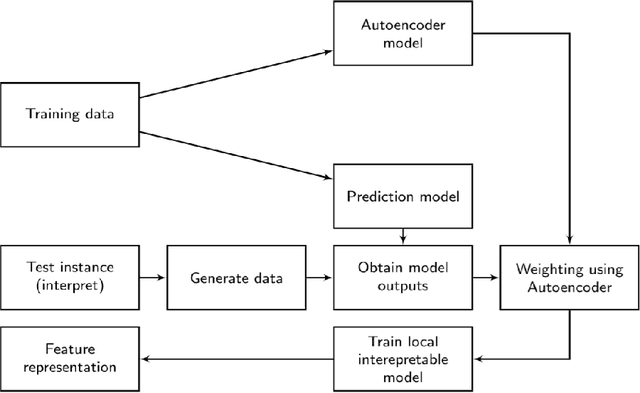
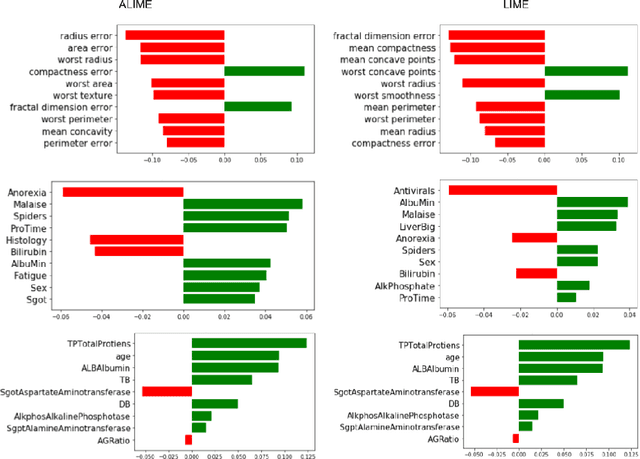
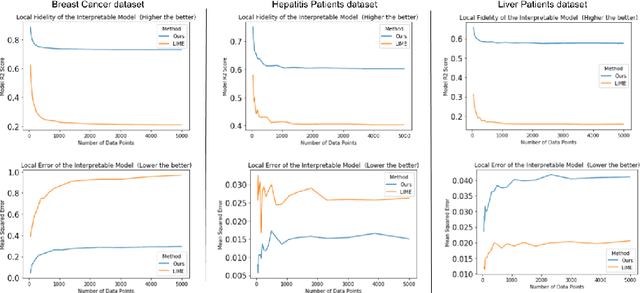
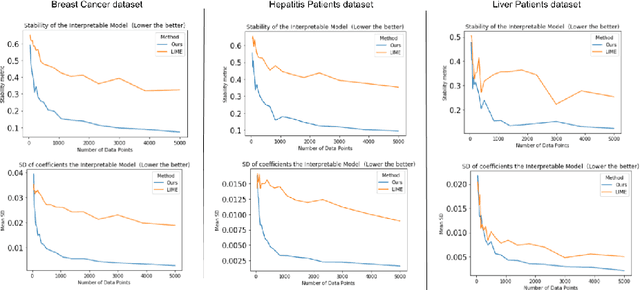
Machine learning and especially deep learning have garneredtremendous popularity in recent years due to their increased performanceover other methods. The availability of large amount of data has aidedin the progress of deep learning. Nevertheless, deep learning models areopaque and often seen as black boxes. Thus, there is an inherent need tomake the models interpretable, especially so in the medical domain. Inthis work, we propose a locally interpretable method, which is inspiredby one of the recent tools that has gained a lot of interest, called localinterpretable model-agnostic explanations (LIME). LIME generates singleinstance level explanation by artificially generating a dataset aroundthe instance (by randomly sampling and using perturbations) and thentraining a local linear interpretable model. One of the major issues inLIME is the instability in the generated explanation, which is caused dueto the randomly generated dataset. Another issue in these kind of localinterpretable models is the local fidelity. We propose novel modificationsto LIME by employing an autoencoder, which serves as a better weightingfunction for the local model. We perform extensive comparisons withdifferent datasets and show that our proposed method results in bothimproved stability, as well as local fidelity.